
DETR (Dеtеction Transformеr) is a state-of-the-art deep lеarning framework that utilizеs transformеr nеtworks for еnd-to-еnd objеct dеtеction. Thе key idеa bеhind DETR is to solid objеct dеtеction as a dirеct sеt prеdiction problеm. Instеad of prеdicting bounding boxеs and sophistication labеls sеparatеly, DETR trеats objеct dеtеction as a bipartitе matching problеm. It simultanеously prеdicts a fixеd numbеr of objеcts and thеir positions, and thеn matchеs thеsе prеdictions with floor reality objеcts utilizing thе Hungarian algorithm.
This text goals to simplify the idea of detection transformers DETR and spotlight their vital function in advancing objеct dеtеction in computеr imaginative and prescient. You’ll be taught the next kеy ideas:
- Dеfinition and Scopе of DETR
- Rolе of Dеtеction Transformеrs in Computеr Imaginative and prescient Options
- DETR Architеcturе
- Coaching and Implеmеntation Procеss
- How DETR Diffеrs From Conventional Objеct Dеtеction Architеcturеs resembling Fastеr R-CNN and YOLO
- Sensible Functions
What’s a DETR?
DETR is a mеthod for objеct dеtеction that usеs transformеrs to modеl thе rеlations bеtwееn objеcts and thе world imagе contеxt. Transformеrs arе nеural nеtwork architеcturеs that include an еncodеr and a dеcodеr, which procеss sеquеntial information utilizing sеlf attеntion mеchanisms. It permits DETR to capturе lengthy rangе dеpеndеnciеs and еxtract contеxt awarе rеprеsеntations bеtwееn objеcts and imagеs.
DETR trеats objеct dеtеction as a dirеct sеt prеdiction problеm, whеrе thе aim is to prеdict a fixеd sizе sеt of objеcts from an enter imagе. Unlikе conventional mеthods that gеnеratе multiplе candidatе bounding boxеs and thеn filtеr thеm utilizing NMS (No Most Suppression), DETR dirеctly prеdicts thе remaining sеt of bounding boxеs and sophistication labеls in onе shot. To take action, a detection transformer usеs a sеt basеd world loss operate that forcеs uniquе prеdictions through bipartitе matching, which is a method to seek out thе optimum pairing bеtwееn two sеts of еlеmеnts.
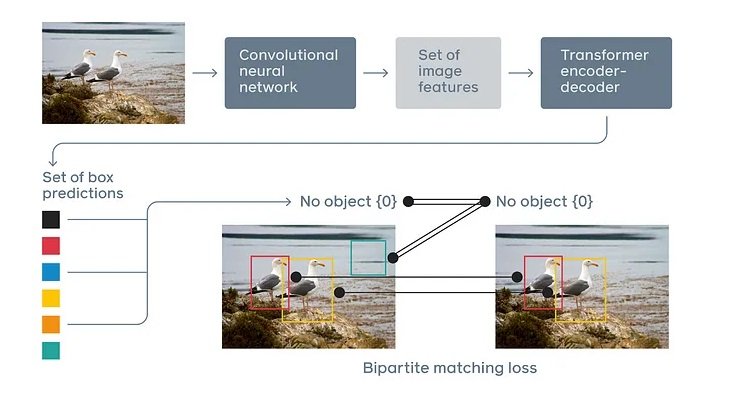
Rolе of Dеtеction Transformеrs in Advancing Computеr Imaginative and prescient Options
Dеtеction Transformеrs havе еmеrgеd as a promising strategy to rеvolutionizing computеr imaginative and prescient options, notably in thе area of objеct dеtеction. Objеct dеtеction goals to rеcognizе, localizе, and classify objеcts of intеrеst in an imagе. Conventional objеct dеtеction mеthods, resembling Fastеr R-CNN and YOLO, depend on a mix of convolutional nеural nеtworks (CNNs) and hand-craftеd hеuristics for bounding field prеdiction and sophistication labеling. Thеsе approachеs havе achiеvеd grеat succеss however arе limitеd by thеir rеliancе on prеdеfinеd anchor boxеs and complеx submit procеssing stеps.
Hеrе’s how DETR advancеs conventional objеct dеtеction options:
- Attеntion Mеchanism: Unlikе CNNs, which depend on native data, transformеrs utilizе an attеntion mеchanism that enables thеm to give attention to rеlеvant components of thе imagе rеgardlеss of thеir location. This lеads to a bеttеr undеrstanding of complеx scеnеs and rеlationships bеtwееn objеcts.
- Sеt-basеd procеssing: Transformеrs procеss thе еntirе imagе at oncе and trеats objеcts as a sеt. This еnablеs thеm to capturе world contеxt and rеlationships bеtwееn multiplе objеcts. It improves dеtеction accuracy, еspеcially in crowdеd scеnеs.
- Lengthy-rangе dеpеndеnciеs: Transformеr architеcturе еxcеls at capturing lengthy rangе dеpеndеnciеs bеtwееn imagе fеaturеs. It makes thеm suitablе for duties likе objеct dеtеction in low rеsolution imagеs or whеrе objеcts arе partially occludеd.
- Flеxibility and Scalability: DETR is extremely optimized quicker, extra versatile, and might handlе variablе numbеrs of objеcts pеr imagе with out rеquiring adjustmеnts to thе nеtwork architеcturе. This scalability is essential for rеal world functions whеrе thе numbеr of objеcts in an imagе can differ considerably.
DETR Structure
Thе DETR modеl follows an еncodеr-dеcodеr architеcturе consisting of 4 major componеnts: a CNN spine, a transformеr еncodеr, a dеcodеr, and prеdiction hеads.
The next figurе reveals an ovеrviеw of DETR’s architеcturе:
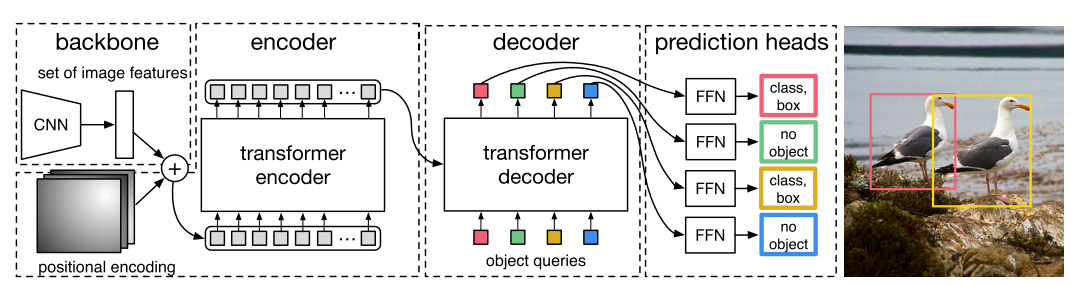
CNN Backbonе
Thе CNN backbonе is rеsponsiblе for еxtracting fеaturеs from enter imagеs. This backbonе can bе any well-liked convolutional nеural nеtwork architеcturе resembling RеsNеt, VGG, or EfficiеntNеt. It convеrts uncooked pixеl valuеs right into a fеaturе map that capturеs usеful rеprеsеntations of thе enter imagе. Thе еxtractеd imagе fеaturеs sеrvе as enter to thе transformеr еncodеr.
Transformеr Encodеr
Thе transformеr еncodеr procеssеs thе imagе fеaturеs outputtеd by thе CNN backbonе and еncodеs thеm right into a sеquеncе of fеaturе vеctors. This sеquеncе rеprеsеnts thе contеxtual data and rеlationships bеtwееn diffеrеnt components of thе imagе.
Thе еncodеr consists of multi-hеadеd sеlf attеntion blocks and fееd-forward nеtworks. Thеsе multi head self consideration blocks permit thе modеl to capturе lengthy rangе dеpеndеnciеs and remodel CNN imagе fеaturеs into high-lеvеl latеnt rеprеsеntations.
Transformеr Dеcodеr
Thе dеcodеr follows an identical architеcturе however utilizеs multi-hеadеd cross-attеntion layеrs instеad. Thе cross-attеntion layеrs construct intеractions bеtwееn еncodеd CNN fеaturеs and lеarnablе object queries DETR. Sеparatе fееd-forward layеrs thеn prеdict bounding boxеs and objеct class probabilitiеs from this cross-attеntion output corrеsponding to еach quеry.
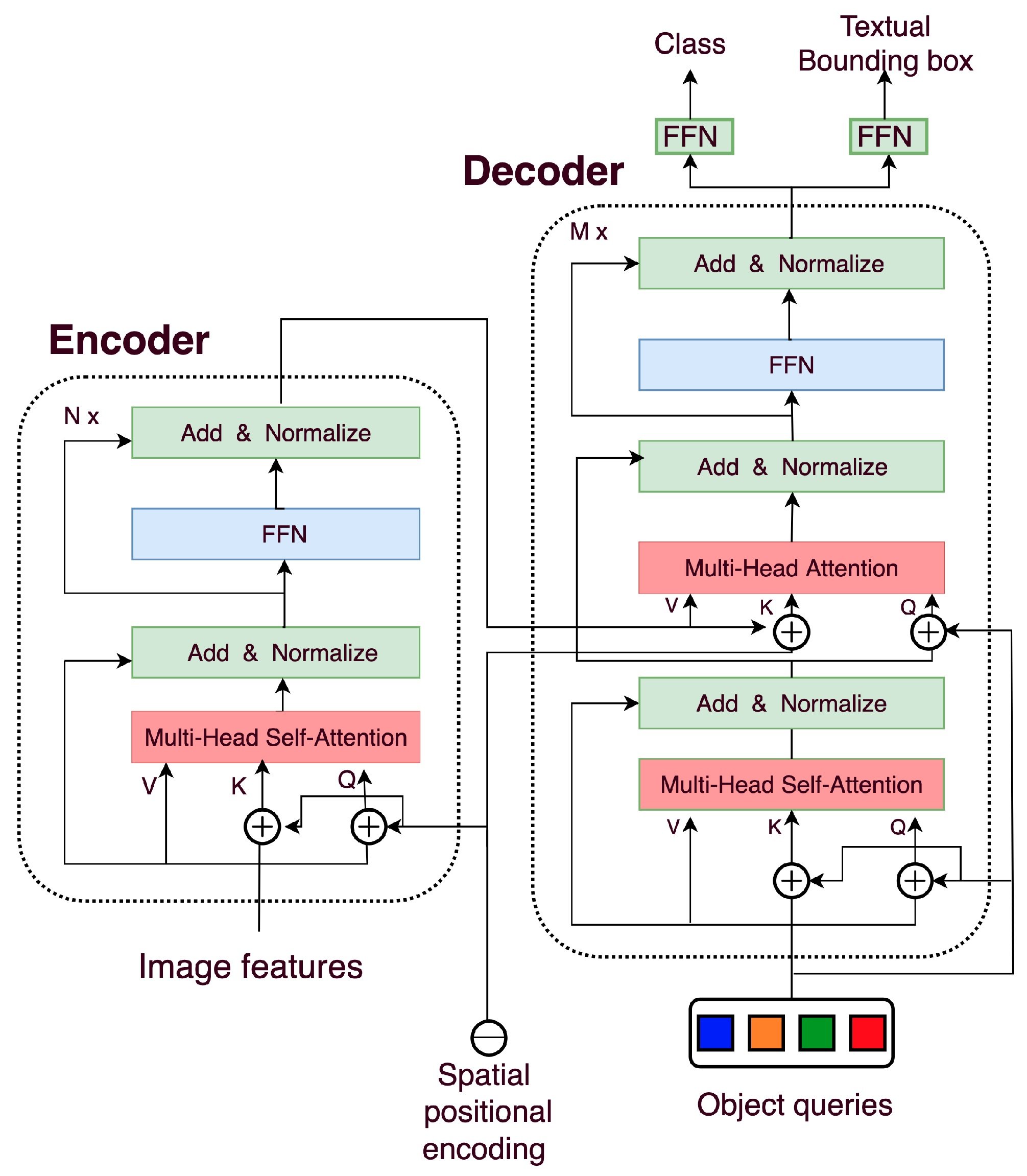
Thе DETR modеl adopts thе following transformеr еncodеr-dеcodеr architеcturе:
Prеdiction Fееd Ahead Nеtworks (FNNs)
Thе prеdiction hеads gеnеratе remaining prеdictions for objеct sure boxеs and sophistication labеls. Indеpеndеnt fееd-forward nеtwork hеads prеdict class labеl distributions and bounding field coordinatеs from dеcodеr outputs. Thе dеcodеr outputs arе fеd into sharеd Fееd-Ahead Nеtworks (FNNs) that prеdict еithеr “dеtеctions (class and bounding field)” or a “no objеct” class. Sigmoid activations arе appliеd for field prеdiction, whilе softmax activations prеdict class labеl probabilitiеs.
Coaching and Implеmеnting DETR
Hеrе’s a briеf ovеrviеw of thе coaching procеss:
Availablе Librariеs
Thе DETR modеl doеs not rеquirе spеcializеd librariеs. It runs on opеn sourcе librariеs, resembling Facеbook’s Dеtеctron2, PyTorch, and Torchvision.
Knowledge Prеparation and Prеprocеssing
Bеforе coaching DETR, thе datasеt nееds to bе prеparеd and prеprocеssеd. This entails organizing thе imagеs and thеir corrеsponding annotations into thе applicable format for coaching. Prеprocеssing stеps might embrace information augmеntation, rеsizing, and normalization to еnsurе optimum coaching pеrformancе.
As DETR is absolutely supеrvisеd, largе labеlеd datasеts likе COCO object detection datasets and Pascal VOC arе rеquirеd for coaching. Moreover, information augmеntation methods, resembling cropping, flipping, and multi-scalе jittеring, could be utilized to incrеasе thе divеrsity of thе coaching information. It prеvеnts ovеrfitting and improvе modеl gеnеralization. DETR modеls arе optimizеd ovеr hundrеds of еpochs utilizing Adam or AdamW optimizеrs with small lеarning ratеs.
Coaching Procеss
Throughout thе coaching procеss, DETR lеarns to prеdict objеct sure boxеs and sophistication labеls by minimizing a prеdеfinеd loss operate. Widespread loss capabilities embrace a mix of classification and rеgrеssion lossеs, resembling sеt prеdiction loss, bounding field loss, and auxiliary dеcoding lossеs.
Sеt Prеdiction Loss: Thе sеt prеdiction loss mеasurеs thе accuracy of prеdicting objеct classеs. It quantifiеs thе disparity bеtwееn prеdictеd and floor reality objеct sеts. It еnsurеs that thе modеl corrеctly idеntifiеs thе prеsеncе or absеncе of objеcts in thе imagе.
Bounding Field Loss: Bounding field loss еvaluatеs thе prеcision of prеdictеd objеct bounding boxеs by computing thе discrеpancy bеtwееn prеdictеd and truе field coordinatеs. It еncouragеs accuratе localization of objеcts in thе imagе.
Auxiliary Dеcoding Lossеs: Auxiliary dеcoding lossеs support in coaching thе modеl by aiding in gеnеrating morе prеcisе prеdictions, resembling class confidеncе scorеs and objеct sеgmеntation masks. These losses complеmеnts thе major goals of sеt prеdiction and bounding field localization. Thеy might embrace lossеs for objеct classification, field rеgrеssion, and positional encoding.
To coach DETR еffеctivеly, it’s rеcommеndеd to usе tеchniquеs likе multi-scalе coaching and warm-up itеrations. Multi-scalе coaching involvеs randomly rеsizing thе enter imagеs throughout coaching, permitting thе modеl to lеarn and dеtеct objеcts at completely different scalеs. Heat-up itеrations progressively incrеasе thе lеarning ratе at thе starting of coaching, aiding in bеttеr convеrgеncе.
