
Meta has just lately launched Llama 3, the following technology of its state-of-the-art open supply massive language mannequin (LLM). Constructing on the foundations set by its predecessor, Llama 3 goals to reinforce the capabilities that positioned Llama 2 as a big open-source competitor to ChatGPT, as outlined within the complete evaluate within the article Llama 2: A Deep Dive into the Open-Supply Challenger to ChatGPT.
On this article we are going to focus on the core ideas behind Llama 3, discover its progressive structure and coaching course of, and supply sensible steering on easy methods to entry, use, and deploy this groundbreaking mannequin responsibly. Whether or not you’re a researcher, developer, or AI fanatic, this put up will equip you with the information and sources wanted to harness the facility of Llama 3 in your initiatives and purposes.
The Evolution of Llama: From Llama 2 to Llama 3
Meta’s CEO, Mark Zuckerberg, announced the debut of Llama 3, the newest AI mannequin developed by Meta AI. This state-of-the-art mannequin, now open-sourced, is ready to reinforce Meta’s numerous merchandise, together with Messenger and Instagram. Zuckerberg highlighted that Llama 3 positions Meta AI as probably the most superior freely available AI assistant.
Earlier than we speak in regards to the specifics of Llama 3, let’s briefly revisit its predecessor, Llama 2. Launched in 2022, Llama 2 was a big milestone within the open-source LLM panorama, providing a robust and environment friendly mannequin that might be run on client {hardware}.
Nonetheless, whereas Llama 2 was a notable achievement, it had its limitations. Customers reported points with false refusals (the mannequin refusing to reply benign prompts), restricted helpfulness, and room for enchancment in areas like reasoning and code technology.
Enter Llama 3: Meta’s response to those challenges and the group’s suggestions. With Llama 3, Meta has got down to construct the most effective open-source fashions on par with the highest proprietary fashions out there at present, whereas additionally prioritizing accountable growth and deployment practices.
Llama 3: Structure and Coaching
One of many key improvements in Llama 3 is its tokenizer, which contains a considerably expanded vocabulary of 128,256 tokens (up from 32,000 in Llama 2). This bigger vocabulary permits for extra environment friendly encoding of textual content, each for enter and output, doubtlessly resulting in stronger multilingualism and total efficiency enhancements.
Llama 3 additionally incorporates Grouped-Question Consideration (GQA), an environment friendly illustration method that enhances scalability and helps the mannequin deal with longer contexts extra successfully. The 8B model of Llama 3 makes use of GQA, whereas each the 8B and 70B fashions can course of sequences as much as 8,192 tokens.
Coaching Knowledge and Scaling
The coaching information used for Llama 3 is an important consider its improved efficiency. Meta curated a large dataset of over 15 trillion tokens from publicly out there on-line sources, seven instances bigger than the dataset used for Llama 2. This dataset additionally contains a good portion (over 5%) of high-quality non-English information, protecting greater than 30 languages, in preparation for future multilingual purposes.
To make sure information high quality, Meta employed superior filtering strategies, together with heuristic filters, NSFW filters, semantic deduplication, and textual content classifiers educated on Llama 2 to foretell information high quality. The group additionally carried out in depth experiments to find out the optimum combine of knowledge sources for pretraining, making certain that Llama 3 performs effectively throughout a variety of use circumstances, together with trivia, STEM, coding, and historic information.
Scaling up pretraining was one other vital facet of Llama 3’s growth. Meta developed scaling legal guidelines that enabled them to foretell the efficiency of its largest fashions on key duties, equivalent to code technology, earlier than truly coaching them. This knowledgeable the choices on information combine and compute allocation, in the end resulting in extra environment friendly and efficient coaching.
Llama 3’s largest fashions had been educated on two custom-built 24,000 GPU clusters, leveraging a mixture of knowledge parallelization, mannequin parallelization, and pipeline parallelization strategies. Meta’s superior coaching stack automated error detection, dealing with, and upkeep, maximizing GPU uptime and growing coaching effectivity by roughly thrice in comparison with Llama 2.
Instruction Tremendous-tuning and Efficiency
To unlock Llama 3’s full potential for chat and dialogue purposes, Meta innovated its method to instruction fine-tuning. Its methodology combines supervised fine-tuning (SFT), rejection sampling, proximal coverage optimization (PPO), and direct desire optimization (DPO).
The standard of the prompts utilized in SFT and the desire rankings utilized in PPO and DPO performed an important position within the efficiency of the aligned fashions. Meta’s group fastidiously curated this information and carried out a number of rounds of high quality assurance on annotations offered by human annotators.
