

Deep Reinforcement Studying is the mix of Reinforcement Studying and Deep Studying. This expertise allows machines to resolve a variety of advanced decision-making duties. Therefore, it opens up many new purposes in industries akin to healthcare, safety and surveillance, robotics, good grids, self-driving automobiles, and plenty of extra.
We’ll present an introduction to deep reinforcement studying:
- What’s Reinforcement Studying?
- Deep Studying with Reinforcement Studying
- Functions of Deep Reinforcement Studying
- Benefits and Challenges
About us: At viso, we offer the main end-to-end platform for laptop imaginative and prescient. Firms use it to implement customized, real-world laptop imaginative and prescient purposes. Learn the whitepaper or get a demo in your group!
What’s Deep Reinforcement Studying?
Reinforcement Studying Idea
Reinforcement Studying (RL) is a subfield of Synthetic Intelligence (AI) and machine studying. The Studying Methodology offers with studying from interactions with an setting to be able to maximize a cumulative reward sign.
Reinforcement Studying depends on the idea of Trial and Error. An RL agent performs a sequence of actions in an unsure setting to study from expertise by receiving suggestions (rewards and penalties) within the type of a Reward Perform to maximise reward.
With the expertise gathered, the AI agent ought to have the ability to optimize some aims given within the type of cumulative rewards. The target of the agent is to study the optimum coverage, which is a mapping between states and actions that maximizes the anticipated cumulative reward.
The Reinforcement Studying Drawback is impressed by behavioral psychology (Sutton, 1984). It led to the introduction of a proper framework to resolve decision-making duties. The idea is that an agent is ready to study by interacting with its setting, just like a organic agent.
Reinforcement Studying Strategies
Reinforcement Studying is totally different from different Studying Strategies, akin to Supervised Studying and Unsupervised Machine Studying. Aside from these, it doesn’t depend on a labeled dataset or a pre-defined algorithm. As an alternative, it makes use of trial and error to study from expertise and enhance its coverage over time.
Among the frequent Reinforcement Studying strategies are:
- Worth-Primarily based Strategies: These RL strategies estimate the worth operate, which is the anticipated cumulative reward for taking an motion in a selected state. Q-Studying and SARSA are extensively used Worth-Primarily based Strategies.
- Coverage-Primarily based Strategies: Coverage-Primarily based strategies straight study the coverage, which is a mapping between states and actions that maximizes the anticipated cumulative reward. REINFORCE and Coverage Gradient Strategies are frequent Coverage-Primarily based Strategies.
- Actor-Critic Strategies: These strategies mix each Worth-Primarily based and Coverage-Primarily based Strategies through the use of two separate networks, the Actor and the Critic. The Actor selects actions based mostly on the present state, whereas the Critic evaluates the goodness of the motion taken by the Actor by estimating the worth operate. The Actor-Critic algorithm updates the coverage utilizing the TD (Temporal Distinction) error.
- Mannequin-Primarily based Strategies: Mannequin-based strategies study the setting’s dynamics by constructing a mannequin of the setting, together with the state transition operate and the reward operate. The mannequin permits the agent to simulate the setting and discover numerous actions earlier than taking them.
- Mannequin-Free Strategies: These strategies don’t require the reinforcement studying agent to construct a mannequin of the setting. As an alternative, they study straight from the setting through the use of trial and error to enhance the coverage. TD-Studying (Temporal distinction studying), SARSA (State–motion–reward–state–motion), or Q-Studying are examples of a Mannequin-Free Strategies.
- Monte Carlo Strategies: Monte Carlo strategies observe a quite simple idea the place brokers study in regards to the states and reward once they work together with the setting. Monte Carlo Strategies can be utilized for each Worth-Primarily based and Coverage-Primarily based Strategies.
In reinforcement studying, Energetic Studying can be utilized to enhance the training effectivity and efficiency of the agent by deciding on probably the most informative and related samples to study from. That is significantly helpful in conditions the place the state house is massive or advanced, and the agent could not have the ability to discover all attainable states and actions in an affordable period of time.
Markov Determination Course of (MDP)
The Markov Decision Process (MDP) is a mathematical framework utilized in Reinforcement Studying (RL) to mannequin sequential decision-making issues. It will be significant as a result of it offers a proper illustration of the setting when it comes to states, actions, transitions between states, and a reward operate definition.