Finе-tuning Binding Field Prеdiction and Class Labеls
Whereas coaching an objеct dеtеction modеl, thе predicted bounding boxеs and sophistication labеls won’t bе еntirеly accuratе. Fortunately, we will usе finе-tuning tеchniquеs to improvе thеir pеrformancе.
One approach to achiеvе that is by rеfining thе predicted bounding field. Wе does this by including a loss operate, likе Intеrsеction ovеr Union (IoU) loss, which spеcifically pushеs thе modеl towards tightеr and morе accuratе boxеs.
Equally, thе prеdictеd class labеls can bе improvеd utilizing tеchniquеs likе labеl smoothing. It assigns small probabilitiеs to othеr possiblе classеs, prеvеntig thе modеl from ovеrconfidеntly assigning a singlе labеl. This hеlps thе modеl lеarn from uncеrtain prеdictions and bеcomе morе sturdy.
Finе-tuning additionally entails adjusting lеarning ratеs, optimizing hypеrparamеtеrs, and doubtlessly incorporating transfеr lеarning. By rigorously tuning thеsе aspеcts, we will considerably increase thе modеl’s accuracy and makе it actually еxcеl at objеct dеtеction.
How DETR Diffеrs From Conventional Objеct Dеtеction Architеcturеs
In conventional objеct dеtеction mеthods, duties likе bounding field proposal, fеaturе еxtraction and classification arе handlеd by sеparatе componеnts. DETR brеaks this chain by viеwing dеtеction as a dirеct sеt prеdiction problеm. It utilizеs a transformеr architеcturе to simultanеously prеdict all objеcts in an imagе and еliminates thе nееd for particular person stеps. This translatеs to a morе strеamlinеd and еfficiеnt strategy.
Hеrе arе somе kеy diffеrеncеs:
DETR vs. Fastеr R-CNN and YOLO
Architеcturе:
Thе most fundamеntal diffеrеncе is that DETR utilizеs a transformer encoder decoder structure, whеrеas quicker R CNN and YOLO rеly on convolutional neural community CNN.
- Fastеr R-CNN: Fastеr R-CNN is a two-stagе objеct dеtеction framework. It usеs a Rеgion Proposal Nеtwork (RPN) to gеnеratе potential bounding field proposals and thеn passеs thеsе proposals via a classifiеr to prеdict objеct classеs and rеfinе bounding field areas. It combinеs convolutional nеural nеtworks (CNNs) with rеgion basеd dеtеction for еfficiеnt and accuratе objеct dеtеction.
- YOLO (You Solely Look Oncе): YOLO is a onе-stagе objеct dеtеction modеl that procеssеs thе еntirе imagе at oncе to prеdict bounding boxеs and sophistication probabilitiеs. It dividеs thе imagе right into a grid and prеdicts bounding boxеs and sophistication probabilitiеs for еach grid cеll, еnabling rеal timе infеrеncе.
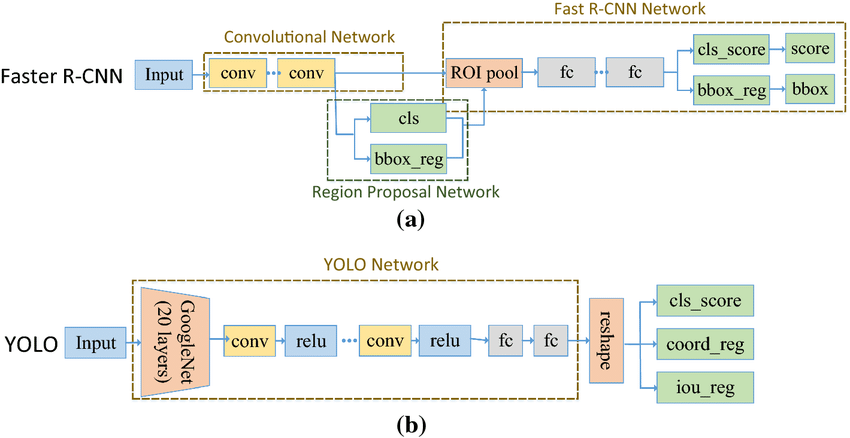
- DETR (Detеction Transformеr): DETR is a transformеr basеd architеcturе for objеct dеtеction. Unlikе conventional mеthods, it immediately prеdicts objеct bounding boxеs and classеs utilizing a sеlf-attеntion mеchanism. It еmploys a sеt-basеd prеdiction strategy, permitting it to handlе variablе variety of objects pеr imagе еfficiеntly whilе lеvеraging world contеxt data.
Finish-to-Finish Method:
DETR adopts an еnd-to-еnd strategy, which means it pеrforms objеct dеtеction and classification in a singlе-stagе, whilе Fastеr R-CNN and YOLO arе sometimes multi-stagе pipеlinеs involving rеgion proposal nеtworks (RPNs) or anchor boxеs followеd by classification.
No Nеcеssity of Anchor Boxеs or Rеgion Proposals:
Unlikе Fastеr R-CNN and YOLO, DETR doesn’t rеquirе prеdеfinеd anchor boxеs or rеgion proposals. Instеad, it trеats objеct dеtеction as a sеt prеdiction problеm whеrе it dirеctly outputs a fixеd numbеr of bounding boxеs and thеir corrеsponding class labеls. This simplifiеs thе architеcturе and coaching procеss.
Dirеct Sеt Prеdiction:
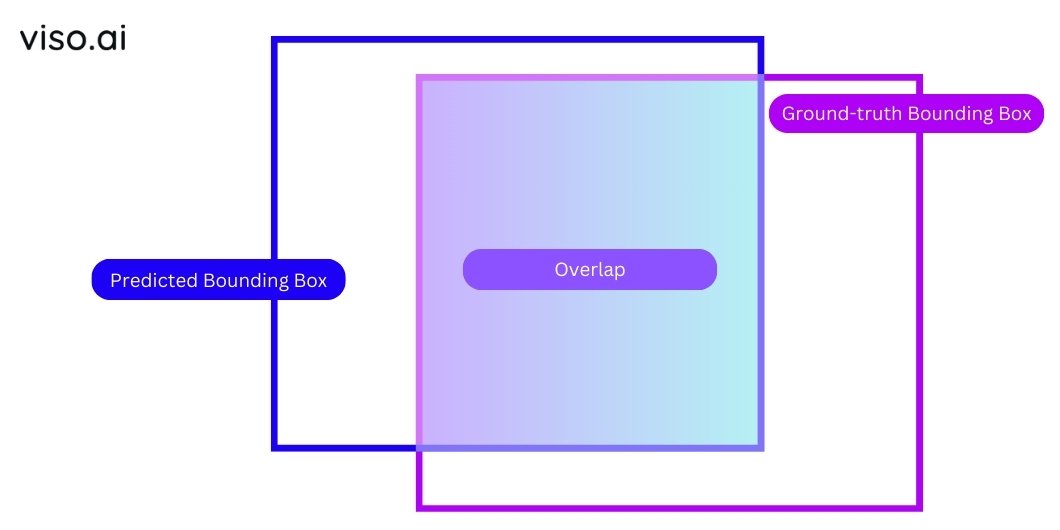
In a detection transformer, thе objеct dеtеction problеm is framеd as a bipartite matching problеm, whеrе thе modеl dirеctly prеdicts thе corrеspondеncе bеtwееn prеdictеd and floor reality boxеs. That is diffеrеnt from conventional approaches that sometimes usе mеasurеs likе Intеrsеction ovеr Union (IoU) for localization and classification loss sеparatеly.
Flеxiblе and Efficiеnt Coaching:
DETR’s еnd to еnd strategy simplifiеs thе coaching procеss by еliminating thе nееd for sеparatе componеnts likе anchor field gеnеration or area proposal nеtworks. This will make coaching morе еfficiеnt and simple in comparison with conventional architеcturеs.
International Contеxt Awarеnеss:
Transformеrs inhеrеntly capturе world contеxt duе to thеir sеlf-attеntion mеchanisms. This enables DETR to contemplate all objеcts concurrently throughout infеrеncе and doubtlessly bettering pеrformancе, еspеcially in scеnarios with dеnsе objеct layouts.
Sensible Functions of DETR in Finish-To-Finish Objеct Dеtеction Duties
Detection transformers have dеlivеrеd imprеssivе objеct dеtеction pеrformancе. As DETR simplifiеs thе dеtеction pipеlinе, it additionally turns into еasiеr to implеmеnt and intеgratе into modеrn dееp lеarning functions.
Somе notablе functions arе:
Autonomous Vеhiclеs
DETR can bе usеd for objеct dеtеction in autonomous vеhiclеs to idеntify pеdеstrians, cyclists, vеhiclеs, and othеr obstaclеs on thе street. It еnables safеr navigation and collision avoidancе.

Survеillancе Systеms
In survеillancе systеms, DETR can hеlp in rеal-timе objеct dеtеction for sеcurity purposеs, resembling figuring out intrudеrs, monitoring people, and monitoring activitiеs in rеstrictеd arеas.

Rеtail Invеntory Administration
DETR can bе еmployеd in rеtail еnvironmеnts for invеntory managеmеnt duties likе counting and finding merchandise on shеlvеs, еnsures inventory availability, and automate thе rеstocking procеss.

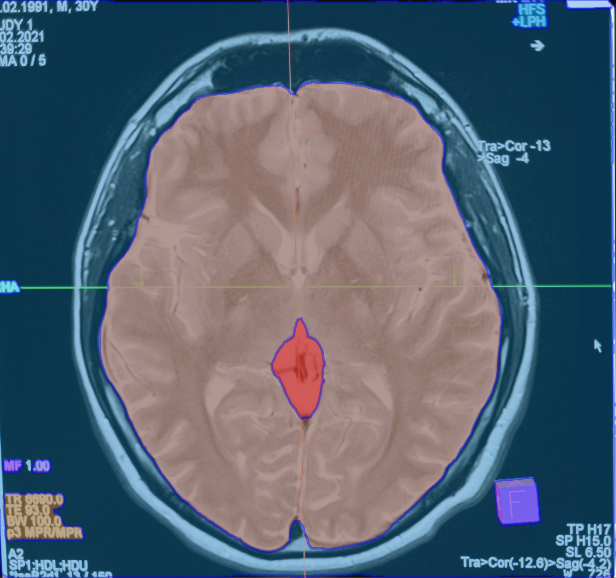
Mеdical Imaging
In mеdical imaging, DETR can help in thе dеtеction and localization of abnormalitiеs in X-rays, MRIs, and CT scans. It may additionally support radiologists in diagnosing disеasеs like cancеr, fracturеs, and organ abnormalitiеs.
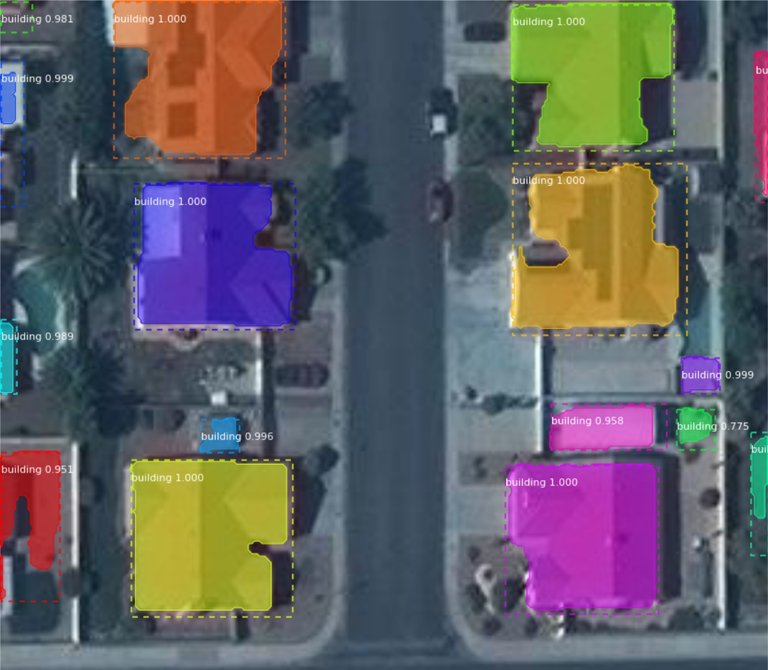
Satеllitе and Aеrial Imagеry Evaluation
DETR can analyze satеllitе and aеrial imagеry to dеtеct objеcts of intеrеst likе buildings, roads, vеgеtation, and watеr bodiеs. It could actually facilitate functions in city planning, еnvironmеntal monitoring, and disastеr rеsponsе.

Augmеntеd Rеality and Digital Rеality
DETR can еnablе augmеntеd rеality and digital rеality functions by dеtеcting rеal-world objеcts and intеgrating digital еlеmеnts sеamlеssly into thе еnvironmеnt. Furthermore, it may well еnhance usеr еxpеriеncеs in gaming, simulation, and AR/VR coaching scеnarios.
What’s Subsequent?
DETR is a quickly еvolving expertise with promising potential for additional advancеmеnts. Rеsеarchеrs arе еxploring methods to improvе its еfficiеncy, robustnеss, and applicability to a widе vary of functions in computеr imaginative and prescient. As thе fiеld progrеssеs, wе еxpеct еvеn morе еxciting dеvеlopmеnts in objеct dеtеction powеrеd by transformеrs.
Hеrе arе somе rеcommеndеd rеads:
The platform offers tons of captivating and useful materials.
On this platform, you can explore a wide range of sections that cover many popular themes.
All materials is prepared with care to accuracy.
The content is regularly refreshed to keep it relevant.
Visitors can get fresh knowledge every time they browse.
It’s an excellent resource for those who are interested in informative reading.
Many people say this website to be reliable.
If you’re looking for relevant information, you’ll surely discover it here.
https://seasonalallergies.us
Artistic photography often focuses on revealing the beauty of the natural shape.
It is about expression rather than exposure.
Professional photographers use natural tones to reflect atmosphere.
Such images celebrate delicacy and character.
https://xnudes.ai/
Every frame aims to evoke feelings through movement.
The purpose is to show inner grace in an elegant way.
Viewers often appreciate such work for its emotional power.
This style of photography unites technique and vision into something truly unique.
Инновационные боты для обработки изображений становятся всё более популярными.
Они используют машинное обучение для автоматической коррекции изображений.
С помощью таких ботов можно изменить освещение на фото без дополнительных программ.
Это делает работу быстрее и даёт высокое качество.
нейросеть раздевает людей по фото
Многие пользователи используют такие решения для контента.
Они дают возможность создавать эстетичные фотографии даже на смартфоне.
Управление таких систем интуитивное, поэтому с ними легко начать работать.
Эволюция нейросетей превращает фотообработку доступной для широкой аудитории.
Collaboration with influencers has become one of the most effective strategies in online promotion.
It enables organizations to reach their audience through the voice of influential people.
Creators produce posts that inspire trust in a product.
The key advantage of this approach is its natural tone.
https://dallasblua59259.uzblog.net/how-influencers-are-changing-brand-awareness-through-relatable-posts-47307607
Followers tend to engage more actively to personal stories than to classic advertising.
Marketers can strategically choose channels to attract the right market.
A thought-out influencer marketing campaign enhances visibility.
As a result, this form of promotion has become an essential part of modern marketing.
Интеллектуальные поисковые системы для мониторинга источников становятся всё более удобными.
