

Do you know that correctly making ready your information can enhance your mannequin’s efficiency?
Methods like normalization and standardization assist scale information appropriately, main to raised outcomes and simpler interpretation.
Need to know the distinction between these two strategies? Maintain studying we’ll clarify it in a easy manner! However first, let’s shortly perceive why information preprocessing is vital in machine studying.
Knowledge preprocessing in Machine Studying
In Machine Studying, you possibly can describe Knowledge preprocessing as the method of making ready uncooked information for ML algorithms. It requires information preprocessing steps reminiscent of Knowledge cleansing (Fixing incorrect or incomplete information), Knowledge discount (Eradicating redundant or irrelevant information), and Knowledge transformation (Changing information to a most popular format).
This course of is an important a part of ML as a result of it immediately influences the efficiency and precision of the fashions. One of many widespread information preprocessing steps in machine studying is Knowledge scaling, which is the method of modifying the vary of knowledge values with out altering the info itself.
Scaling information is vital earlier than utilizing it for ML algorithms as a result of it ensures options have a comparable vary, stopping these with bigger values from dominating the training course of.
By utilizing this strategy, you possibly can enhance mannequin efficiency and get quicker convergence and higher interpretability. ML can detect any vulnerabilities or weaknesses in encryption strategies, guaranteeing they Keep data secure.
Definitions and Ideas
Knowledge Normalization
In machine studying, information normalization transforms information options to a constant vary( 0 to 1) or a normal regular distribution to stop options with bigger scales from dominating the training course of.
Additionally it is generally known as characteristic scaling, and its major purpose is to make the options comparable. It additionally improves the efficiency of ML fashions, particularly these delicate to characteristic scaling.
Normalization strategies are used to rescale information values into the same vary, which you’ll obtain utilizing strategies like min-max scaling (rescaling to a 0-1 vary) or standardization (remodeling to a zero-mean, unit-variance distribution). In ML, information normalization, min-max scaling transforms options to a specified vary utilizing the components given below-
System: X_normalized = (X – X_min) / (X_max – X_min).
The place:
X is the unique characteristic worth.
X_min is the min worth of the characteristic within the dataset.
X_max is the max worth of the characteristic within the dataset.
X_normalized is the normalized or scaled worth.

For instance, think about you have got a dataset with two options: “Room” (starting from 1 to six) and “Age” (starting from 1 to 40). With out normalization, the “Age” characteristic would probably dominate the “Room” characteristic in calculations, as its values are bigger. Let’s take a random worth from the above information set to see how normalization works- Room= 2, Age= 30
Earlier than Normalization:
As you possibly can see, the scatter plot exhibits “Age” values unfold rather more expansively than “Room” values earlier than normalization, making it troublesome to search out any patterns between them.

After Normalization:
Utilizing the normalization components X_normalized = (X – X_min) / (X_max – X_min), we get-
Room2_normalized = (2-1)/(6-1 )= 3/5 = 0.6
Age30_normalized = (30-1)/(40-1) = 29/39 = 0.74
0.6 and 0.74 are new normalized values that fall throughout the vary of 0-1. If carry out normalized on all of the characteristic values and plotted them we are going to get a distribution identical to the below-