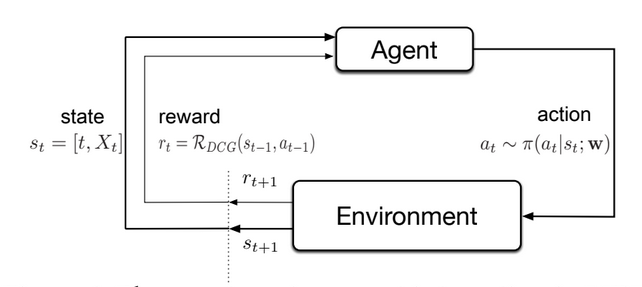
The MDP framework assumes that the present state relies upon solely on the earlier state and motion, which simplifies the issue and makes it computationally tractable. Utilizing the Markov Determination Course of, reinforcement studying algorithms can compute the optimum coverage that maximizes the anticipated cumulative reward.
Moreover, the MDP offers a framework for evaluating the efficiency of various RL algorithms and evaluating them towards one another.
Deep Reinforcement Studying
Up to now few years, Deep Studying strategies have change into highly regarded. Deep Reinforcement Studying is the mix of Reinforcement Studying with Deep Studying strategies to resolve difficult sequential decision-making issues.
Using deep studying is most helpful in issues with high-dimensional state house. Which means with deep studying, Reinforcement Studying is ready to clear up extra difficult duties with decrease prior information due to its potential to study totally different ranges of abstractions from knowledge.
To make use of reinforcement studying efficiently in conditions approaching real-world complexity, nonetheless, brokers are confronted with a tough process: they need to derive environment friendly representations of the setting from high-dimensional sensory inputs, and use these to generalize previous expertise to new conditions. This makes it attainable for machines to imitate some human problem-solving capabilities, even in high-dimensional house, which only some years in the past was tough to conceive.
Functions of Deep Reinforcement Studying
Some distinguished initiatives used deep Reinforcement Studying in video games with outcomes which might be far past what’s humanly attainable. Deep RL strategies have demonstrated their potential to deal with a variety of issues that have been beforehand unsolved.
Deep RL has achieved human-level or superhuman efficiency for a lot of two-player and even multi-player video games. Such achievements with fashionable video games are important as a result of they present the potential of deep Reinforcement Studying in a wide range of advanced and numerous duties which might be based mostly on high-dimensional inputs. With video games, now we have good and even good simulators, and might simply generate limitless knowledge.
- Atari 2600 video games: Machines achieved superhuman-level efficiency in playing Atari games.
- Go: Mastering the game of Go with deep neural networks.
- Poker: AI is ready to beat professional poker players within the recreation of heads-up no-limit Texas maintain’em.
- Quake III: An agent achieved human-level efficiency in a 3D multiplayer first-person video game, utilizing solely pixels and recreation factors as enter.
- Dota 2: An AI agent realized to play Dota 2 by taking part in over 10,000 years of video games towards itself (OpenAI Five).
- StarCraft II: An agent was in a position to discover ways to play StarCraft II a 99% win-rate, utilizing just one.08 hours on a single industrial machine.
These achievements set the idea for the event of real-world deep reinforcement studying purposes:
- Robotic management: Robotics is a classical software space for reinforcement studying. Sturdy adversarial reinforcement studying is utilized as an agent operates within the presence of a destabilizing adversary that applies disturbance forces to the system. The machine is skilled to learn an optimal destabilization policy. AI-powered robots have a variety of purposes, e.g. in manufacturing, provide chain automation, healthcare, and plenty of extra.
- Self-driving automobiles: Deep Reinforcement Studying is prominently used with autonomous driving. Autonomous driving scenarios contain interacting brokers and require negotiation and dynamic decision-making, which fits Reinforcement Studying.
- Healthcare: Within the medical area, Synthetic Intelligence (AI) has enabled the event of superior clever techniques in a position to study scientific therapies, present scientific determination assist, and uncover new medical information from the massive quantity of knowledge collected. Reinforcement Studying enabled advances akin to personalized medicine that’s used to systematically optimize affected person well being care, specifically, for power circumstances and cancers, utilizing particular person affected person info.
- Different: When it comes to purposes, many areas are prone to be impacted by the chances introduced by deep Reinforcement Studying, akin to finance, enterprise administration, advertising and marketing, useful resource administration, schooling, good grids, transportation, science, engineering, or artwork. In reality, Deep RL techniques are already in manufacturing environments. For instance, Facebook uses Deep Reinforcement Learning for pushing notifications and for sooner video loading with good prefetching.
Challenges of Deep Reinforcement Studying
A number of challenges come up in making use of Deep Reinforcement Studying algorithms. Normally, it’s tough to discover the setting effectively or to generalize good habits in a barely totally different context. Subsequently, a number of algorithms have been proposed for the Deep Reinforcement Studying framework, relying on a wide range of settings of the sequential decision-making duties.