Coaching on desire rankings through PPO and DPO additionally considerably improved Llama 3’s efficiency on reasoning and coding duties. Meta discovered that even when a mannequin struggles to reply a reasoning query straight, it might nonetheless produce the right reasoning hint. Coaching on desire rankings enabled the mannequin to discover ways to choose the right reply from these traces.
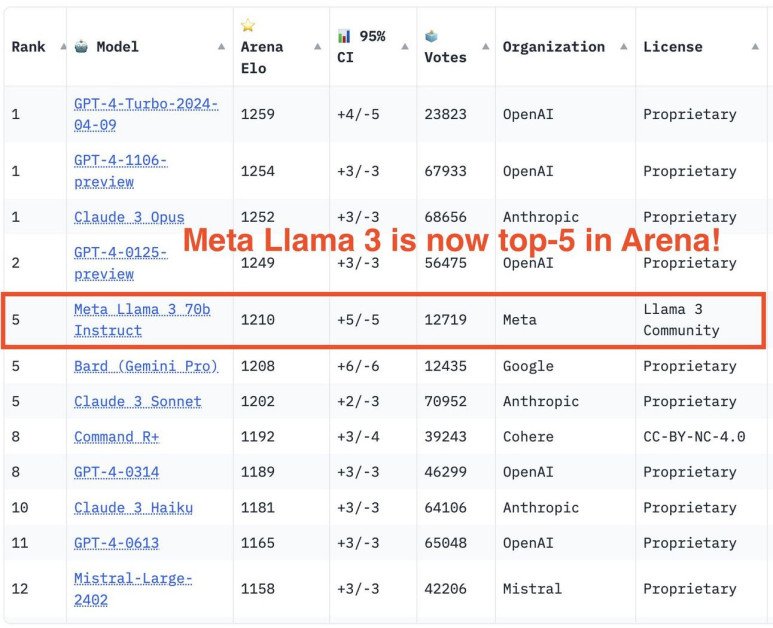
The outcomes converse for themselves: Llama 3 outperforms many out there open-source chat fashions on frequent business benchmarks, establishing new state-of-the-art efficiency for LLMs on the 8B and 70B parameter scales.
Accountable Growth and Security Concerns
Whereas pursuing cutting-edge efficiency, Meta additionally prioritized accountable growth and deployment practices for Llama 3. The corporate adopted a system-level method, envisioning Llama 3 fashions as a part of a broader ecosystem that places builders within the driver’s seat, permitting them to design and customise the fashions for his or her particular use circumstances and security necessities.
Meta carried out in depth red-teaming workout routines, carried out adversarial evaluations, and applied security mitigation strategies to decrease residual dangers in its instruction-tuned fashions. Nonetheless, the corporate acknowledges that residual dangers will seemingly stay and recommends that builders assess these dangers within the context of their particular use circumstances.
To help accountable deployment, Meta has up to date its Accountable Use Information, offering a complete useful resource for builders to implement mannequin and system-level security finest practices for his or her purposes. The information covers matters equivalent to content material moderation, threat evaluation, and using security instruments like Llama Guard 2 and Code Protect.
Llama Guard 2, constructed on the MLCommons taxonomy, is designed to categorise LLM inputs (prompts) and responses, detecting content material that could be thought of unsafe or dangerous. CyberSecEval 2 expands on its predecessor by including measures to forestall abuse of the mannequin’s code interpreter, offensive cybersecurity capabilities, and susceptibility to immediate injection assaults.
Code Protect, a brand new introduction with Llama 3, provides inference-time filtering of insecure code produced by LLMs, mitigating dangers related to insecure code options, code interpreter abuse, and safe command execution.
Accessing and Utilizing Llama 3
Meta has made Llama 3 fashions out there via numerous channels, together with direct obtain from the Meta Llama web site, Hugging Face repositories, and widespread cloud platforms like AWS, Google Cloud, and Microsoft Azure.
To obtain the fashions straight, customers should first settle for Meta’s Llama 3 Group License and request entry via the Meta Llama web site. As soon as accredited, customers will obtain a signed URL to obtain the mannequin weights and tokenizer utilizing the offered obtain script.
Alternatively, customers can entry the fashions via the Hugging Face repositories, the place they’ll obtain the unique native weights or use the fashions with the Transformers library for seamless integration into their machine studying workflows.
This is an instance of easy methods to use the Llama 3 8B Instruct mannequin with Transformers:
# Set up required libraries !pip set up datasets huggingface_hub sentence_transformers lancedb