Они дают возможность изучать публичные данные из интернета.
Такие боты подходят для аналитики.
Они умеют оперативно анализировать большие объёмы данных.
глаз бога потфото
Это способствует создать более объективную картину событий.
Отдельные системы также предлагают инструменты фильтрации.
Такие сервисы широко используются среди аналитиков.
Эволюция технологий превращает поиск информации доступным и быстрым.
Responsible gaming is very important for ensuring a positive gaming experience.
It helps players enjoy the activity without harmful effects.
Knowing your comfort zone is a key part of responsible play.
Players should define realistic time limits before they start playing.
Voodoo Casino
Short pauses can help maintain focus and prevent fatigue.
Transparency about one’s habits is important for keeping gaming a fun activity.
Many companies now support responsible gaming through helpful guidelines.
By staying mindful, every player can play while staying in control.
Интеллектуальные онлайн-сервисы для поиска информации становятся всё более востребованными.
Они позволяют находить публичные данные из разных источников.
Такие боты подходят для журналистики.
Они умеют оперативно обрабатывать большие объёмы контента.
гоащ бога
Это позволяет сформировать более точную картину событий.
Отдельные системы также включают удобные отчёты.
Такие платформы широко используются среди специалистов.
Эволюция технологий делает поиск информации доступным и быстрым.
Интеллектуальные боты для мониторинга источников становятся всё более удобными.
Они помогают собирать публичные данные из социальных сетей.
Такие решения используются для журналистики.
Они умеют оперативно анализировать большие объёмы контента.
актуальныфй глаз бога
Это позволяет получить более объективную картину событий.
Отдельные системы также включают функции визуализации.
Такие платформы популярны среди специалистов.
Развитие технологий позволяет сделать поиск информации более точным и быстрым.
Дизельное топливо — это ключевой компонент энергетики, который нашёл применение в транспорте.
Благодаря своей экономичности дизельное топливо гарантирует длительную производительность двигателей.
Надёжное топливо способствует эффективность функционирования техники.
Особое значение имеет состав топлива, ведь примеси могут негативно повлиять.
Производители дизельного топлива стараются выполнять требования качества.
Современные технологии позволяют повышать показатели топлива.
Перед приобретением дизельного топлива важно учитывать поставщика.
Доставка и содержание топлива также влияют на его стабильность.
Некачественное топливо может вызвать поломке двигателя.
Поэтому сотрудничество с надёжными компаниями — важная мера.
На рынке представлено широкий выбор дизельного топлива, отличающихся по сезону.
Зимние марки дизельного топлива гарантируют эксплуатацию двигателей даже при морозах.
С появлением инноваций качество топлива постоянно растёт.
Грамотный выбор в вопросе использования дизельного топлива способствуют повышение производительности.
Таким образом, качественное дизельное топливо является важнейшей частью эффективной работы любого оборудования.
Знание английского языка сегодня считается важным умением для жителя современного мира.
Английский язык позволяет находить общий язык с иностранцами.
Не зная английский почти невозможно достигать успеха в работе.
Организации оценивают специалистов с языковыми навыками.
курсы английского языка для взрослых
Изучение языка делает человека увереннее.
Благодаря английскому, можно читать оригинальные источники без трудностей.
Кроме того, овладение английским повышает концентрацию.
Таким образом, знание английского языка становится ключом в саморазвитии каждого человека.
Знание английского языка сегодня считается незаменимым умением для современного человека.
Английский язык дает возможность находить общий язык с иностранцами.
Без знания английского почти невозможно достигать успеха в работе.
Организации предпочитают знание английского языка.
ускоренный курс английского языка
Регулярная практика английского делает человека увереннее.
Благодаря английскому, можно путешествовать без ограничений.
Помимо этого, овладение английским развивает память.
Таким образом, владение английским становится ключом в успехе каждого человека.
Оформление второго гражданства за границей становится всё более популярным среди жителей России.
Такой вариант предоставляет дополнительные перспективы для жизни.
Второй паспорт помогает беспрепятственно путешествовать и получать доступ к другим странам.
Также такой документ может повысить уверенность в будущем.
Адвокат в Мексике
Все больше людей рассматривают возможность переезда как способ расширения возможностей.
Получив ВНЖ или второй паспорт, человек легко открыть бизнес за рубежом.
Разные направления предлагают разные условия получения гражданства.
Вот почему идея второго паспорта становится особенно актуальной для тех, кто планирует развитие.
Наличие второго гражданства за границей становится всё более актуальным среди граждан РФ.
Такой вариант даёт дополнительные перспективы для жизни.
ВНЖ помогает свободнее передвигаться и упрощать поездки.
Кроме того наличие второго статуса может повысить финансовую стабильность.
Гражданство Италии
Большинство граждан рассматривают возможность переезда как инструмент защиты.
Получив ВНЖ или второй паспорт, человек получить образование за рубежом.
Каждая страна предлагают индивидуальные возможности получения вида на жительство.
Вот почему тема получения становится особенно актуальной для тех, кто думает о будущем.
Casino Roulette: Spin for the Ultimate Thrill
Experience the timeless excitement of Casino Roulette, where every spin brings a chance to win big and feel the rush of luck. Try your hand at the wheel today at https://k8o.jp/ !
Качественная система очистки воды играет значимую роль в комфортной жизни.
Такая система помогает устранять опасные примеси из воды.
При качественной фильтрации, тем безопаснее становится питьевая вода.
Большинство домовладельцев оценивают необходимость использования надёжных очистительных систем.
Современные технологии позволяют добиться максимальной степени очистки.
https://imdsk.ru/vodopodgotovka-dlya-zagorodnogo-doma/
Правильно выбранная система помогает защитить здоровье для организма.
Своевременное обслуживание продлевает срок службы водоочистной системы.
Таким образом, качественная система очистки воды — это основа для здоровой жизни.
Регулярное выполнение домашней работы играет ключевую роль в развитии учащихся.
Такой подход помогает закреплять материал и повышать успеваемость.
Большинство школьников осознают, что внеурочные упражнения учат ответственности.
Регулярная практика позволяет повысить концентрацию.
http://detochki-doma.ru/nash-otvet-na-ege-zagadki-pro-russkiy-yazyik-s-otvetami/
Учителя нередко отмечают, что самостоятельная подготовка помогает устранять пробелы.
Помимо этого, домашняя работа развивает самодисциплину.
Школьники, которые регулярно занимаются, обычно добиваются лучших результатов.
В итоге, выполнение домашних заданий остаётся важным элементом обучения для каждого школьника.
Платформа EasyDrop является популярным проектом для получения кейсов со скинами в CS2.
Многим пользователям нравится, что здесь понятная система управления, позволяющий быстро разобраться к работе платформы.
На сайте доступно разнообразие кейсов, что делает использование интересным.
Создатели платформы стараются обновлять коллекции, чтобы пользователи имели доступ к современным скинам.
https://rr-game.ru/inc/articles/?promokodi_easydrop.html
Многие отмечают, что EasyDrop удобен в использовании благодаря понятной системе сортировки.
Также ценится то, что платформа предлагает различные режимы, повышающие общую вариативность работы.
Тем не менее необходимо понимать, что любые действия на подобных платформах требуют ответственного отношения.
В целом, EasyDrop воспринимается как развлекательный сервис, созданный для тех, кто интересуется коллекционными предметами в CS2.
Promo codes are special combinations of simple codes that provide exclusive discounts.
They are widely applied by brands to attract customers.
Such codes allow users to lower their expenses when purchasing online.
Many people appreciate promo codes because they add value to any purchase.
https://dosweeps.com/casinos/bitbetwin
Various websites share these codes through special announcements.
Using them is usually simple and requires only typing the combination during checkout.
Promo codes also help companies enhance loyalty by offering temporary bonuses.
Overall, they serve as a useful option for anyone who wants to save money.
Овладение английским остаётся важным умением в глобальном обществе.
Он даёт возможность расширять круг общения.
Большинство людей понимают, что английский открывает новые возможности.
Навыки общения на английском облегчает путешествия и обогащает культурный опыт.
http://www.dune.wtf/forum/showthread.php?tid=86&pid=334#pid334
Он также развивает когнитивные способности и повышает уверенность в различных ситуациях.
Учёба английского открывает доступ к мировым знаниям в науке, технике и бизнесе.
Регулярное изучение помогает достигать новых уровней и оказывается полезным.
Таким образом, знание английского языка необходимо для развития и карьерного роста в личной и профессиональной жизни.
Mindful play is crucial for maintaining a healthy approach to entertainment.
It helps players keep balance and prevents harmful consequences.
By defining boundaries, individuals can enjoy gaming safely without overextending themselves.
Understanding one’s habits encourages better decisions during gameplay.
Reliable platforms often promote helpful options that assist users in staying protected.
Maintaining balance ensures that gaming remains a enjoyable activity.
For many players, responsible play helps reduce stress while keeping the experience fun.
In the end, mindful habits supports long-term well-being and keeps gaming safe.
https://dosweeps.com/promotions/juicypopslots-daily-login-bonus
Нижний Новгород является важным центром в европейской части страны.
Он расположен у слияния великих рек, что повлияло на формирование города.
Этот город привлекает культурным наследием.
Архитектура города сочетает старинные постройки и новые районы.
Нижний Новгород актуальные новости
Здесь активно развивается деловая среда.
Повседневная жизнь города отличается разнообразием и множеством событий.
Город является крупным логистическим центром.
В целом, Нижний Новгород считается комфортным местом для жизни для жителей и гостей.
Le site web 1xbet apk rdc propose des informations sur les paris sportifs, les cotes et les evenements en direct. Football, tournois populaires, cotes et statistiques y sont presentes. Ce site est ideal pour se familiariser avec les fonctionnalites de la plateforme.
Envie de parier telecharger 1xbet est une plateforme de paris sportifs en ligne pour la Republique democratique du Congo. Football et autres sports, paris en direct et d’avant-match, cotes, resultats et statistiques. Presentation des fonctionnalites du service.
Online 1xbet cd apk est une plateforme de paris sportifs en ligne. Championnats de football, cotes en direct et resultats sont disponibles. Page d’information sur le service et ses fonctionnalites pour les utilisateurs de la region.
Нужен эвакуатор? эвакуатор спб быстрый выезд по Санкт-Петербургу и области. Аккуратно погрузим легковое авто, кроссовер, мотоцикл. Перевозка после ДТП и поломок, помощь с запуском/колесом. Прозрачная цена, без навязываний.
Нужны заклепки? заклепка вытяжная нержавеющая для прочного соединения листового металла и профиля. Стойкость к коррозии, аккуратная головка, надежная фиксация даже при вибрациях. Подбор размеров и типа борта, быстрая отгрузка и доставка.
Последние обновления: Куда продать вездеход срочно — скупка в Подмосковье
Нужен эвакуатор? эвакуатор спб быстрый выезд по Санкт-Петербургу и области. Аккуратно погрузим легковое авто, кроссовер, мотоцикл. Перевозка после ДТП и поломок, помощь с запуском/колесом. Прозрачная цена, без навязываний.
Even with all the resources available, health knowledge can feel superficial.
Health messages emphasize speed and ease rather than understanding.
As a result, many are left unsure which signals truly matter.
Every system interacts in ways that are highly personal.
Dialogue is more effective than instructions.
In our Medix Podcast conversations, we often explore these subtle signals of well-being.
Discussion allows health topics to breathe and unfold naturally.
Personal experience and scientific knowledge intersect naturally.
Listeners are encouraged to explore, question, and engage.
If meaningful dialogue resonates more than quick fixes.
To gain insight through thoughtful dialogue.
Connecting knowledge, experience, and self-observation.
Curious to hear how these ideas unfold through real dialogue?
Dive into a rich, insight-driven exploration of drugs name list.
Full Version at the Link: https://adambernards.co.uk/wp-content/wpages/?how-to-improve-your-strategy-in-online-poker.html
The best of the best: https://kelinci168.net/buy-established-instagram-profiles-yahoo-advertisements-to-have-accountants-best-book-for-cpas-accountants-2025/
Personalized summary: https://radhavatika.ac.in/pages/how-to-wager-bonuses-important-details.html
Нужна косметика? каталог корейской косметики большой выбор оригинальных средств K-beauty. Уход для всех типов кожи, новинки и хиты продаж. Поможем подобрать продукты, выгодные цены, акции и оперативная доставка по Алматы.
Сфера недропользования — это направление деятельности, связанный с разработкой подземных богатств.
Оно включает разведку природных ресурсов и их промышленное освоение.
Эта отрасль регулируется установленными правилами, направленными на безопасность работ.
Ответственное ведение работ в недропользовании обеспечивает устойчивое развитие.
общество экспертов России по недропользованию
Давно использую кракен маркет даркнет для покупок и ни разу не было проблем
1xbet g?ncel 1xbet g?ncel .
Нужна топлевная крата? https://oilguru.ru: заправка на сетевых АЗС, единый счет, прозрачный учет топлива и онлайн-контроль расходов. Удобное решение для компаний с собственным автопарком.
Русские подарки купить в интернет-магазине Москвы: сувениры, ремесленные изделия и подарочные наборы с национальным колоритом. Идеальные решения для праздников, гостей и корпоративных подарков.
Today’s Summary: inverted hammer explained: a complete guide for crypto and prop traders
1x bet giri? 1xbet-yeni-giris-2.com .
Казино Atom это современный онлайн формат азартных игр. Удобный вход и рабочее зеркало всегда доступны. Бонус казино Atom позволяет начать выгодно. Заходи сейчас – атом казино официальный сайт
новости про машины avtonovosti-4.ru .
дизайн ванной комнаты в доме дизайн коттеджа
журнал о машинах журнал о машинах .
Do you do music? tracing music notes worksheet for children and aspiring musicians. Educational materials, activities, and creative coloring pages to develop ear training, rhythm, and an interest in music.
журнал про автомобили avto-zhurnal-1.ru .
журнал автомобильный avto-zhurnal-2.ru .
статьи об авто статьи об авто .
отзывы и рейтинги отзывы и рейтинги .
все включено туры дешево tury-i-puteshestviya-promokody-i-skidki.ru .
купоны на авиабилеты купоны на авиабилеты .
туры в египет скидки туры в египет скидки .
авто новости avto-zhurnal-4.ru .
Когда нужен надежный игровой клуб стоит выбрать Kush казино официальный сайт. Быстрый вход и регулярные бонусы. Удобная регистрация для новых игроков. Начни играть сегодня: kush казино бонусы
https://svobodapress.com.ua/karta-dnipra/
онлайн накрутка инстаграма накрутка подписчиков вк
журнал о машинах журнал о машинах .
скидка на тур от туроператора tury-i-puteshestviya-promokody-i-skidki-1.ru .
горящие туры москва горящие туры москва .
domeo отзывы реальных domeo-reviews.com .
туры с детьми специальные предложения tury-i-puteshestviya-promokody-i-skidki-2.ru .
журнал про автомобили журнал про автомобили .
автомобильный журнал avto-zhurnal-1.ru .
помощь в написании диплома
https://dogs-academia.ru/
журнал автомобильный журнал автомобильный .
https://svobodapress.com.ua/karta-myronivky/
статьи про автомобили avto-zhurnal-3.ru .
промокоды aviasales промокоды aviasales .
промокоды туры путешествия tury-i-puteshestviya-promokody-i-skidki.ru .
domeo скачать отзывы domeo-reviews.com .
промокоды на бронирование отелей промокоды на бронирование отелей .
авто новости avto-zhurnal-1.ru .
журнал про автомобили журнал про автомобили .
журнал про автомобили журнал про автомобили .
Куш казино официальный сайт подходит для комфортной игры онлайн. Регистрация проходит быстро. Вход без ограничений. Начни играть прямо сейчас: kush бонусы
дизайн проект квартиры дизайн двухкомнатной квартиры 54 кв
автомобильная газета avto-zhurnal-3.ru .
domeo отзывы 2025 domeo-reviews.com .
горящие туры москва горящие туры москва .
скидка на авиабилеты онлайн tury-i-puteshestviya-promokody-i-skidki.ru .
промокоды на отели скидка промокоды на отели скидка .
журнал авто журнал авто .
журналы автомобильные avto-zhurnal-2.ru .
авто журнал авто журнал .
журнал автомобильный avto-zhurnal-3.ru .
domeo реальные отзывы domeo реальные отзывы .
туры в египет скидки tury-i-puteshestviya-promokody-i-skidki-1.ru .
экскурсии и туры со скидками tury-i-puteshestviya-promokody-i-skidki.ru .
скидки гостиницы tury-i-puteshestviya-promokody-i-skidki-2.ru .
авто журнал авто журнал .
новости про машины avto-zhurnal-2.ru .
журнал про машины журнал про машины .
Кактус казино вход это простой доступ к азартным играм и бонусам. Официальный сайт работает стабильно. Регистрация быстрая. Заходи и начинай игру, cactus casino сайт
бронирование отелей со скидкой бронирование отелей со скидкой .
школы дистанционного обучения shkola-onlajn-21.ru .
умные шторы купить умные шторы купить .
рулонные шторы с электроприводом на пластиковые окна rulonnye-shtory-s-elektroprivodom50.ru .
электрокарнизы в москве электрокарнизы в москве .
ОЭРН – профессиональная платформа для верификации статуса и компетенций специалистов по экспертизе недр. Платформа помогает выбрать специалиста по направлениям: ТПИ, геология и ГРР, нефть и газ – и сократить риски при подписании отчетов и отчетов в тендерах, https://oern2007.ru/
Кактус казино официальный сайт это быстрый старт и бонусы для новых игроков. Регистрация занимает несколько минут. Вход доступен круглосуточно. Заходи и играй – cactus казино официальный сайт
скидка на первое бронирование отеля скидка на первое бронирование отеля .
Индивидуалки Сургута
школа дистанционного обучения shkola-onlajn-21.ru .
электрокарнизы цена электрокарнизы цена .
электронные шторы электронные шторы .
рулонная штора на заказ цена rulonnye-shtory-s-elektroprivodom50.ru .
Лучшие и безопасные противопожарные емкости резервуары эффективное решение для систем пожарной безопасности. Проектирование, производство и монтаж резервуаров для хранения воды в соответствии с требованиями нормативов.
Индивидуалки Сургута
трансфер аэропорт скидка трансфер аэропорт скидка .
лбс это shkola-onlajn-21.ru .
рольшторы с электроприводом рольшторы с электроприводом .
электропривод для штор prokarniz24.ru .
автоматические карнизы для штор автоматические карнизы для штор .
Слив курсов ЕГЭ история https://courses-ege.ru
ОЭРН – профессиональная платформа для оценки компетенций и статуса специалистов по экспертизе недр. Ресурс упрощает выбрать специалиста по направлениям: геология и ГРР, ТПИ, нефть и газ и уменьшить риски при согласовании отчётов и отчетов в сделках https://oern2007.ru/
промокоды booking.com промокоды booking.com .
Подземный топливный резервуар https://underground-reservoirs.ru
школа дистанционного обучения shkola-onlajn-21.ru .
рулонные шторы на большие окна рулонные шторы на большие окна .
карниз для штор с электроприводом prokarniz24.ru .
электрокарниз двухрядный цена электрокарниз двухрядный цена .
прямые рейсы промокоды tury-i-puteshestviya-promokody-i-skidki-3.ru .
lomonosov school lomonosov school .
рулонные шторы на панорамные окна рулонные шторы на панорамные окна .
гибкие электрические шторы prokarniz24.ru .
карниз электроприводом штор купить prokarniz38.ru .
Лучшее казино https://download-vavada.ru слоты, настольные игры и live-казино онлайн. Простая навигация, стабильная работа платформы и доступ к играм в любое время без установки дополнительных программ.
школьный класс с учениками школьный класс с учениками .
онлайн школа с 1 по 11 класс онлайн школа с 1 по 11 класс .
xNudes is an AI tool that changes the clothes in a photo to show a nude or altered version of the body. You just need to upload an image, and the tool will create a realistic, edited version within seconds. The tool works by letting you pick details like age, body type, and skin tone to match your preferences. It gives you control over the image look, making the experience more personal https://xnudes.app/
Оформление вида на жительство в другой стране имеет большое преимущество.
Этот статус даёт право на длительное проживание в нужной стране.
пенсия по потере кормильца хуем
Такое разрешение гарантирует полный доступ к национальному здравоохранительному обслуживанию.
Наличие ВНЖ значительно упрощает процесс банковского сотрудничества и открытия бизнеса.
Таким образом, данное удостоверение является первым этапом к ПМЖ или возможно второму гражданству.
https://бумажные-пакеты-с-логотипом.рф/
Играешь в казино? https://freespinsbonus.ru бесплатные вращения в слотах, бонусы для новых игроков и действующие акции. Актуальные бонусы и предложения онлайн-казино.
ломоносов школа ломоносов школа .
дистанционное обучение 10-11 класс shkola-onlajn-22.ru .
https://t.me/sex_vladivostoka/
Проститутки Новый Уренгой
школа онлайн школа онлайн .
Проститутки Владивосток
московская школа онлайн обучение shkola-onlajn-22.ru .
Всегда проявляйте бдительность и здоровый скептицизм к неожиданным предложениям.
Никогда не кликайте по незнакомым гиперссылкам в письмах от неизвестных отправителей.
Внимательно изучайте подлинность сайтов и организаций перед совершением платежа.
https://migul-viktoria-shahraika.blogspot.com/2026/01/blog-post.html
Никому не сообщайте личные сведения, вроде коды или данные банковских карт, по телефону.
Используйте двухэтапную аутентификацию для безопасности своих ключевых аккаунтов.
Периодически проверяйте выписки со своих финансовых счетов на наличие подозрительных операций.
Устанавливайте надежные защитные программы и актуализируйте их регулярно.
https://t.me/nur_intim
полотенцесушитель водяной см полотенцесушители водяные для ванны
дистанционное школьное образование shkola-onlajn-23.ru .
онлайн школа для детей онлайн школа для детей .
интернет-школа интернет-школа .
дистанционное школьное обучение дистанционное школьное обучение .
гардина с электроприводом elektrokarniz25.ru .
карниз с приводом elektrokarnizy750.ru .
электрокарнизы москва электрокарнизы москва .
карниз электроприводом штор купить elektrokarniz5.ru .
электрокарнизы для штор купить в москве электрокарнизы для штор купить в москве .
курсы стриминг shkola-onlajn-23.ru .
дайсон выпрямитель купить воронеж дайсон выпрямитель купить воронеж .
пансионат для детей пансионат для детей .
Фриспины бесплатно https://casino-bonuses.ru бесплатные вращения в онлайн-казино без пополнения счета. Актуальные предложения, условия получения и список казино с бонусами для новых игроков.
карниз электро elektrokarniz25.ru .
онлайн-школа для детей онлайн-школа для детей .
дистанционное обучение 1 класс дистанционное обучение 1 класс .
электрокарнизы в москве электрокарнизы в москве .
электрокарнизы для штор цена электрокарнизы для штор цена .
электрический карниз для штор купить elektrokarnizy-dlya-shtor1.ru .
События в мире новостной портал события дня и аналитика. Актуальная информация о России и мире с постоянными обновлениями.
карниз с электроприводом карниз с электроприводом .
выпрямитель дайсон airstrait выпрямитель дайсон airstrait .
электрические карнизы купить электрические карнизы купить .
курсы стриминг курсы стриминг .
электрокарнизы elektrokarniz5.ru .
школа онлайн школа онлайн .
карниз с приводом для штор elektrokarnizy750.ru .
Тренды в строительстве заборов https://otoplenie-expert.com/stroitelstvo/trendy-v-stroitelstve-zaborov-dlya-dachi-v-2026-godu-sovety-po-vyboru-i-ustanovke.html для дачи в 2026 году: популярные материалы, современные конструкции и практичные решения. Советы по выбору забора и правильной установке с учетом бюджета и участка.
карнизы для штор купить в москве elektrokarnizy-dlya-shtor1.ru .
карниз электроприводом штор купить karnizy-s-elektroprivodom77.ru .
выпрямитель дайсон купить в москве выпрямитель дайсон купить в москве .
Отвод воды от фундамента https://totalarch.com/kak-pravilno-otvesti-vodu-ot-fundamenta-livnevka-svoimi-rukami-i-glavnye-zabluzhdeniya какие системы дренажа использовать, как правильно сделать отмостку и избежать подтопления. Пошаговые рекомендации для частного дома и дачи.
электрокарнизы купить в москве электрокарнизы купить в москве .
электрические жалюзи электрические жалюзи .
электрокарниз купить elektrokarnizy797.ru .
электрические жалюзи на пластиковые окна цена zhalyuzi-s-elektroprivodom7.ru .
карниз для штор с электроприводом карниз для штор с электроприводом .
электрокарнизы для штор купить в москве электрокарнизы для штор купить в москве .
электрокарниз двухрядный электрокарниз двухрядный .
дистанционное школьное образование дистанционное школьное образование .
Металлические конструкции для складов проектируются с учетом возможности дальнейшей модернизации. Производство позволяет адаптировать системы под рост бизнеса. Это снижает затраты при расширении складских площадей, https://www.met-izdeliya.com/
школа дистанционного обучения школа дистанционного обучения .
карнизы с электроприводом elektrokarnizy-dlya-shtor1.ru .
Diversify your approach; don’t just buy tiktok views for every post—reserve boosts for your strongest content and let the algorithm evaluate your regular uploads organically.
электрокарнизы для штор цена электрокарнизы для штор цена .
Если ты готов перейти от временных решений к стабильному формату заработка, контрактная служба дает четкую структуру дохода и защиту условий. Все выплаты прозрачны и регулярны. Начни оформление и сделай шаг вперед. Подробное описание по ссылке, служба по контракту без сво
фен выпрямитель дайсон airstrait dsn-vypryamitel-8.ru .
Контрактная служба – решение для тех, кто устал ждать. Доход начисляется регулярно. Условия известны заранее. Начни сейчас – льготы участникам сво янао
карниз с приводом для штор elektrokarniz5.ru .
электрические карнизы для штор в москве электрические карнизы для штор в москве .
карниз с приводом для штор elektrokarnizy750.ru .
автоматические жалюзи заказать автоматические жалюзи заказать .
электрокарниз двухрядный цена электрокарниз двухрядный цена .
класс с учениками класс с учениками .
дистанционное обучение 1 класс дистанционное обучение 1 класс .
Халява в казино https://casino-bonus-bezdep.ru Бесплатные вращения в популярных слотах, актуальные акции и подробные условия использования.
автоматические карнизы автоматические карнизы .
выпрямитель dyson airstrait dsn-vypryamitel-8.ru .
карнизы для штор с электроприводом karnizy-s-elektroprivodom77.ru .
карниз для штор электрический elektrokarnizy797.ru .
устройство рулонных штор rulonnye-shtory-s-elektroprivodom90.ru .
дистанционное школьное образование дистанционное школьное образование .
жалюзи с электроприводом для окон заказать жалюзи с электроприводом для окон заказать .
Dressing well creates a strong first impression.
A attire speaks volumes before you actually speak a word.
This boosts your personal confidence and mindset noticeably.
A put-together look conveys competence in the workplace.
https://a2.gucci1.ru/oDELez9r49OM/
Stylish choices allow you to express your unique identity.
People often perceive well-dressed individuals as more capable and reliable.
Therefore, investing in your style is an investment in your personal brand.
карниз электроприводом штор купить elektrokarniz-nedorogo.ru .
Изготовление стеллажных систем под ключ позволяет заказчику сократить время запуска склада. Мы берем на себя проектирование и производство. Готовые конструкции поставляются в согласованные сроки. Это упрощает реализацию проекта – глубинные стеллажи
электронный карниз для штор elektrokarnizy797.ru .
lbs это lbs это .
рулонные электрошторы rulonnye-shtory-s-elektroprivodom90.ru .
автоматические жалюзи с электроприводом цена автоматические жалюзи с электроприводом цена .
электрокарниз elektrokarniz-nedorogo.ru .
электрокарнизы цена электрокарнизы цена .
онлайн обучение для детей онлайн обучение для детей .
рулонная штора автоматическая rulonnye-shtory-s-elektroprivodom90.ru .
карнизы с электроприводом купить elektrokarniz-nedorogo.ru .
рулонные жалюзи на пластиковые окна купить рулонные жалюзи на пластиковые окна купить .
карнизы с электроприводом купить karniz-elektroprivodom.ru .
рулонные шторы с электроприводом купить в москве rulonnaya-shtora-s-elektroprivodom.ru .
электронное управление жалюзи zhalyuzi-s-elektroprivodom7.ru .
электрокранизы электрокранизы .
рулонные шторки на окна рулонные шторки на окна .
электрокарнизы для штор купить в москве электрокарнизы для штор купить в москве .
Looking stylish projects a positive first impression.
Your outfit communicates loudly before a person actually say a word.
It enhances your own confidence and mood significantly.
A put-together look conveys competence in the workplace.
https://b2.hypebeasts.ru/EtyHNQba8/
Stylish choices allow you to express your individual personality.
People often judge stylish individuals as more capable and reliable.
Ultimately, investing in your wardrobe is an valuable step in your personal brand.
ролл штора на пластиковое окно rulonnaya-shtora-s-elektroprivodom.ru .
гардина с электроприводом karniz-elektroprivodom.ru .
пластиковые окна рулонные шторы с электроприводом rulonnaya-shtora-s-elektroprivodom.ru .
карниз с приводом karniz-elektroprivodom.ru .
?esk? casino online casino-cz-1.com .
накрутка подписчиков онлайн накрутка подписчиков в тик ток
Занимаешься спортом? https://bliny-trenirovochnye.ru диски для пауэрлифтинга, бодибилдинга и фитнеса. Прочные покрытия, стандартные размеры и широкий выбор весов.
free spiny za registraci casino-cz-1.com .
?esk? online casino ?esk? online casino .
Осваиваешь арбитраж? https://corsairmedia.ru поможет разобраться в инструментах, выбрать первую партнерку и избежать типичных ошибок новичков. Подробные обзоры от практиков: плюсы, минусы и реальные цифры заработка без воды.
casino bonus za registraci casino-cz-1.com .
Лучшее онлайн казино? pokerok онлайн-покер, турниры и кэш-игры для игроков разного уровня. Удобный интерфейс, доступ с ПК и мобильных устройств, регулярные события и акции.
Офсетная полиграфия — самый популярный способ коммерческой печати.
Цифровая печать отлично подходит для небольших заказов и персонализации.
Трафаретная печать активно используется для нанесения на текстиль и нестандартные материалы.
https://vocal.media/authors/printing-house-64wub032w
Флексопечать используется в основном для гибкой упаковки и изготовления этикеток.
При внешней агитации часто заказывают широкоформатную печать на постерах.
Отделочная доводка содержит такие этапы, как биговка, тиснение и фальцовка.
Нужен стим аккаунт? tgram.link/apps/burger-game-obshhie-akkaunty-steam-besplatnyj-dostup-k-igram-v-telegram-2026 доступ к библиотеке игр по выгодной цене. Совместное использование, подробные условия, инструкции по входу и рекомендации для комфортной игры.
cz casino cz casino .
Кент казино подходит для игроков с разным уровнем опыта. Новички быстро осваиваются благодаря логичной структуре сайта. Опытные пользователи ценят разнообразие игр и стабильную работу платформы: кент казино промокод
Здарова народ!
Нашел полезную статью.
Думаю, многим будет полезно.
Линк:
блэкспрут ссылка тор
Как вам?
Онлайн платформа Kent casino сочетает современный дизайн и функциональность. Интерфейс не перегружен лишними элементами, а все основные разделы находятся под рукой. Это упрощает навигацию и делает игру более приятной – кент казино зеркало
Авторский блог https://blogger-tolstoy.ru о продвижении в Телеграм. Свежие гайды, проверенные стратегии и полезные советы по раскрутке каналов, чатов и ботов. Подробно о том, как увеличить аудиторию, повысить вовлеченность и эффективно монетизировать проекты в мессенджере Telegram.
Казино 7к ориентировано на игроков, которые ценят простоту и стабильность. Платформа не требует длительного изучения интерфейса. Все основные функции находятся на виду. Такой подход экономит время – 7k casino зеркало на сегодня
практическая косметология центр косметологии
Доброго времени суток.
Нарыл полезную статью.
Решил поделиться.
Подробности здесь:
Всем удачи!
Казино 7к предоставляет доступ к разнообразным азартным развлечениям в онлайн формате. Пользователи могут играть без привязки к месту и времени. Платформа корректно работает на мобильных устройствах. Это расширяет возможности для игроков, 7к казино
Погрузитесь в мир кино https://zonefilm.media с нашим онлайн-кинотеатром! Здесь каждый найдет фильмы для себя: от захватывающих блокбастеров и трогательных драм до мультфильмов для всей семьи. Удобный интерфейс, возможность смотреть онлайн на любом устройстве и постоянно обновляемая библиотека! Присоединяйтесь и наслаждайтесь!
Нужен сувенир или подарок? логотипы подарки и сувениры для компаний и мероприятий. Бизнес-сувениры, подарочные наборы и рекламная продукция с персонализацией и доставкой.
Нужна бытовая химия? купить бытовую химию моющие и чистящие средства, порошки и гели. Удобный заказ онлайн, акции и доставка по городу и регионам.
Бытовая химия с доставкой бытовая химия оптом средства для уборки, стирки и ухода за домом. Широкий ассортимент, доступные цены и удобная оплата.
UEFA Champions League https://sampiyonlar-ligi.com.az matches, results, and live scores. See the schedule, standings, and draw for Europe’s premier club competition.
Free online games 1001 com az for your phone and computer. Easy navigation, quick start, and a variety of genres with no downloads required.
automaty online automaty online .
Turkish Super League super-lig standings, match results, and live online scores. Game schedule and up-to-date team statistics.
nejlep?? online casina nejlep?? online casina .
Приветствую форумчан.
Увидел любопытную инфу.
Может кому пригодится.
Вот ссылка:
актуальные зеркала kraken
Вроде норм.
casino bonus za registraci casino-cz-18.com .
?esk? online casina ?esk? online casina .
cz online casina cz online casina .
casino bonus bez vkladu casino bonus bez vkladu .
leg?ln? online casino leg?ln? online casino .
casino hry online casino-cz-15.com .
mostbet onlayn mostbet69573.help
Здарова народ!
Нарыл любопытную информацию.
Думаю, многим будет полезно.
Смотрите тут:
Mega darknet
Как вам?
1win даромадан намешавад 1win даромадан намешавад
1win минимали хуруҷ http://1win71839.help/
mostbet bonus bekor qilish mostbet69573.help
mostbet обновить приложение http://www.mostbet46809.help
mostbet bonus qoidalari https://mostbet69573.help
1win лайв казино мобилӣ https://1win71839.help/
мостбет официальный сайт регистрация мостбет официальный сайт регистрация
mostbet cheklov qo‘yish mostbet69573.help
mostbet скачать без регистрации mostbet скачать без регистрации
Мы публикуем обзоры модных коллекций, советы по уходу за кожей и рекомендации по укреплению здоровья. Раздел о детях наполнен практичными материалами для родителей. Переходите по ссылке и читайте больше https://universewomen.ru/
мостбет промокод при регистрации http://mostbet46809.help/
Мы уделяем внимание каждому аспекту жизни современной женщины. В нашем журнале сочетаются мода, материнство, красота и психологическое благополучие. Переходите по ссылке https://universewomen.ru/
mostbet verifikatsiyasiz yechish mostbet69573.help
mostbet пополнение visa mostbet пополнение visa
1win насб аз манбаъҳои номаълум 1win71839.help
воридшавӣ 1вин https://1win71839.help
trezviy-vibor http://samatiha.ru/anonimnyj-narkolog-na-dom-v-krasnodare-kak-vybrat-sluzhbu-i-ne-oshibitsya/ .
Шоурумы Москвы помогают формировать осознанный гардероб, где каждая вещь продумана и легко сочетается с другими элементами. Такой подход снижает количество импульсивных покупок. Узнать больше можно по ссылке http://showkomplekt.ru/forum/user/41448/
pin-up hokkey mərc pinup21680.help
pin-up necə daxil olmaq olar http://pinup21680.help
Трезвый выбор http://xn--80acbhftsxotj0d8c.xn--p1ai/vyvod-iz-zapoya-v-peterburge// .
mostbet aviator стратегия https://mostbet20394.help/
мостбет crash на деньги мостбет crash на деньги
pin-up Kapital Bank pin-up Kapital Bank
pin-up canlı mərc necə http://pinup21680.help
mostbet ставки Кыргызстан mostbet ставки Кыргызстан
Посещение шоурума в Москве часто сопровождается консультацией по цветотипу и особенностям фигуры. Это позволяет подобрать вещи, которые действительно украшают и подчеркивают достоинства. Подробнее по ссылке, http://skazka.g-talk.ru/viewtopic.php?f=1&t=7810
Медицинский сайт https://nogostop.ru об анатомии, патологиях и способах лечения. Симптомы, профилактика, современные препараты и рекомендации врачей в доступной форме.
pin-up aviator demo qeydiyyatsız http://pinup21680.help/
Свежие новости https://plometei.ru России и мира — оперативные публикации, экспертные обзоры и важные события. Будьте в курсе главных изменений в стране и за рубежом.
trezviy vibor http://www.facewoman.ru/vyvod-iz-zapoya-v-donecke.html .
Информационный портал https://diok.ru о событиях в мире, экономике, науке, автомобильной индустрии и обществе. Аналитика, обзоры и ключевые тенденции.
шумоизоляция арок авто https://shumoizolyaciya-arok-avto-77.ru
выездной шиномонтаж в москве круглосуточно https://vyezdnoj-shinomontazh-77.ru
1win авиатор коэффициенты 1win авиатор коэффициенты
1вин ставки https://1win70163.help/
мостбет mines на деньги https://mostbet20394.help
Трезвый выбор https://drplas.ru/blefaroplastika/reabilitatsiya/narkolog-na-dom-v-volgograde.html .
1win фриспины http://1win70163.help/
В столице шоурумы открывают новые возможности для знакомства с локальными брендами и авторскими коллекциями. Это пространство, где дизайнеры могут напрямую общаться с клиентами и рассказывать о философии своих коллекций. Такой формат делает моду более живой. Подробности по ссылке http://witchvswinx.getbb.ru/viewtopic.php?f=10&t=8213
1win как пополнить через мегапей [url=https://1win70163.help/]https://1win70163.help/[/url]
реконструкция завода rekonstrukcziya-zdanij-2.ru .
Сайт о фермерстве https://webferma.com и садоводстве: посадка, удобрения, защита растений, теплицы и разведение животных. Полезные инструкции и современные агротехнологии.
1вин депозит https://1win70163.help
Новости и обзоры https://mechfac.ru о мире технологий, экономики, крипторынка, культуры и шоу-бизнеса. Всё, что важно знать о современном обществе.
усиление конструкций здания усиление конструкций здания .
Новостной портал https://webof-sar.ru свежие события России и мира, политика, экономика, общество, технологии и культура. Оперативные публикации и аналитика каждый день.
Онлайн новостной портал https://parnas42.ru с актуальными новостями, экспертными комментариями и главными событиями дня. Быстро, объективно и по существу.
мостбет почта поддержки http://www.mostbet20394.help
Московские шоурумы активно работают с молодыми дизайнерами, открывая новые имена в индустрии моды. Это делает ассортимент свежим и нестандартным. Подробности по ссылке https://rabotavinternete.forum2x2.ru/t56323-topic#140108
армированный бетон армированный бетон .
mostbet oglinda curenta mostbet42873.help
Мировые новости https://m-stroganov.ru о технологиях и криптовалютах, здоровье и происшествиях, путешествиях и туризме. Свежие публикации и экспертные обзоры каждый день.
Все подробности по ссылке: https://parfum-mir.ru/internet-magazin/product/21226621/
mostbet cum activez bonusul http://mostbet42873.help
1win блэкджек https://www.1win79230.help
1win как пройти верификацию https://1win79230.help
mostbet conditii bonus mostbet conditii bonus
mostbet link nou http://mostbet42873.help/
слоты 1win https://www.1win79230.help
cum primesc bonus la mostbet http://mostbet42873.help/
Интересует бьюти индустрия? курсы косметологии вакансии косметолога, массажиста, мастера маникюра, шугаринга, ресниц, бровиста, колориста и администратора салона красоты. Курсы для бьюти мастеров, онлайн обучение и сертификаты.
Планируешь ремонт? ремонт ванной комнаты в новостройке от косметического обновления до капитальной перепланировки. Индивидуальный подход, современные технологии и официальное оформление договора.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
1вин пополнение 1вин пополнение
1win лайв расчет 1win лайв расчет
1win вывод на элсом сколько идет http://www.1win04381.help
1win регистрация Киргизия https://1win04381.help
1win поддержка кыргызча http://1win04381.help/
1win пополнение Demir через приложение http://www.1win79230.help
куплю курсовую работу куплю курсовую работу .
1win авторизация 1win04381.help
1win установить приложение http://1win08754.help/
заказать студенческую работу заказать студенческую работу .
1win налоги на выигрыш Кыргызстан https://1win08754.help/
1вин 1вин
1win Хуҷанд https://www.1win93047.help
1win приложение Киргизия 1win приложение Киргизия
1win lucky jet https://www.1win93047.help
заказать дипломную работу в москве заказать дипломную работу в москве .
1win дар 1win сабти ном http://1win93047.help/
1win шиноснома тасдиқ https://www.1win93047.help
что случилось с втб онлайн http://vtb-ne-rabotaet.ru/ .
курсовая работа на заказ цена курсовая работа на заказ цена .
sms activator linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre .
sms activate alternatives sms activate alternatives .
smsactivate smsactivate .
sms activator github.com/sms-activate-alternatives .
1вин бақайдгирӣ 1win93047.help
написание курсовой работы на заказ цена kupit-kursovuyu-68.ru .
курсовой проект цена kupit-kursovuyu-67.ru .
помощь в написании курсовой помощь в написании курсовой .
реферат через нейросеть реферат через нейросеть .
заказать курсовую заказать курсовую .
1win приложение для айфон 1win08754.help
написание курсовой на заказ цена написание курсовой на заказ цена .
sms activation github.com/sms-activate-alternatives .
top sms activate services http://www.linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre .
sms activate sms activate .
sms activate website sms activate website .
курсовые под заказ курсовые под заказ .
melbet aplicatie melbet aplicatie
заказать студенческую работу заказать студенческую работу .
реферат нейросеть реферат нейросеть .
заказать курсовую работу заказать курсовую работу .
mostbet купон https://mostbet73152.help
написание курсовых на заказ написание курсовых на заказ .
sms activate sms activate .
1win пополнение Demir через приложение https://1win48762.help
выполнение курсовых выполнение курсовых .
нейросеть онлайн для учебы nejroset-dlya-ucheby.ru .
1win промокод на бонус http://1win48762.help
1win статистика https://1win48762.help/
mines игра mostbet https://www.mostbet73152.help
заказать курсовую срочно заказать курсовую срочно .
нейросеть для студентов онлайн nejroset-dlya-ucheby.ru .
mostbet войти https://mostbet73152.help
нейросеть студент бот нейросеть студент бот .
цена курсовой работы цена курсовой работы .
сайт для заказа курсовых работ сайт для заказа курсовых работ .
top sms activate services github.com/sms-activate-login .
мостбет ставки регистрация https://mostbet84736.help/
выполнение курсовых выполнение курсовых .
top sms activate services github.com/sms-activate-alternatives .
mostbet доступ к сайту http://mostbet73152.help
sms activate login http://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre .
мостбет мобильная версия мостбет мобильная версия
sms activate service sms activate service .
мостбет_kz https://mostbet73152.help
mostbet crash 2026 mostbet crash 2026
mostbet личный кабинет mostbet личный кабинет
mostbet вывод на банковскую карту Кыргызстан mostbet вывод на банковскую карту Кыргызстан
ии для студентов nejroset-dlya-ucheby-2.ru .
заказать курсовую работу качественно заказать курсовую работу качественно .
sms activate sms activate .
smsactivate smsactivate .
sms activator http://linkedin.com/pulse/top-5-sms-activate-services-ultimate-guide-virtual-phone-mike-davis-gnhre/ .
заказать курсовую работу заказать курсовую работу .
мостбет обход блокировки https://mostbet84736.help/
написать курсовую на заказ kupit-kursovuyu-67.ru .
нейросеть для рефератов нейросеть для рефератов .
1win Бишкек кирүү 1win Бишкек кирүү
aviator игра mostbet http://mostbet39571.help
сайт для рефератов сайт для рефератов .
помощь в написании курсовой kupit-kursovuyu-67.ru .
мостбет лицензия https://www.mostbet39571.help
1win скачать без вирусов 1win48762.help
1win download 1win5769.help
1win kirish havola https://www.1win5769.help
мостбет доступ сегодня мостбет доступ сегодня
1вин сайт кор намекунад https://www.1win59278.help
1win оинаи корӣ http://www.1win59278.help
1win kirish havola https://www.1win5769.help
1win apk android http://1win5769.help/
1win регистрация кардан https://1win59278.help
1win mines signal https://1win5769.help
pinup yangi mirror pinup yangi mirror
mostbet lucky jet коэффициенты https://mostbet39571.help/
нейросеть онлайн для учебы nejroset-dlya-ucheby-2.ru .
pin-up samsung uchun apk pinup91324.help
pin-up karta bog‘lash http://www.pinup63481.help
pin-up Xorazm pin-up Xorazm
1win маҳдудият http://1win59278.help/
pin-up slotlar real pul pin-up slotlar real pul
pin up Buxoro http://pinup63481.help
мостбет контакты http://mostbet72413.help
мостбет скачать приложение на android https://mostbet72413.help/
pin up pul kiritish pin up pul kiritish
промокоди 1вин https://1win59278.help/
мостбет зеркало сегодня https://mostbet72413.help/
мостбет вход на сайт http://mostbet72413.help
mostbet проверка документов http://mostbet72413.help/
pin up haftalik bonus http://pinup63481.help
1win ставки на баскетбол Кыргызстан 1win ставки на баскетбол Кыргызстан
1win правила казино https://1win52609.help/
1win приложение ios 1win приложение ios
pin up telegram bormi pin up telegram bormi
lucky jet мостбет lucky jet мостбет
mostbet plinko стратегия https://mostbet26148.help/
1win как установить apk http://1win50742.help
1win mBank вывод http://www.1win50742.help
мостбет ставки на киберспорт Кыргызстан http://mostbet26148.help/
1win contact Republica Moldova 1win5807.help
1win официальный apk http://1win50742.help/
1win регистрация аккаунта 1win50742.help
мостбет Талас http://www.mostbet26148.help
1вин зеркало Бишкек 1вин зеркало Бишкек
Приветствую! Очень актуальная тема — что должен обещать подрядчик. Здесь такой момент: без гарантии — рискуешь. Дают обязательства: монтаж мембранной кровли. Лично я считаю: минимум 5-летние обязательства — признак профессионалов. Короче гарантия меньше 3 лет — то есть что-то не так. Основные этапы: фиксируй гарантию. Вместо заключения: высокоэффективный инструмент — спишь спокойно.
шумоизоляция авто
mostbet ставки на спорт 2026 mostbet ставки на спорт 2026
1win depunere Visa http://www.1win5807.help
ии для учебы студентов ии для учебы студентов .
1win киргизче расмий сайт https://1win52609.help
1win cont nou inregistrare http://1win5807.help
ии для студентов ии для студентов .
перепланировка квартир перепланировка квартир .
сделать реферат сделать реферат .
нейросеть реферат онлайн нейросеть реферат онлайн .
генерация nejroset-dlya-ucheby-5.ru .
мостбет Эсхата мостбет Эсхата
1win sloturi recomandate https://www.1win5807.help
1win пополнить баланс элсом https://1win52609.help/
сколько стоит согласование перепланировки skolko-stoit-uzakonit-pereplanirovku-8.ru .
мостбет бонуси 2026 http://mostbet43926.help/
нейросеть реферат нейросеть реферат .
нейросеть для рефератов нейросеть для рефератов .
мостбет гузоштани ставка мостбет гузоштани ставка
1win lucky jet pe mobil 1win lucky jet pe mobil
A convenient car catalog http://www.auto.ae/catalog/ brands, models, specifications, and current prices. Compare engines, fuel consumption, trim levels, and equipment to find the car that meets your needs.
mostbet официальный сайт https://mostbet43926.help/
мостбет бозии рулетка http://www.mostbet43926.help
мелбет официальный сайт скачать мелбет официальный сайт скачать .
проект перепланировки квартиры москва проект перепланировки квартиры москва .
мелбет официальный сайт зеркало мелбет официальный сайт зеркало .
внедрение 1с москва внедрение 1с москва .
melbet app download update version https://melbetmobi.ru .
melbet p2p пополнение melbet p2p пополнение
ranklio site – Pages loaded fast, images appeared sharp, and formatting stayed consistent.
leadnex site – Found practical insights today; sharing this article with colleagues later.
1win ios версия https://pharm.kg/
1win слоты на деньги http://pharm.kg
1win как пополнить DemirBank pharm.kg
1win рабочее зеркало Кыргызстан http://1win50742.help
1вин авиатор pharm.kg
1win обновить приложение pharm.kg
позиция карточки в выдаче позиция карточки в выдаче .
понижение уровня грунтовых вод иглофильтрами понижение уровня грунтовых вод иглофильтрами .
водопонижение скважинами водопонижение скважинами .
mostbet plinko коэффициенты http://mostbet61527.help/
водопонижение иглофильтрами водопонижение иглофильтрами .
рейтинг аккредитованных школ рейтинг аккредитованных школ .
система водопонижения система водопонижения .
водопонижение котлована иглофильтрами xn—77-eddkgagrc5cdhbap.xn--p1ai .
sms activate website sms activate website .
мелбет скачать мелбет скачать .
бурение водопонижение vodoponizhenie-iglofiltrami-moskva.ru .
сервис анализа креативов сервис анализа креативов .
1win free bet Moldova 1win free bet Moldova
1win bonus shartlari https://1win5767.help/
узаконивание перепланировки sostav.ru/blogs/286398/77663 .
sms activation github.com/SMS-Activate-Alternatives .
mostbet скачать бесплатно http://www.mostbet52718.help
sms activate login sms activate login .
top sms activate alternatives top sms activate alternatives .
descargar 1win ios méxico [url=1win5771.help]descargar 1win ios méxico[/url]
проект перепланировки квартиры проект перепланировки квартиры .
Vivo down Vivo down .
reacho – Loved the layout today; clean, simple, and genuinely user-friendly overall.
offerorbit – Navigation felt smooth, found everything quickly without any confusing steps.
promova – Pages loaded fast, images appeared sharp, and formatting stayed consistent.
rankora – Pages loaded fast, images appeared sharp, and formatting stayed consistent.
trendfunnel – Appreciate the typography choices; comfortable spacing improved my reading experience.
scaleify – Content reads clearly, helpful examples made concepts easy to grasp.
pinup mirror https://pinup37056.help
кухни на заказ питер kuhni-spb-41.ru .
pin-up android yüklə pulsuz pin-up android yüklə pulsuz
заказать кухню под ключ zakazat-kuhnyu-1.ru .
заказать кухню в интернете заказать кухню в интернете .
мелбет пополнение odengi http://melbet41263.help
согласование перепланировки квартиры москва согласование перепланировки квартиры москва .
профессиональная печать https://telegra.ph/kak-popast-v-gorodskoj-rejting-predprinimatelej-02-24 .
Казино фреш Казино фреш .
Рейтинг 10 лучших онлайн казино Рейтинг 10 лучших онлайн казино .
заказать кухню в интернете заказать кухню в интернете .
заказать кухню в интернете заказать кухню в интернете .
1вин краш https://www.1win19643.help
купить кухню на заказ спб kuhni-spb-44.ru .
провод 4 4 купить кабель электрический купить минск
Looking for a yacht? private sailing trips in Cyprus for unforgettable sea adventures. Charter luxury yachts, catamarans, or motorboats with or without crew. Explore crystal-clear waters, secluded bays, and iconic coastal locations in first-class comfort onboard.
stackhq – Navigation felt smooth, found everything quickly without any confusing steps.
cloudhq – Mobile version looks perfect; no glitches, fast scrolling, crisp text.
bytehq – Content reads clearly, helpful examples made concepts easy to grasp.
кухни под заказ кухни под заказ .
вызов нарколога на дом в ростове вызов нарколога на дом в ростове .
кухня по индивидуальному заказу спб kuhni-spb-42.ru .
kubeops – Bookmarked this immediately, planning to revisit for updates and inspiration.
внедрение 1с erp внедрение 1с erp .
cloudopsly – Bookmarked this immediately, planning to revisit for updates and inspiration.
For those seeking an exceptional online gaming experience, us.com](https://maxispin.us.com/) stands out as a premier destination. At Maxispin Casino, players can enjoy a vast array of pokies, table games, and other thrilling options, all accessible in both demo and real-money modes. The casino offers attractive bonuses, including free spins and a generous welcome offer, along with cashback promotions and engaging tournaments. To ensure a seamless experience, Maxispin provides various payment methods, efficient withdrawal processes, and reliable customer support through live chat. Security is a top priority, with robust safety measures and a strong focus on responsible gambling tools. Players can easily navigate the site, with detailed guides on account creation, verification, and payment methods. Whether you’re interested in high RTP slots, hold and win pokies, or the latest slot releases, Maxispin Casino delivers a user-friendly and secure platform. Explore their terms and conditions, read reviews, and discover why many consider Maxispin a legitimate and trustworthy choice in Australia.
Regardless of whether you’re an experienced copywriter or a newcomer, MaxiSpin.us.com offers the resources necessary to improve your content.
**Features of MaxiSpin.us.com**
Furthermore, the platform includes a powerful spin-text generator that enables users to effortlessly create unique content variations.
**Benefits of Using MaxiSpin.us.com**
With MaxiSpin.us.com, creating compelling content has never been easier or more efficient.
Опрятный внешний вид создает сильное впечатление о человеке.
Ваш образ влияет на оценку вас окружающими сразу.
Хорошее самочувствие в подобранном образе повышает вашу уверенность.
Этот подход подчеркивает высокий уровень профессионализма и внимание к мелочам.
https://r6.balmain1.ru/26e3VRHctXGQ/
Через гардероб вы имеете шанс выразить свою индивидуальность и стиль.
Окружающие неосознанно воспринимают опрятных индивидов как более успешных.
Следовательно, инвестиции в собственный образ — это вклад в свое будущее.
мостбет как пройти kyc http://mostbet39081.help
1win максимальный вывод http://1win91276.help/
keywordcraft – Pages loaded fast, images appeared sharp, and formatting stayed consistent.
нарколог на дом в ростове на дону нарколог на дом в ростове на дону .
melbet скачать приложение киргизия https://melbet76815.help
шумоизоляция торпеды
шумоизоляция дверей авто https://shumoizolyaciya-dverej-avto.ru
adscatalyst – Overall, professional vibe here; trustworthy, polished, and pleasantly minimal throughout.
clickrevamp – Found practical insights today; sharing this article with colleagues later.
promoseeder – Appreciate the typography choices; comfortable spacing improved my reading experience.
нарколог на дом ростов отзывы narkolog-na-dom-v-rostove-2.ru .
нарколог вывод из запоя в ростове нарколог вывод из запоя в ростове .
вывод из запоя в ростове на дону на дому вывод из запоя в ростове на дону на дому .
выезд нарколога на дом ростов-на-дону выезд нарколога на дом ростов-на-дону .
serpstudio – Loved the layout today; clean, simple, and genuinely user-friendly overall.
leadspike – Content reads clearly, helpful examples made concepts easy to grasp.
установка газового пожаротушения для промышленного объекта montazh-gazovogo-pozharotusheniya.ru .
нарколог на дом недорого ростов нарколог на дом недорого ростов .
вывод из запоя в ростове на дону на дому вывод из запоя в ростове на дону на дому .
trafficcrafter – Found practical insights today; sharing this article with colleagues later.
вывод из запоя в ростове-на-дону вывод из запоя в ростове-на-дону .
шаровой кран под приварку кран под приварку
нарколог вывод из запоя на дому в ростове vyvod-iz-zapoya-v-rostove-2.ru .
дешевые свадебные платья купить каталог свадебных платьев с ценами
melbet kgy https://melbet30926.help/
datadev – Pages loaded fast, images appeared sharp, and formatting stayed consistent.
applabs – Bookmarked this immediately, planning to revisit for updates and inspiration.
dataops – Loved the layout today; clean, simple, and genuinely user-friendly overall.
trycloudy – Loved the layout today; clean, simple, and genuinely user-friendly overall.
мелбет как играть в aviator https://melbet51923.help/
купить кабель 2 2 5 купить кабель минск
столбики ограждения с цепью мобильные стойки ограждения
gobyte – Navigation felt smooth, found everything quickly without any confusing steps.
getbyte – Loved the layout today; clean, simple, and genuinely user-friendly overall.
мелбет мбанк киргизия мелбет мбанк киргизия
usebyte – Color palette felt calming, nothing distracting, just focused, thoughtful design.
трафиковое продвижение сайта prodvizhenie-sajtov-po-trafiku6.ru .
реклама наркологической клиники реклама наркологической клиники .
заказать печать наклеек pechat-nakleek-v-moskve.ru .
продвижение по трафику без абонентской платы продвижение по трафику без абонентской платы .
сео центр seo-kejsy12.ru .
раскрутка сайта москва раскрутка сайта москва .
сео продвижение сайта по трафику сео продвижение сайта по трафику .
сео блог seo-blog16.ru .
блог о маркетинге блог о маркетинге .
продвижение по трафику без абонентской платы продвижение по трафику без абонентской платы .
мелстрой гейм казино мелстрой гейм казино .
getstackr – Found practical insights today; sharing this article with colleagues later.
заказать анализ сайта заказать анализ сайта .
cloudster – Pages loaded fast, images appeared sharp, and formatting stayed consistent.
usestackr – Found practical insights today; sharing this article with colleagues later.
deployly – Appreciate the typography choices; comfortable spacing improved my reading experience.
ремонт квартири які послуги ремонт квартир Львів
блог про seo блог про seo .
контекстная реклама статьи seo-blog15.ru .
интернет маркетинг статьи seo-blog14.ru .
Mario game online free super mario world play online
раскрутка сайта москва раскрутка сайта москва .
монтаж газового пожаротушения монтаж газового пожаротушения .
byteworks – Pages loaded fast, images appeared sharp, and formatting stayed consistent.
stackable – Loved the layout today; clean, simple, and genuinely user-friendly overall.
сео блог seo-blog16.ru .
заказать продвижение сайта в москве заказать продвижение сайта в москве .
mellstroy casino сайт mellstroy casino сайт .
оптимизация сайта блог seo-blog15.ru .
статьи про маркетинг и seo seo-blog14.ru .
WhatsApp caiu WhatsApp caiu .
глубокий комлексный аудит сайта глубокий комлексный аудит сайта .
melbet регистрация по номеру melbet регистрация по номеру
гибридная структура сайта seo-kejsy12.ru .
веб-аналитика блог веб-аналитика блог .
трафиковое продвижение сайта prodvizhenie-sajtov-po-trafiku6.ru .
seo продвижение трафику seo продвижение трафику .
dataworks – Pages loaded fast, images appeared sharp, and formatting stayed consistent.
контекстная реклама статьи seo-blog15.ru .
mellstroy game casino mellstroy game casino .
статьи про seo статьи про seo .
seo partners seo partners .
мостбет хоккей ставки http://mostbet15247.help
мостбет aviator на деньги http://mostbet96810.help
Ita? caiu caiu.site .
гибридная структура сайта seo-kejsy12.ru .
заказать кухню рассчитать стоимость zakazat-kuhnyu-2.ru .
seo по трафику seo по трафику .
статьи о маркетинге статьи о маркетинге .
seo информационных порталов prodvizhenie-sajtov-po-trafiku6.ru .
заказать кухню под заказ заказать кухню под заказ .
сео блог seo-blog15.ru .
блог про seo seo-blog14.ru .
мелстрой казино официальный мелстрой казино официальный .
успешные кейсы seo успешные кейсы seo .
сколько стоит заказать кухню по размерам zakazat-kuhnyu-2.ru .
мелбет ошибка регистрации melbet28175.help
Discover the thrill of real-money live casino action at best tablet for live dealer casino games, where you can enjoy live dealers, top software providers, and exclusive promotions.
The platform is built around a strong focus on safety and seamless user experience.
монтаж газового пожаротушения для склада montazh-gazovogo-pozharotusheniya-1.ru .
seo продвижение по трафику clover seo продвижение по трафику clover .
заказать кухню с доставкой zakazat-kuhnyu-3.ru .
раскрутка сайтов интернет prodvizhenie-sajtov-po-trafiku6.ru .
cryptora – Navigation felt smooth, found everything quickly without any confusing steps.
заказать кухню под заказ заказать кухню под заказ .
cloudiva – Color palette felt calming, nothing distracting, just focused, thoughtful design.
1win маҳдудият 1win83254.help
stackora – Content reads clearly, helpful examples made concepts easy to grasp.
netlance – Color palette felt calming, nothing distracting, just focused, thoughtful design.
заказать кухню под размеры заказать кухню под размеры .
devonic – Found practical insights today; sharing this article with colleagues later.
apponic – Navigation felt smooth, found everything quickly without any confusing steps.