Many challenges seem when shifting from a simulated setting to fixing real-world issues.
- Restricted freedom of the agent: In apply, even within the case the place the duty is well-defined (with specific reward features), a basic problem lies in the truth that it’s typically not attainable to let the agent work together freely and sufficiently within the precise setting, because of security, price or time constraints.
- Actuality hole: There could also be conditions, the place the agent isn’t in a position to work together with the true setting however solely with an inaccurate simulation of it. The reality gap describes the distinction between the training simulation and the efficient real-world area.
- Restricted observations: For some circumstances, the acquisition of recent observations will not be attainable anymore (e.g., the batch setting). Such situations happen, for instance, in medical trials or duties that depend upon climate circumstances or buying and selling markets akin to inventory markets.
How these challenges might be addressed:
- Simulation: For a lot of circumstances, an answer is the event of a simulator that’s as correct as attainable.
- Algorithm Design: The design of the training algorithms and their degree of generalization have a fantastic affect.
- Switch Studying: Transfer learning is an important approach to make the most of exterior experience from different duties to profit the training strategy of the goal process.
Reinforcement Studying and Laptop Imaginative and prescient
Laptop Imaginative and prescient is about how computer systems acquire understanding from digital photos and video streams. Laptop Imaginative and prescient has been making speedy progress not too long ago, and deep studying performs an vital position.
Reinforcement studying is an efficient instrument for a lot of laptop imaginative and prescient issues, like picture classification, object detection, face detection, captioning, and extra. Reinforcement Studying is a crucial ingredient for interactive notion, the place notion and interplay with the setting can be useful to one another. This consists of duties like object segmentation, articulation mannequin estimation, object dynamics studying, haptic property estimation, object recognition or categorization, multimodal object mannequin studying, object pose estimation, grasp planning, and manipulation ability studying.
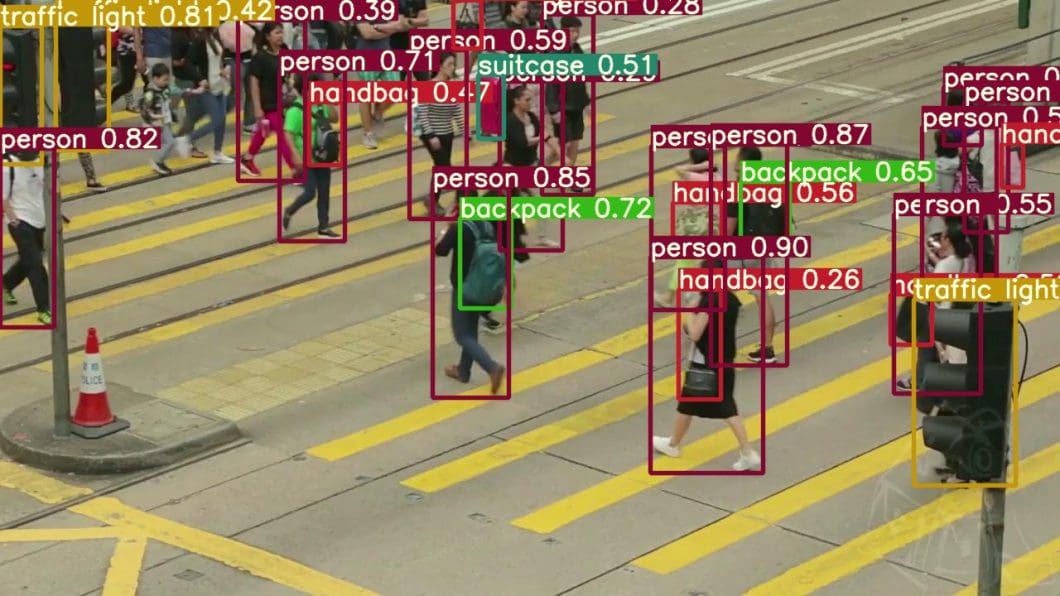
Extra subjects of making use of Deep Reinforcement Studying to laptop imaginative and prescient duties, akin to
What’s subsequent
Sooner or later, we anticipate to see deep reinforcement algorithms going within the course of meta-learning. Earlier information, for instance, within the type of pre-trained Deep Neural Networks, might be embedded to extend efficiency and cut back coaching time. Advances in switch studying capabilities will enable machines to study advanced decision-making issues in simulations (gathering samples in a versatile manner) after which use the realized abilities in real-world environments.
Try our information about supervised studying vs. unsupervised studying, or discover one other associated matter: