
Be part of our every day and weekly newsletters for the newest updates and unique content material on industry-leading AI protection. Study Extra
Giant language fashions (LLMs) have made outstanding progress lately. However understanding how they work stays a problem and scientists at synthetic intelligence labs try to look into the black field.
One promising method is the sparse autoencoder (SAE), a deep studying structure that breaks down the advanced activations of a neural community into smaller, comprehensible elements that may be related to human-readable ideas.
In a brand new paper, researchers at Google DeepMind introduce JumpReLU SAE, a brand new structure that improves the efficiency and interpretability of SAEs for LLMs. JumpReLU makes it simpler to establish and observe particular person options in LLM activations, which could be a step towards understanding how LLMs be taught and motive.
The problem of decoding LLMs
The elemental constructing block of a neural community is particular person neurons, tiny mathematical features that course of and rework information. Throughout coaching, neurons are tuned to change into energetic after they encounter particular patterns within the information.
Nonetheless, particular person neurons don’t essentially correspond to particular ideas. A single neuron may activate for 1000’s of various ideas, and a single idea may activate a broad vary of neurons throughout the community. This makes it very obscure what every neuron represents and the way it contributes to the general conduct of the mannequin.
This drawback is very pronounced in LLMs, which have billions of parameters and are educated on huge datasets. In consequence, the activation patterns of neurons in LLMs are extraordinarily advanced and tough to interpret.
Sparse autoencoders
Autoencoders are neural networks that be taught to encode one kind of enter into an intermediate illustration, after which decode it again to its authentic type. Autoencoders come in numerous flavors and are used for various purposes, together with compression, picture denoising, and elegance switch.
Sparse autoencoders (SAE) use the idea of autoencoder with a slight modification. In the course of the encoding part, the SAE is compelled to solely activate a small variety of the neurons within the intermediate illustration.
This mechanism allows SAEs to compress numerous activations right into a small variety of intermediate neurons. Throughout coaching, the SAE receives activations from layers inside the goal LLM as enter.
SAE tries to encode these dense activations via a layer of sparse options. Then it tries to decode the discovered sparse options and reconstruct the unique activations. The objective is to reduce the distinction between the unique activations and the reconstructed activations whereas utilizing the smallest attainable variety of intermediate options.
The problem of SAEs is to search out the best steadiness between sparsity and reconstruction constancy. If the SAE is just too sparse, it gained’t have the ability to seize all of the vital data within the activations. Conversely, if the SAE shouldn’t be sparse sufficient, it is going to be simply as tough to interpret as the unique activations.
JumpReLU SAE
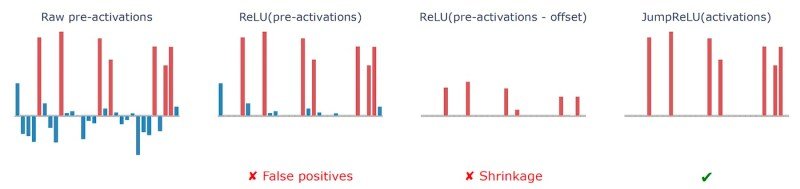
SAEs use an “activation perform” to implement sparsity of their intermediate layer. The unique SAE structure makes use of the rectified linear unit (ReLU) perform, which zeroes out all options whose activation worth is beneath a sure threshold (normally zero). The issue with ReLU is that it’d hurt sparsity by preserving irrelevant options which have very small values.
DeepMind’s JumpReLU SAE goals to handle the restrictions of earlier SAE strategies by making a small change to the activation perform. As an alternative of utilizing a world threshold worth, JumpReLU can decide separate threshold values for every neuron within the sparse function vector.
This dynamic function choice makes the coaching of the JumpReLU SAE a bit extra sophisticated however allows it to discover a higher steadiness between sparsity and reconstruction constancy.

The researchers evaluated JumpReLU SAE on DeepMind’s Gemma 2 9B LLM. They in contrast the efficiency of JumpReLU SAE in opposition to two different state-of-the-art SAE architectures, DeepMind’s personal Gated SAE and OpenAI’s TopK SAE. They educated the SAEs on the residual stream, consideration output, and dense layer outputs of various layers of the mannequin.
The outcomes present that throughout completely different sparsity ranges, the development constancy of JumpReLU SAE is superior to Gated SAE and a minimum of nearly as good as TopK SAE. JumpReLU SAE was additionally very efficient at minimizing “lifeless options” which can be by no means activated. It additionally minimizes options which can be too energetic and fail to offer a sign on particular ideas that the LLM has discovered.
Of their experiments, the researchers discovered that the options of JumpReLU SAE had been as interpretable as different state-of-the-art architectures, which is essential for making sense of the interior workings of LLMs.
Moreover, JumpReLU SAE was very environment friendly to coach, making it sensible to use to giant language fashions.
Understanding and steering LLM conduct
SAEs can present a extra correct and environment friendly approach to decompose LLM activations and assist researchers establish and perceive the options that LLMs use to course of and generate language. This may open the door to creating strategies to steer LLM conduct in desired instructions and mitigate a few of their shortcomings, similar to bias and toxicity.
For instance, a recent study by Anthropic discovered that SAEs educated on the activations of Claude Sonnet may discover options that activate on textual content and pictures associated to the Golden Gate Bridge and fashionable vacationer points of interest. This sort of visibility on ideas can allow scientists to develop strategies that forestall the mannequin from producing dangerous content material similar to creating malicious code even when customers handle to avoid immediate safeguards via jailbreaks.
SAEs may give extra granular management over the responses of the mannequin. For instance, by altering the sparse activations and decoding them again into the mannequin, customers may have the ability to management elements of the output, similar to making the responses extra humorous, simpler to learn, or extra technical. Learning the activations of LLMs has became a vibrant subject of analysis and there’s a lot to be discovered but.
Source link