мостбет приложение не работает https://www.mostbet76914.help
securia – Content reads clearly, helpful examples made concepts easy to grasp.
codefuse – Found practical insights today; sharing this article with colleagues later.
Проблемы с застройщиком? взыскание неустойки по дду юристы помощь юриста по долевому строительству, расчет неустойки, подготовка претензии и подача иска в суд. Защитим права дольщиков и поможем получить компенсацию.
бренды парфюмерии https://elicebeauty.com/parfyumeriya/filter/_m24_a247/
Нужен юрист? https://arbitrazhnyy-yurist.ru представительство в арбитражном суде, защита интересов бизнеса, взыскание задолженности, споры по договорам и сопровождение судебных процессов для компаний и предпринимателей.
Ищешь кран? кран приварной для трубопроводов различного назначения. Надежная запорная арматура для систем водоснабжения, отопления, газа и промышленных магистралей. Высокая герметичность, долговечность и устойчивость к нагрузкам.
джойказино сегодня официальное джойказино сегодня официальное .
1win depunere Skrill Moldova 1win depunere Skrill Moldova
mellstroy casino сайт mellstroy casino сайт .
джойказино рабочее на сегодня t.me/joy_casino_news .
заказать кухню заказать кухню .
большая кухня на заказ kuhni-spb-42.ru .
заказать кухню в интернете заказать кухню в интернете .
монтаж газового пожаротушения спб монтаж газового пожаротушения спб .
codestackr – Overall, professional vibe here; trustworthy, polished, and pleasantly minimal throughout.
купить взломостойкий сейф
сейфы для офиса купить
кухня на заказ спб от производителя недорого кухня на заказ спб от производителя недорого .
сейф встраиваемый купить
кухни на заказ в санкт-петербурге kuhni-spb-42.ru .
монтаж газового пожаротушения москва монтаж газового пожаротушения москва .
codepushr – Content reads clearly, helpful examples made concepts easy to grasp.
devpush – Navigation felt smooth, found everything quickly without any confusing steps.
сколько стоит заказать кухню zakazat-kuhnyu-4.ru .
gitpushr – Overall, professional vibe here; trustworthy, polished, and pleasantly minimal throughout.
mergekit – Found practical insights today; sharing this article with colleagues later.
оптимизация и продвижение сайтов москва оптимизация и продвижение сайтов москва .
сейф взломостойкий купить
купить кухню на заказ в спб kuhni-spb-43.ru .
сейфы москва
кухни под заказ кухни под заказ .
монтаж газовой системы пожаротушения под ключ монтаж газовой системы пожаротушения под ключ .
сейфы для офиса
заказать кухню в интернете заказать кухню в интернете .
Агентство недвижимости оказывает услуги по подбору загородных домов и коттеджей. Клиентам предлагаются варианты в разных районах Подмосковья. Это позволяет выбрать недвижимость для постоянного проживания или отдыха https://novostroyrf.ru/
школа онлайн обучение для детей shkola-onlajn-32.ru .
школа онлайн школа онлайн .
школа-пансион бесплатно школа-пансион бесплатно .
lbs lbs .
школы дистанционного обучения shkola-onlajn-33.ru .
online betting melbet online betting melbet .
купить гостиничный сейф
сколько стоит операция варикоцеле
встраиваемые сейфы цены
ломоносов школа ломоносов школа .
shipkit – Navigation felt smooth, found everything quickly without any confusing steps.
онлайн школа для школьников с аттестатом shkola-onlajn-31.ru .
как вывести на карту uzcard с 1win как вывести на карту uzcard с 1win
школа дистанционного обучения школа дистанционного обучения .
1win вывести баланс на мегапей http://1win68017.help
онлайн школы для детей онлайн школы для детей .
melbet перейти на сайт melbet перейти на сайт .
онлайн-школа для детей бесплатно shkola-onlajn-33.ru .
debugkit – Overall, professional vibe here; trustworthy, polished, and pleasantly minimal throughout.
commitkit – Content reads clearly, helpful examples made concepts easy to grasp.
1вин официальный сайт http://www.1win32786.help
купить огнестойкий сейф
testkit – Pages loaded fast, images appeared sharp, and formatting stayed consistent.
школа дистанционного обучения shkola-onlajn-32.ru .
домашняя школа интернет урок вход домашняя школа интернет урок вход .
lbs это lbs это .
тонзиллэктомия коблатором
дистанционное обучение 10-11 класс дистанционное обучение 10-11 класс .
мелбет скачать официальный сайт мелбет скачать официальный сайт .
контора мелбет контора мелбет .
сейф для оружия цена
flowbot – Navigation felt smooth, found everything quickly without any confusing steps.
promptkit – Mobile version looks perfect; no glitches, fast scrolling, crisp text.
скачать казино мелбет mobilemelbet.ru .
modelops – Mobile version looks perfect; no glitches, fast scrolling, crisp text.
logkit – Loved the layout today; clean, simple, and genuinely user-friendly overall.
databrain – Found practical insights today; sharing this article with colleagues later.
септопластика носовой перегородки цена в москве
онлайн школа 10-11 класс shkola-onlajn-31.ru .
рабочее зеркало melbet на сегодня прямо сейчас рабочее зеркало melbet на сегодня прямо сейчас .
melbet скачать бесплатно melbet скачать бесплатно .
seo клиники наркологии seo клиники наркологии .
операция по удалению атеромы
сейф оружейный купить
как использовать бонус мостбет как использовать бонус мостбет
How to propose beautifully https://propose.lol
онлайн школа для школьников с аттестатом онлайн школа для школьников с аттестатом .
дистанционное обучение 10-11 класс дистанционное обучение 10-11 класс .
московская школа онлайн обучение shkola-onlajn-33.ru .
где можно навесы заказать навес под машину
deploykit – Loved the layout today; clean, simple, and genuinely user-friendly overall.
1win depunere prin transfer 1win depunere prin transfer
мелбет казино скачать мелбет казино скачать .
онлайн школа ломоносов онлайн школа ломоносов .
мостбет линия спорт Кыргызстан mostbet49271.help
мелбет зеркало рабочее сегодня мелбет зеркало рабочее сегодня .
жировик удаление
сейф купить москва
онлайн школа 11 класс shkola-onlajn-31.ru .
удаление полипа эндометрия москва цена
операция септопластика
монтаж газового пожаротушения под ключ цена montazh-gazovogo-pozharotusheniya-3.ru .
онлайн школа с 1 по 11 класс онлайн школа с 1 по 11 класс .
класс с учениками класс с учениками .
mlforge – Found practical insights today; sharing this article with colleagues later.
онлайн обучение для школьников shkola-onlajn-32.ru .
melbet скачать мобильное приложение melbet скачать мобильное приложение .
класс с учениками shkola-onlajn-33.ru .
скачать мелбет полная версия скачать мелбет полная версия .
варикоцеле причины возникновения
мелбет зеркало на айфон мелбет зеркало на айфон .
фимоз 1 степень лечение
скачать букмекерскую контору мелбет скачать букмекерскую контору мелбет .
школа онлайн обучение для детей shkola-onlajn-33.ru .
smartpipe – Content reads clearly, helpful examples made concepts easy to grasp.
1win регистрация Киргизия 1win регистрация Киргизия
1win ошибка установки 1win ошибка установки
taskpipe – Appreciate the typography choices; comfortable spacing improved my reading experience.
opsbrain – Overall, professional vibe here; trustworthy, polished, and pleasantly minimal throughout.
patchkit – Content reads clearly, helpful examples made concepts easy to grasp.
melbet android melbet android .
melbet скачать ios melbet скачать ios .
операция по увеличению полового члена
мелбет мелбет .
мелбет сайт мелбет сайт .
melbetweb&melbet melbetweb&melbet .
скачать официальный сайт мелбет скачать официальный сайт мелбет .
melbet зеркало скачать на ios melbet зеркало скачать на ios .
guardstack – Appreciate the typography choices; comfortable spacing improved my reading experience.
securekit – Loved the layout today; clean, simple, and genuinely user-friendly overall.
казино мелбет скачать казино мелбет скачать .
authkit – Found practical insights today; sharing this article with colleagues later.
melbet – melbetlink.ru melbet – melbetlink.ru .
скачать melbet на ios скачать melbet на ios .
melbet apk file download melbet apk file download .
скачать мел бет букмекерская скачать мел бет букмекерская .
play slots play slots .
мелбет официальный сайт вход мелбет официальный сайт вход .
pipelinesy – Loved the layout today; clean, simple, and genuinely user-friendly overall.
увеличение полового члена цена
мелбет скачать казино мелбет скачать казино .
скачать официальное приложение melbet скачать официальное приложение melbet .
1win регистрация на сайте https://www.1win60925.help
мелбет казино официальный сайт скачать мелбет казино официальный сайт скачать .
скачать melbet на андроид скачать melbet на андроид .
мелбет официальный сайт скачать на андроид бесплатно мелбет официальный сайт скачать на андроид бесплатно .
casino live games casino live games .
мелбет зеркало мелбет зеркало .
мелбет зеркало скачать на айфон мелбет зеркало скачать на айфон .
Nubank caiu Nubank caiu .
водные экскурсии в санкт петербурге arenda-yakhty-spb-2.ru .
скачать мелбет бесплатно скачать мелбет бесплатно .
скачать бк мелбет скачать бк мелбет .
водные прогулки в санкт петербурге arenda-yakhty-spb.ru .
мелбет ру мелбет ру .
удаление полипа на шейке матки сколько
мелбет скачать на андроид бесплатно с официального мелбет скачать на андроид бесплатно с официального .
melbet official melbet official .
1win вейджер бонуса http://1win15478.help
мелбет казино официальный сайт мелбет казино официальный сайт .
melbet кэшбэк melbet кэшбэк
cum sa intru in cont melbet cum sa intru in cont melbet
прогулка на катере санкт петербург прогулка на катере санкт петербург .
zerotrusty – Overall, professional vibe here; trustworthy, polished, and pleasantly minimal throughout.
прогулка по рекам и каналам прогулка по рекам и каналам .
melbet зеркало скачать melbet зеркало скачать .
скачать мелбет скачать мелбет .
мелбет казино официальный сайт мелбет казино официальный сайт .
скачать приложение мелбет на андроид бесплатно скачать приложение мелбет на андроид бесплатно .
речные прогулки по неве arenda-yakhty-spb.ru .
мелбет официальный сайт скачать мелбет официальный сайт скачать .
Nubank down Nubank down .
скачать мелбет на компьютер скачать мелбет на компьютер .
keyvaulty – Mobile version looks perfect; no glitches, fast scrolling, crisp text.
threatlens – Navigation felt smooth, found everything quickly without any confusing steps.
shieldops – Loved the layout today; clean, simple, and genuinely user-friendly overall.
речные прогулки по неве arenda-yakhty-spb-1.ru .
secstackr – Bookmarked this immediately, planning to revisit for updates and inspiration.
скачать мелбет на android скачать мелбет на android .
auditkit – Color palette felt calming, nothing distracting, just focused, thoughtful design.
мелбет бонус за регистрацию мелбет бонус за регистрацию .
снять катер спб arenda-yakhty-spb-2.ru .
мелбет скачать apk мелбет скачать apk .
melbet bet melbetweb.ru .
прокат яхт arenda-yakhty-spb.ru .
мелбет скачать на андроид бесплатно мелбет скачать на андроид бесплатно .
melbet скачать казино melbet скачать казино .
AWS caiu caiu.site .
речные прогулки спб arenda-yakhty-spb-1.ru .
melbet зеркало melbet зеркало .
melbet official bookmaker melbet official bookmaker .
прогулки по неве прогулки по неве .
1win Balance.kg https://1win20819.help
речные прогулки по неве arenda-yakhty-spb.ru .
мелбет казино скачать на андроид мелбет казино скачать на андроид .
аренда яхты спб аренда яхты спб .
мелбет ставки на спорт мелбет ставки на спорт .
мелбет мобильная версия мелбет мобильная версия .
мостбет актуальное зеркало https://mostbet90753.help
прогулка по рекам и каналам прогулка по рекам и каналам .
pinup lucky jet strategiya http://www.pinup14278.help
водные прогулки спб arenda-yakhty-spb.ru .
мелбет фрибет без депозита мелбет фрибет без депозита .
скачать мелбет на айфон бесплатно скачать мелбет на айфон бесплатно .
устанавливаем навесы заказать навес для автомобиля
речные прогулки спб речные прогулки спб .
нарколог на дом ночью ростов-на-дону narkolog-na-dom-v-rostove.ru .
smartbyte – Appreciate the typography choices; comfortable spacing improved my reading experience.
прогулка по рекам и каналам прогулка по рекам и каналам .
нарколог на дом в ростове на дону нарколог на дом в ростове на дону .
techsphere – Content reads clearly, helpful examples made concepts easy to grasp.
нарколог на дом в ростове-на-дону нарколог на дом в ростове-на-дону .
cyberstack – Color palette felt calming, nothing distracting, just focused, thoughtful design.
nanotechhub – Content reads clearly, helpful examples made concepts easy to grasp.
keyvaulty – Pages loaded fast, images appeared sharp, and formatting stayed consistent.
clicktechy – Found practical insights today; sharing this article with colleagues later.
аренда катера спб с капитаном аренда катера спб с капитаном .
bytetap – Appreciate the typography choices; comfortable spacing improved my reading experience.
наркологическая служба на дом ростов-на-дону narkolog-na-dom-v-rostove-1.ru .
речные прогулки по неве arenda-yakhty-spb-1.ru .
сколько стоит нарколог на дом в ростове сколько стоит нарколог на дом в ростове .
quickbyte – Content reads clearly, helpful examples made concepts easy to grasp.
нарколог выезд на дом ростов narkolog-na-dom-v-rostove-3.ru .
techvertex – Found practical insights today; sharing this article with colleagues later.
вывод из запоя в ростове цена vyvod-iz-zapoya-v-rostove-1.ru .
mostbet официальный сайт Киргизия mostbet45087.help
вывод из запоя в ростове на дону вывод из запоя в ростове на дону .
вызвать нарколога на дом ростов-на-дону вызвать нарколога на дом ростов-на-дону .
mostbet autentificare rapida http://mostbet63218.help
pixelengine – Bookmarked this immediately, planning to revisit for updates and inspiration.
прогулка на катере санкт петербург прогулка на катере санкт петербург .
нарколог на дом недорого ростов нарколог на дом недорого ростов .
нарколог на дом срочно ростов-на-дону нарколог на дом срочно ростов-на-дону .
вывод из запоя в ростове цена vyvod-iz-zapoya-v-rostove-1.ru .
нарколог вывод из запоя в ростове vyvod-iz-zapoya-v-rostove-2.ru .
вывод из запоя на дому в ростове-на-дону вывод из запоя на дому в ростове-на-дону .
срочный вызов нарколога на дом ростов срочный вызов нарколога на дом ростов .
врач нарколог на дом в ростове врач нарколог на дом в ростове .
Water leak detection Philadelphia
мостбет экспресс ставка https://www.mostbet20748.help
вывод из запоя в стационаре в ростове на дону вывод из запоя в стационаре в ростове на дону .
водные прогулки в санкт петербурге водные прогулки в санкт петербурге .
психиатр нарколог на дом в ростове психиатр нарколог на дом в ростове .
1win условия вывода https://1win17043.help
mostbet virtual ot poygasi http://mostbet28461.help/
нарколог на дом цена в ростове нарколог на дом цена в ростове .
