
import torch
import torch.nn.useful as F
class DPOTrainer:
def __init__(self, mannequin, ref_model, beta=0.1, lr=1e-5):
self.mannequin = mannequin
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.mannequin.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: coverage logprobs, form (B,)
ref_logps: reference mannequin logprobs, form (B,)
yw_idxs: most popular completion indices in [0, B-1], form (T,)
yl_idxs: dispreferred completion indices in [0, B-1], form (T,)
beta: temperature controlling energy of KL penalty
Every pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single desire pair.
"""
# Extract log possibilities for the popular and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.imply(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log possibilities for the mannequin and the reference mannequin
pi_logps = self.mannequin(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.merchandise()
# Utilization
mannequin = YourLanguageModel() # Initialize your mannequin
ref_model = YourLanguageModel() # Load pre-trained reference mannequin
coach = DPOTrainer(mannequin, ref_model)
for batch in dataloader:
loss = coach.train_step(batch)
print(f"Loss: {loss}")
Challenges and Future Instructions
Whereas DPO affords vital benefits over conventional RLHF approaches, there are nonetheless challenges and areas for additional analysis:
a) Scalability to Bigger Fashions:
As language fashions proceed to develop in dimension, effectively making use of DPO to fashions with a whole lot of billions of parameters stays an open problem. Researchers are exploring strategies like:
- Environment friendly fine-tuning strategies (e.g., LoRA, prefix tuning)
- Distributed coaching optimizations
- Gradient checkpointing and mixed-precision coaching
Instance of utilizing LoRA with DPO:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, mannequin, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.mannequin = get_peft_model(mannequin, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.mannequin.parameters(), lr=lr)
# Utilization
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) Multi-Process and Few-Shot Adaptation:
Growing DPO strategies that may effectively adapt to new duties or domains with restricted desire knowledge is an lively space of analysis. Approaches being explored embody:
- Meta-learning frameworks for speedy adaptation
- Immediate-based fine-tuning for DPO
- Switch studying from basic desire fashions to particular domains
c) Dealing with Ambiguous or Conflicting Preferences:
Actual-world desire knowledge typically comprises ambiguities or conflicts. Enhancing DPO’s robustness to such knowledge is essential. Potential options embody:
- Probabilistic desire modeling
- Energetic studying to resolve ambiguities
- Multi-agent desire aggregation
Instance of probabilistic desire modeling:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.imply()
# Utilization
coach = ProbabilisticDPOTrainer(mannequin, ref_model)
loss = coach.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in desire
d) Combining DPO with Different Alignment Strategies:
Integrating DPO with different alignment approaches may result in extra sturdy and succesful techniques:
- Constitutional AI rules for specific constraint satisfaction
- Debate and recursive reward modeling for complicated desire elicitation
- Inverse reinforcement studying for inferring underlying reward capabilities
Instance of mixing DPO with constitutional AI:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, mannequin, ref_model, beta=0.1, lr=1e-5, constraints=None):
tremendous().__init__(mannequin, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = tremendous().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.mannequin, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Utilization
def safety_constraint(mannequin, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement security checking logic
unsafe_score = compute_unsafe_score(mannequin, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe rating > 0.5
constraints = [safety_constraint]
coach = ConstitutionalDPOTrainer(mannequin, ref_model, constraints=constraints)
Sensible Issues and Greatest Practices
When implementing DPO for real-world purposes, take into account the next suggestions:
a) Knowledge High quality: The standard of your desire knowledge is essential. Be sure that your dataset:
- Covers a various vary of inputs and desired behaviors
- Has constant and dependable desire annotations
- Balances several types of preferences (e.g., factuality, security, fashion)
b) Hyperparameter Tuning: Whereas DPO has fewer hyperparameters than RLHF, tuning remains to be necessary:
- β (beta): Controls the trade-off between desire satisfaction and divergence from the reference mannequin. Begin with values round 0.1-0.5.
- Studying fee: Use a decrease studying fee than commonplace fine-tuning, sometimes within the vary of 1e-6 to 1e-5.
- Batch dimension: Bigger batch sizes (32-128) typically work effectively for desire studying.
c) Iterative Refinement: DPO will be utilized iteratively:
- Practice an preliminary mannequin utilizing DPO
- Generate new responses utilizing the educated mannequin
- Accumulate new desire knowledge on these responses
- Retrain utilizing the expanded dataset
This charts present a visible illustration of how totally different coaching strategies have an effect on LLM efficiency in duties resembling IMDb sentiment era and TL;DR summarization. The metrics reveal that fashions educated with DPO exhibit the next reward fee in sentiment era duties, suggesting that this method enhances the mannequin’s capacity to supply fascinating outputs. Equally, the win fee evaluation for summarization signifies that fine-tuning strategies considerably affect the mannequin’s capacity to generate concise, correct summaries, with variations relying on sampling temperatures and methodologies.

Direct Choice Optimization Efficiency
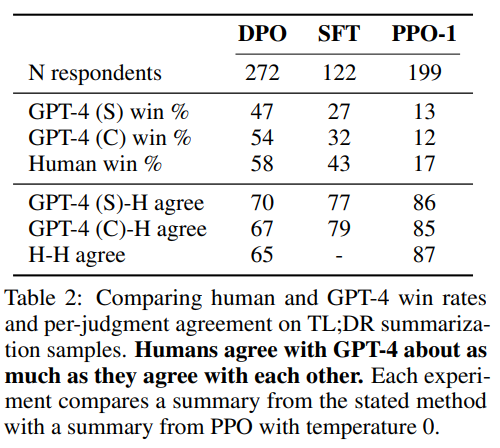
This picture delves into the efficiency of LLMs like GPT-4 compared to human judgments throughout numerous coaching strategies, together with Direct Choice Optimization (DPO), Supervised Wonderful-Tuning (SFT), and Proximal Coverage Optimization (PPO). The desk reveals that GPT-4’s outputs are more and more aligned with human preferences, particularly in summarization duties. The extent of settlement between GPT-4 and human reviewers demonstrates the mannequin’s capacity to generate content material that resonates with human evaluators, nearly as intently as human-generated content material does.
Case Research and Purposes
As an example the effectiveness of DPO, let us take a look at some real-world purposes and a few of its variants:
- Iterative DPO: Developed by Snorkel (2023), this variant combines rejection sampling with DPO, enabling a extra refined choice course of for coaching knowledge. By iterating over a number of rounds of desire sampling, the mannequin is healthier in a position to generalize and keep away from overfitting to noisy or biased preferences.
- IPO (Iterative Preference Optimization): Launched by Azar et al. (2023), IPO provides a regularization time period to stop overfitting, which is a typical situation in preference-based optimization. This extension permits fashions to take care of a steadiness between adhering to preferences and preserving generalization capabilities.
- KTO (Knowledge Transfer Optimization): A newer variant from Ethayarajh et al. (2023), KTO dispenses with binary preferences altogether. As a substitute, it focuses on transferring information from a reference mannequin to the coverage mannequin, optimizing for a smoother and extra constant alignment with human values.
- Multi-Modal DPO for Cross-Domain Learning by Xu et al. (2024): An method the place DPO is utilized throughout totally different modalities—textual content, picture, and audio—demonstrating its versatility in aligning fashions with human preferences throughout numerous knowledge sorts. This analysis highlights the potential of DPO in creating extra complete AI techniques able to dealing with complicated, multi-modal duties.