
Cerebras Systems, a pioneer in high-performance AI compute, has launched a groundbreaking answer that’s set to revolutionize AI inference. On August 27, 2024, the corporate introduced the launch of Cerebras Inference, the quickest AI inference service on this planet. With efficiency metrics that dwarf these of conventional GPU-based programs, Cerebras Inference delivers 20 instances the pace at a fraction of the price, setting a brand new benchmark in AI computing.
Unprecedented Velocity and Price Effectivity
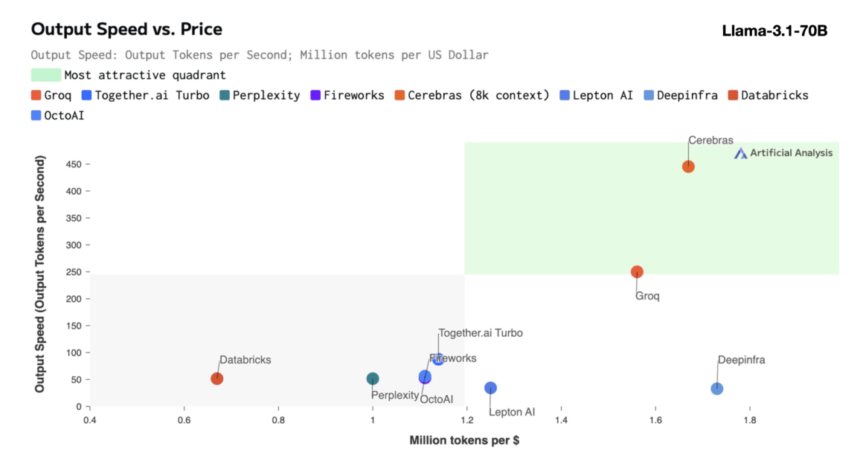
Cerebras Inference is designed to ship distinctive efficiency throughout varied AI fashions, notably within the quickly evolving section of enormous language fashions (LLMs). As an illustration, it processes 1,800 tokens per second for the Llama 3.1 8B mannequin and 450 tokens per second for the Llama 3.1 70B mannequin. This efficiency isn’t solely 20 instances sooner than that of NVIDIA GPU-based options but in addition comes at a considerably decrease price. Cerebras provides this service beginning at simply 10 cents per million tokens for the Llama 3.1 8B mannequin and 60 cents per million tokens for the Llama 3.1 70B mannequin, representing a 100x enchancment in price-performance in comparison with present GPU-based choices.
Sustaining Accuracy Whereas Pushing the Boundaries of Velocity
Probably the most spectacular features of Cerebras Inference is its capability to take care of state-of-the-art accuracy whereas delivering unmatched pace. Not like different approaches that sacrifice precision for pace, Cerebras’ answer stays inside the 16-bit area for everything of the inference run. This ensures that the efficiency positive aspects don’t come on the expense of the standard of AI mannequin outputs, a vital issue for builders centered on precision.
Micah Hill-Smith, Co-Founder and CEO of Synthetic Evaluation, highlighted the importance of this achievement: “Cerebras is delivering speeds an order of magnitude sooner than GPU-based options for Meta’s Llama 3.1 8B and 70B AI fashions. We’re measuring speeds above 1,800 output tokens per second on Llama 3.1 8B, and above 446 output tokens per second on Llama 3.1 70B – a brand new file in these benchmarks.”
The Rising Significance of AI Inference
AI inference is the fastest-growing section of AI compute, accounting for roughly 40% of the entire AI {hardware} market. The arrival of high-speed AI inference, comparable to that supplied by Cerebras, is akin to the introduction of broadband web—unlocking new alternatives and heralding a brand new period for AI functions. With Cerebras Inference, builders can now construct next-generation AI functions that require advanced, real-time efficiency, comparable to AI brokers and clever programs.
Andrew Ng, Founding father of DeepLearning.AI, underscored the significance of pace in AI improvement: “DeepLearning.AI has a number of agentic workflows that require prompting an LLM repeatedly to get a outcome. Cerebras has constructed an impressively quick inference functionality which will probably be very useful to such workloads.”

Broad Business Help and Strategic Partnerships
Cerebras has garnered sturdy help from {industry} leaders and has fashioned strategic partnerships to speed up the event of AI functions. Kim Branson, SVP of AI/ML at GlaxoSmithKline, an early Cerebras buyer, emphasised the transformative potential of this know-how: “Velocity and scale change every part.”
Different firms, comparable to LiveKit, Perplexity, and Meter, have additionally expressed enthusiasm for the influence that Cerebras Inference could have on their operations. These firms are leveraging the facility of Cerebras’ compute capabilities to create extra responsive, human-like AI experiences, enhance person interplay in serps, and improve community administration programs.
Cerebras Inference: Tiers and Accessibility
Cerebras Inference is out there throughout three competitively priced tiers: Free, Developer, and Enterprise. The Free Tier supplies free API entry with beneficiant utilization limits, making it accessible to a broad vary of customers. The Developer Tier provides a versatile, serverless deployment possibility, with Llama 3.1 fashions priced at 10 cents and 60 cents per million tokens. The Enterprise Tier caters to organizations with sustained workloads, providing fine-tuned fashions, customized service stage agreements, and devoted help, with pricing obtainable upon request.
Powering Cerebras Inference: The Wafer Scale Engine 3 (WSE-3)
On the coronary heart of Cerebras Inference is the Cerebras CS-3 system, powered by the industry-leading Wafer Scale Engine 3 (WSE-3). This AI processor is unmatched in its dimension and pace, providing 7,000 instances extra reminiscence bandwidth than NVIDIA’s H100. The WSE-3’s huge scale allows it to deal with many concurrent customers, guaranteeing blistering speeds with out compromising on efficiency. This structure permits Cerebras to sidestep the trade-offs that usually plague GPU-based programs, offering best-in-class efficiency for AI workloads.
Seamless Integration and Developer-Pleasant API
Cerebras Inference is designed with builders in thoughts. It options an API that’s absolutely appropriate with the OpenAI Chat Completions API, permitting for straightforward migration with minimal code modifications. This developer-friendly strategy ensures that integrating Cerebras Inference into present workflows is as seamless as attainable, enabling fast deployment of high-performance AI functions.
Cerebras Methods: Driving Innovation Throughout Industries
Cerebras Methods isn’t just a pacesetter in AI computing but in addition a key participant throughout varied industries, together with healthcare, vitality, authorities, scientific computing, and monetary companies. The corporate’s options have been instrumental in driving breakthroughs at establishments such because the Nationwide Laboratories, Aleph Alpha, The Mayo Clinic, and GlaxoSmithKline.
By offering unmatched pace, scalability, and accuracy, Cerebras is enabling organizations throughout these sectors to deal with a number of the most difficult issues in AI and past. Whether or not it’s accelerating drug discovery in healthcare or enhancing computational capabilities in scientific analysis, Cerebras is on the forefront of driving innovation.
Conclusion: A New Period for AI Inference
Cerebras Methods is setting a brand new normal for AI inference with the launch of Cerebras Inference. By providing 20 instances the pace of conventional GPU-based programs at a fraction of the price, Cerebras isn’t solely making AI extra accessible but in addition paving the best way for the subsequent technology of AI functions. With its cutting-edge know-how, strategic partnerships, and dedication to innovation, Cerebras is poised to guide the AI {industry} into a brand new period of unprecedented efficiency and scalability.
For extra data on Cerebras Methods and to strive Cerebras Inference, go to www.cerebras.ai.