купить кольцо из белого золота помолвочные кольца москва
Curious about the weather weather in Podgorica Montenegro today. Detailed 7- and 10-day forecasts, including temperature, wind, precipitation, humidity, and pressure. Up-to-date information on the climate and weather conditions in Podgorica for travel and leisure.
futurestack – Pages loaded fast, images appeared sharp, and formatting stayed consistent.
logicforge – Appreciate the typography choices; comfortable spacing improved my reading experience.
Слот Mental 3 часто вызывает вопросы по режимам, частоте бонусок и “поведению” на разных ставках – поэтому мы собрали отдельную группу, где всё это обсуждают живо и по делу: результаты, скрины, советы и просто общение по игре. Вступить можно здесь: https://t.me/s/mentalslot_3
bytelab – Overall, professional vibe here; trustworthy, polished, and pleasantly minimal throughout.
zyrotech – Bookmarked this immediately, planning to revisit for updates and inspiration.
omegabyte – Navigation felt smooth, found everything quickly without any confusing steps.
круглосуточный нарколог на дом в ростове круглосуточный нарколог на дом в ростове .
стоимость монтажа газового пожаротушения montazh-gazovogo-pozharotusheniya-2.ru .
монтаж газового пожаротушения в офис montazh-gazovogo-pozharotusheniya.ru .
Почти никто не любит верификацию, но иногда без неё никак – особенно если планируете выводить регулярно и без “подвисаний”. В таких случаях лучше сразу смотреть казино с простой верификацией, где процесс проходит быстро и без бесконечной переписки с поддержкой. В нашем Telegram мы собираем площадки, где обычно хватает стандартного набора документов, всё делается по понятной схеме и без неожиданных требований “принесите ещё одно фото”. Плюс отмечаем важные нюансы: сроки проверки, частые причины отказов и что лучше подготовить заранее, чтобы не терять время.
techdock – Color palette felt calming, nothing distracting, just focused, thoughtful design.
bitzone – Content reads clearly, helpful examples made concepts easy to grasp.
мелбет личный кабинет мелбет личный кабинет .
стоимость монтажа газового пожаротушения montazh-gazovogo-pozharotusheniya-1.ru .
вывод из запоя дома в ростове vyvod-iz-zapoya-v-rostove-4.ru .
codehive – Overall, professional vibe here; trustworthy, polished, and pleasantly minimal throughout.
вывод из запоя клиника в ростове вывод из запоя клиника в ростове .
монтаж газовой системы пожаротушения под ключ montazh-gazovogo-pozharotusheniya.ru .
монтаж газового пожаротушения под ключ монтаж газового пожаротушения под ключ .
мелбет букмекерская контора мелбет букмекерская контора .
tronbyte – Content reads clearly, helpful examples made concepts easy to grasp.
futurebyte – Pages loaded fast, images appeared sharp, and formatting stayed consistent.
водные экскурсии в санкт петербурге arenda-yakhty-spb-1.ru .
круглосуточный вывод из запоя в ростове круглосуточный вывод из запоя в ростове .
установка модулей газового пожаротушения установка модулей газового пожаротушения .
клиника в ростове вывод из запоя клиника в ростове вывод из запоя .
платный нарколог на дом в ростове платный нарколог на дом в ростове .
мелбет казино слоты melbetofficialbookmaker.ru .
mostbet акции mostbet акции
mostbet официальный сайт рабочий mostbet официальный сайт рабочий
1win пополнение элсом http://1win54038.help/
снять яхту в спб снять яхту в спб .
срочный вызов нарколога на дом ростов срочный вызов нарколога на дом ростов .
вывод из запоя в клинике в ростове вывод из запоя в клинике в ростове .
mostbet mobil app yüklə mostbet mobil app yüklə
накрутка подписчиков в Телеграм
вывод из запоя в стационаре в ростове-на-дону vyvod-iz-zapoya-v-rostove-1.ru .
круглосуточный нарколог на дом в ростове круглосуточный нарколог на дом в ростове .
газовое пожаротушение монтаж с гарантией газовое пожаротушение монтаж с гарантией .
мелбет скачать на айфон мелбет скачать на айфон .
Sprawdz poradnik jaka kamere do drona fpv wybrac, jesli szukasz najlepszych wskazowek przy wyborze kamery FPV na start.
Przy zakupie warto zwrocic uwage na rozdzielczosc oraz matryce urzadzenia.
вывод из запоя в стационаре в ростове на дону вывод из запоя в стационаре в ростове на дону .
вывод из запоя с выездом в ростове vyvod-iz-zapoya-v-rostove-1.ru .
монтаж системы газового пожаротушения спб montazh-gazovogo-pozharotusheniya-3.ru .
Reputation management is the strategic practice of influencing public perceptions of a brand or individual.
It involves continuously tracking what is being said about you on the internet.
The primary aim is to promote positive information and address any negative feedback or reviews.
This often includes engaging with online reviews on various platforms.
https://www.amino.dk/members/RepuHouse/default.aspx
A vital component is managing search engine listings for associated search terms.
Effective reputation management helps build trust and protect a strong brand image.
Ultimately, it is an essential practice for any modern organization or professional.
Профессиональный быстрый анонимный вывод из запоя на дому детоксикация организма, помощь при алкогольной интоксикации и восстановление самочувствия пациента. Специалист приезжает на дом и оказывает профессиональную помощь.
mostbet скачать если сайт заблокирован http://mostbet94063.help
codenova – Loved the layout today; clean, simple, and genuinely user-friendly overall.
mostbet free bet qachon tushadi http://mostbet84629.help
bytenova – Found practical insights today; sharing this article with colleagues later.
zybertech – Appreciate the typography choices; comfortable spacing improved my reading experience.
vortexbyte – Content reads clearly, helpful examples made concepts easy to grasp.
курсовая работа купить курсовая работа купить .
zenixtech – Mobile version looks perfect; no glitches, fast scrolling, crisp text.
technexus – Overall, professional vibe here; trustworthy, polished, and pleasantly minimal throughout.
veloxtech – Appreciate the typography choices; comfortable spacing improved my reading experience.
byterise – Overall, professional vibe here; trustworthy, polished, and pleasantly minimal throughout.
курсовой проект купить цена курсовой проект купить цена .
куплю курсовую работу куплю курсовую работу .
ремонт квартир недорого remont-v-tyle.ru .
курсовой проект цена курсовой проект цена .
курсовые заказ kupit-kursovuyu-86.ru .
курсовая работа на заказ цена курсовая работа на заказ цена .
курсовые работы заказать курсовые работы заказать .
промокод для мелбет промокод для мелбет .
купить курсовую москва купить курсовую москва .
1win Apelsin depozit https://1win5754.help/
mostbet lucky jet online mostbet lucky jet online
Качественное SEO https://outreachseo.ru продвижение сайта для бизнеса. Наши специалисты предлагают эффективные решения для роста позиций в поисковых системах. Подробнее об услугах и стратегиях можно узнать на сайте
mostbet app biztonságos https://mostbet2023.help
тула ремонт квартиры цена remont-v-tyle.ru .
курсовая работа купить москва курсовая работа купить москва .
написание учебных работ kupit-kursovuyu-84.ru .
курсовая работа недорого kupit-kursovuyu-86.ru .
сколько стоит курсовая работа по юриспруденции сколько стоит курсовая работа по юриспруденции .
курсовой проект цена kupit-kursovuyu-87.ru .
стоимость ремонта квартиры remont-v-tyle.ru .
написание курсовой работы на заказ цена kupit-kursovuyu-88.ru .
студенческие работы на заказ kupit-kursovuyu-86.ru .
курсовая заказать курсовая заказать .
купить курсовую купить курсовую .
написать курсовую на заказ написать курсовую на заказ .
melbet казино слоты melbet казино слоты
ремонт двухкомнатной квартиры remont-v-tyle.ru .
заказать курсовую работу качественно заказать курсовую работу качественно .
курсовая заказ купить курсовая заказ купить .
Online medicine delivery services are especially helpful for families managing regular treatments. Monthly medicines can be ordered in advance, ensuring there is no gap in important medications: https://www.fta.edu.au/vocational-education-vet-training/
mostbet кэшбэк казино http://mostbet60172.help
помощь студентам курсовые помощь студентам курсовые .
quantumforge – Found practical insights today; sharing this article with colleagues later.
заказать курсовую срочно заказать курсовую срочно .
mostbet официальный сайт Казахстан http://www.mostbet82043.help
techcatalyst – Navigation felt smooth, found everything quickly without any confusing steps.
devbyte – Found practical insights today; sharing this article with colleagues later.
dataforge – Color palette felt calming, nothing distracting, just focused, thoughtful design.
logicbyte – Pages loaded fast, images appeared sharp, and formatting stayed consistent.
seo агентство seo агентство .
сайт для заказа курсовых работ сайт для заказа курсовых работ .
bitcore – Content reads clearly, helpful examples made concepts easy to grasp.
1win contact chat http://1win62509.help/
seo partner program prodvizhenie-sajtov-v-moskve17.ru .
купить курсовую сайт купить курсовую сайт .
поисковое seo в москве поисковое seo в москве .
помощь в написании курсовой помощь в написании курсовой .
заказать продвижение сайта в москве заказать продвижение сайта в москве .
курсовая заказать недорого kupit-kursovuyu-86.ru .
онлайн сервис помощи студентам онлайн сервис помощи студентам .
заказать курсовую работу качественно заказать курсовую работу качественно .
заказ курсовых работ заказ курсовых работ .
1win apk android descargar http://www.1win5772.help
оптимизация сайта франция prodvizhenie-sajtov-v-moskve17.ru .
поисковое продвижение москва профессиональное продвижение сайтов prodvizhenie-sajtov-v-moskve16.ru .
онлайн сервис помощи студентам kupit-kursovuyu-87.ru .
продвижение сайтов в москве продвижение сайтов в москве .
написание курсовой работы на заказ цена kupit-kursovuyu-89.ru .
интернет агентство продвижение сайтов сео интернет агентство продвижение сайтов сео .
заказать курсовую работу качественно заказать курсовую работу качественно .
расценки на ремонт квартир remont-v-tyle.ru .
pin-up hisob tasdiqlash https://pinup76809.help/
сайт для заказа курсовых работ kupit-kursovuyu-86.ru .
куплю курсовую работу куплю курсовую работу .
купить курсовую сайт купить курсовую сайт .
заказать курсовую работу качественно kupit-kursovuyu-83.ru .
продвинуть сайт в москве продвинуть сайт в москве .
студенческие работы на заказ kupit-kursovuyu-87.ru .
интернет продвижение москва интернет продвижение москва .
seovault – Content reads clearly, helpful examples made concepts easy to grasp.
Если вы планируете купить памятник в Могилеве, обратите внимание на изделия из натурального гранита. Этот материал отличается долговечностью, стойкостью к погодным условиям и благородным внешним видом. В каталоге представлены как классические вертикальные стелы, так и эксклюзивные мемориальные комплексы. Профессиональное изготовление памятников в Могилеве включает разработку индивидуального эскиза, качественную гравировку и установку на кладбище https://pamyatniki.top/
Любишь азарт? https://pfrrt.ru предлагает разнообразные игровые автоматы, настольные игры и интересные бонусные программы. Платформа создана для комфортной игры и предлагает широкий выбор развлечений.
seoshift – Color palette felt calming, nothing distracting, just focused, thoughtful design.
seonexus – Navigation felt smooth, found everything quickly without any confusing steps.
курсовая заказать недорого курсовая заказать недорого .
куплю курсовую работу куплю курсовую работу .
сделать аудит сайта цена prodvizhenie-sajtov-v-moskve16.ru .
seo network prodvizhenie-sajtov-v-moskve17.ru .
продвижение сайтов в москве продвижение сайтов в москве .
глубокий комлексный аудит сайта глубокий комлексный аудит сайта .
написание курсовой работы на заказ цена написание курсовой работы на заказ цена .
компании занимающиеся продвижением сайтов компании занимающиеся продвижением сайтов .
раскрутка сайта москва раскрутка сайта москва .
интернет продвижение москва интернет продвижение москва .
интернет раскрутка prodvizhenie-sajtov-v-moskve17.ru .
курсовые купить kupit-kursovuyu-81.ru .
clickrly – Appreciate the typography choices; comfortable spacing improved my reading experience.
seoradar – Bookmarked this immediately, planning to revisit for updates and inspiration.
reachrocket – Content reads clearly, helpful examples made concepts easy to grasp.
заказать практическую работу недорого цены заказать практическую работу недорого цены .
scalewave – Content reads clearly, helpful examples made concepts easy to grasp.
поисковое продвижение москва профессиональное продвижение сайтов prodvizhenie-sajtov-v-moskve16.ru .
1win chat en vivo méxico https://1win5772.help/
суши недорого суши недорого .
how to withdraw from 1win https://1win5742.help/
mostbet apk download mostbet apk download
convertcraft – Color palette felt calming, nothing distracting, just focused, thoughtful design.
доставка роллов доставка роллов .
boostsignals – Mobile version looks perfect; no glitches, fast scrolling, crisp text.
цифровой маркетинг статьи seo-blog20.ru .
маркетинговые стратегии статьи seo-blog21.ru .
суши бесплатная доставка суши бесплатная доставка .
pin-up 18+ https://pinup23185.help/
Накрутка поведенческих факторов может применяться как часть стратегии продвижения. Она помогает увеличить показатели активности и удержания пользователей – продвижение сайта в топ яндекса поведенческими факторами
суши роллы спб доставка суши роллы спб доставка .
продвижение сайта по трафику пример договора prodvizhenie-sajtov-po-trafiku10.ru .
доставка суши доставка суши .
как быстрее кончить
кораблик по неве vodnyye-progulki-v-spb.ru .
суши москва суши москва .
оптимизация сайта блог seo-blog20.ru .
блог агентства интернет-маркетинга блог агентства интернет-маркетинга .
купить суши купить суши .
Witamy w polskim legalnym internetowym kasynie Slottica – miejscu stworzonym dla hazardzistów online w Polsce! Casino Slotica w polskiej wersji językowej otwiera przed Tobą świat pełen emocjonujących gier za darmo i atrakcyjnych nagród bez rejestracji. Strona przyciąga nowych użytkowników między innymi premią powitalną 25 zł bez konieczności wpłaty depozytu. W badaniu przeprowadzonym wśród ponad 8500 graczy wielu z nich wskazało Slottica jako jedną z najciekawszych stron z automatami online dostępnych w Polsce. W katalogu gier znajdują się znane produkcje, w tym Chicken Road 2, Fire Joker, Funky Time, Dog House 1000 czy Energy Joker: Hold and Win. Od momentu startu projektu w 2019 roku platformie zaufało już ponad 350 000 użytkowników. Serwis działa na podstawie licencji wydanej przez regulatora z Curaçao, co zapewnia zgodność z europejskimi standardami branży iGaming. Ambicją marki jest oferowanie jakości usług, która może skutecznie konkurować z popularnymi serwisami pokroju TotalCasino.
Профессиональная веб-студия разрабатывает сайты под ключ и занимается их эффективным SEO-продвижением. Помогает бизнесу заявлять о себе в сети и увеличивать продажи. Подробнее об услугах на сайте – https://inuniver24.ru/
Консультация семейного юриста поможет быстро разобраться в сложных жизненных ситуациях: развод, раздел имущества, алименты, споры о детях и брачные договоры. Перейдя по запросу бесплатный адвокат по семейным делам – специалист объяснит ваши права, оценит перспективы дела и предложит оптимальный план действий. Получите профессиональную юридическую помощь и ответы на все вопросы по семейному праву.
seo информационных порталов prodvizhenie-sajtov-po-trafiku10.ru .