Now, this scatter plot exhibits “Room” and “Age” values scaled to the 0 to 1 vary. This lets you discover a a lot clearer comparability of their relationships.
Knowledge Standardization
Knowledge standardization is called Z-score normalization. It’s one other information preprocessing method in ML that scales options to have a imply of 0 and a normal deviation of 1. This system ensures all options are on a comparable scale.
This system helps ML algorithms, particularly these delicate to characteristic scaling like k-NN, SVM, and linear regression, to carry out higher. Moreover, it prevents options with bigger scales from dominating the mannequin’s output and makes the info extra Gaussian-like, which is helpful for some algorithms.
Standardization transforms the info by subtracting the imply of every characteristic and dividing it by its normal deviation. Its components is given below-
System: X’ = (X – Imply(X)) / Std(X)
The place:
X is the unique characteristic worth.
X’ is the standardized characteristic worth.
Imply(X) is the imply of the characteristic.
Std(X) is the usual deviation of X.
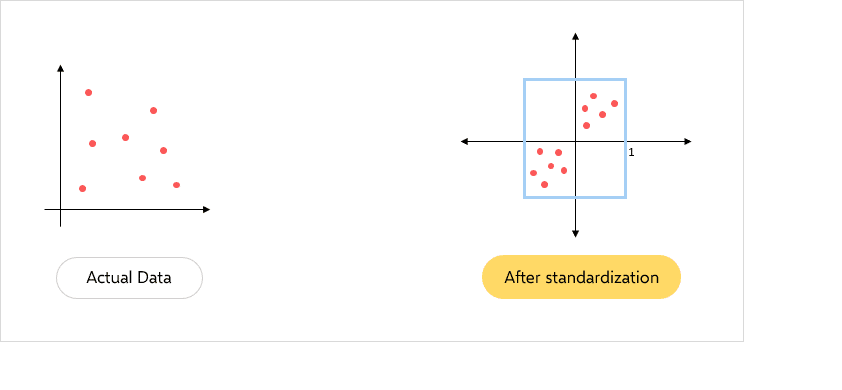
For instance, here’s a dataset with giant characteristic values: “Wage” (starting from 0 to 140000) and “Age” (starting from 0 to 60). Right here, you possibly can see that with out standardization, the “Wage” characteristic would probably dominate the “Age” characteristic in calculations on account of bigger characteristic values.
To grasp it clearly, let’s assume a random worth from the above information set to see how standardization works-
Earlier than standardization
Let’s say a characteristic has values:
Wage= 100000, 115000, 123000, 133000, 140000
Age= 20, 23, 30, 38, 55
After standardization
Utilizing components X' = (X - Imply(X)) / Std(X)
Wage= 100000, 115000, 123000, 133000, 140000
Imply(X) = 122200
Commonplace Deviation Std(X) = 15642.89 (roughly)
Standardized values:
Wage X'= (100000 - 122200) / 15642.89 = -1.41
(115000 - 122200) / 15642.89 = -0.46
(123000 - 122200) / 15642.89 = 0.05
(133000 - 122200) / 15642.89 = 0.69
(140000 - 122200) / 15642.89 = 1.13
Equally
Age X'=-0.94, -0.73, -0.22, 0.34, 1.55

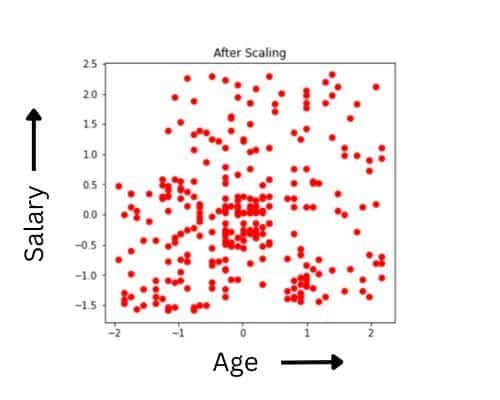
Earlier than and after the normalization, each the plots would be the similar. The one distinction is within the X and Y scales. After normalization, the imply has shifted in the direction of the origin.
Key Variations
| Parameter | Normalization | Standardization |
| Definition | Transforms information options to a constant vary 0 to 1 | Scales characteristic to have a imply of 0 and a normal deviation of 1 |
| Function | To vary the size of the options in order that they match inside a particular vary for straightforward characteristic comparability. | To vary the distribution of the options to a normal regular distribution to stop options with bigger scales from dominating the mannequin’s output. |
| System | X_normalized = (X – X_min) / (X_max – X_min) | (X – Imply(X)) / Std(X) |
| Dependency on Distribution | Doesn’t have a dependency on the distribution of the info. | Assumes the distribution of knowledge is regular. |
| Sensitivity to Outliers | Much less delicate to outliers because it requires exact strategies to regulate for outliers. | Extremely delicate to outliers as min and max are influenced by excessive values, offering a constant strategy to fixing outlier issues. |
| Affect on the Form of Plot | If there are vital outliers, the plot may be modified. | Maintains the unique form of the plot however aligns it to a normal scale. |
| Use Circumstances | Helpful for ML algorithms, significantly these delicate to characteristic scales, e.g., neural networks, SVM, and k-NN. | Helpful for ML algorithms that assume information is often distributed or options have vastly completely different scales, e.g., Cluster fashions, linear regression, and logistic regression. |
Knowledge Normalization vs. Standardization: Scale and Distribution
1. Impact on Knowledge Vary:
- Normalization: As we noticed earlier, Normalization immediately modifies the vary of the info to make sure all values fall throughout the outlined boundaries. It’s preferable if you find yourself unsure concerning the actual characteristic distribution or the info distribution doesn’t match the Gaussian distribution. Thus, this method gives a dependable strategy to assist the mannequin carry out higher and extra precisely.
- Standardization: However, it doesn’t have a predefined vary, and the remodeled information can have values outdoors of the unique vary. Thus, this technique could be very efficient if the characteristic distribution of the info is understood or the info distribution matches the Gaussian distribution.
2. Impact on Distribution:
- Normalization: Normalization doesn’t inherently change the form of the distribution; it primarily focuses on scaling the info inside a particular vary.
- Standardization: Quite the opposite, Standardization primarily focuses on the distribution, centering the info round a imply of 0 and scaling it to a normal deviation of 1.
Use instances: Knowledge Normalization vs. Standardization
Eventualities and fashions that profit from normalization:

Normalization advantages a number of ML fashions, significantly these delicate to characteristic scales. For example-
- Fashions reminiscent of PCA, neural networks, and linear fashions like linear/logistic regression, SVM, and k-NN enormously profit from normalization.
- In Neural Networks, normalization is a normal observe as it might probably result in quicker convergence and higher generalization efficiency.
- Normalization additionally decreases varied results on account of scale variations of enter options because it makes the inputs extra congruous. This manner, normalizing enter for an ML mannequin improves convergence and coaching stability.
Eventualities and fashions that profit from standardization:

Numerous ML fashions in addition to these coping with information the place options have vastly completely different scales, profit considerably from information standardization. Listed below are some examples:
- Assist Vector Machine (SVM) usually requires Standardization because it maximizes the span between the help vectors and the separating airplane. Thus, Standardization is required when computing the span distance to make sure one characteristic received’t dominate one other characteristic if it assumes a big worth.
- Clustering fashions comprise algorithms that work primarily based on distance metrics. Which means options with bigger values will exert a extra vital impact on the clustering final result. Thus, it’s important to standardize the info earlier than growing a clustering mannequin.
- When you’ve got a Gaussian information distribution, standardization is more practical than different strategies. It really works greatest with a traditional distribution and advantages ML algorithms assuming a Gaussian distribution.
Benefits and Limitations
Benefits of Normalization
Normalization has varied benefits that make this method extensively common. A few of them are listed below-

- Excessive Mannequin Accuracy: Normalization helps algorithms make extra correct predictions by stopping options with bigger scales from dominating the training course of.
- Quicker Coaching: It may possibly velocity up the coaching technique of fashions and assist them converge extra shortly.
- Higher Dealing with of Outliers: It may possibly additionally scale back the influence of outliers and stop them from having an undue affect on the mannequin.
Limitations of Normalization
Normalization certainly has its benefits however it additionally carries some drawbacks that may have an effect on your mannequin efficiency.
- Lack of Info: Normalization can typically result in a lack of info, largely in instances the place the unique vary or distribution of the info is significant or essential for the evaluation. For instance, when you normalize a characteristic with a wide variety, the unique scale could be misplaced, probably making it more durable to interpret the characteristic’s contribution.
- Elevated Computational Complexity: It provides an additional step to the info preprocessing pipeline, which may improve computational time, particularly for big datasets or real-time functions.
Benefits of Standardization
Standardization additionally has its edge over different strategies in varied eventualities.

- Improved Mannequin Efficiency: Standardization ensures options are on the identical scale, thus permitting algorithms to be taught extra successfully, in the end bettering the efficiency of ML fashions.
- Simpler Comparability of Coefficients: It permits you a direct comparability of mannequin coefficients, as they’re now not influenced by completely different scales.
- Outlier Dealing with: It may possibly additionally assist mitigate the influence of outliers, as they’re much less more likely to dominate the mannequin’s output.
Limitations of Standardization
Standardization, whereas useful for a lot of machine studying duties, additionally has drawbacks. A few of its main drawbacks are listed below-
- Lack of Authentic Unit Interpretation: Standardizing information transforms values right into a standardized scale (imply of 0, normal deviation of 1), which may make it troublesome to interpret the info in its authentic context.
- Dependency on Normality Assumption: It assumes that the info follows a traditional distribution. If the info will not be usually distributed, making use of standardization may not be applicable in your mannequin and will result in deceptive outcomes.
Conclusion
Characteristic scaling is an important a part of information preprocessing in ML. A radical understanding of the acceptable method for every dataset can considerably improve the efficiency and accuracy of fashions.
For instance, normalization proves to be significantly efficient for distance-based and gradient-based algorithms. However, you need to use standardization for algorithms that embody weights and people who assume a traditional distribution. In a way, you need to choose probably the most appropriate method for the particular state of affairs at hand, as each approaches can yield vital advantages when utilized appropriately.