

Experiment monitoring, or experiment logging, is a key facet of MLOps. Monitoring experiments is essential for iterative mannequin growth, the a part of the ML challenge lifecycle the place you strive many issues to get your mannequin efficiency to the extent you want.
On this article, we’ll reply the next questions:
- What’s experiment monitoring in ML?
- How does it work? (tutorials and examples)
- Methods to implement experiment logging?
- What are greatest practices?
About us: We’re the creators of the enterprise no-code Pc Imaginative and prescient Platform, Viso Suite. Viso Suite permits for the management of the whole ML pipeline, together with knowledge assortment, coaching, and mannequin analysis. Find out about Viso Suite and e book a demo.
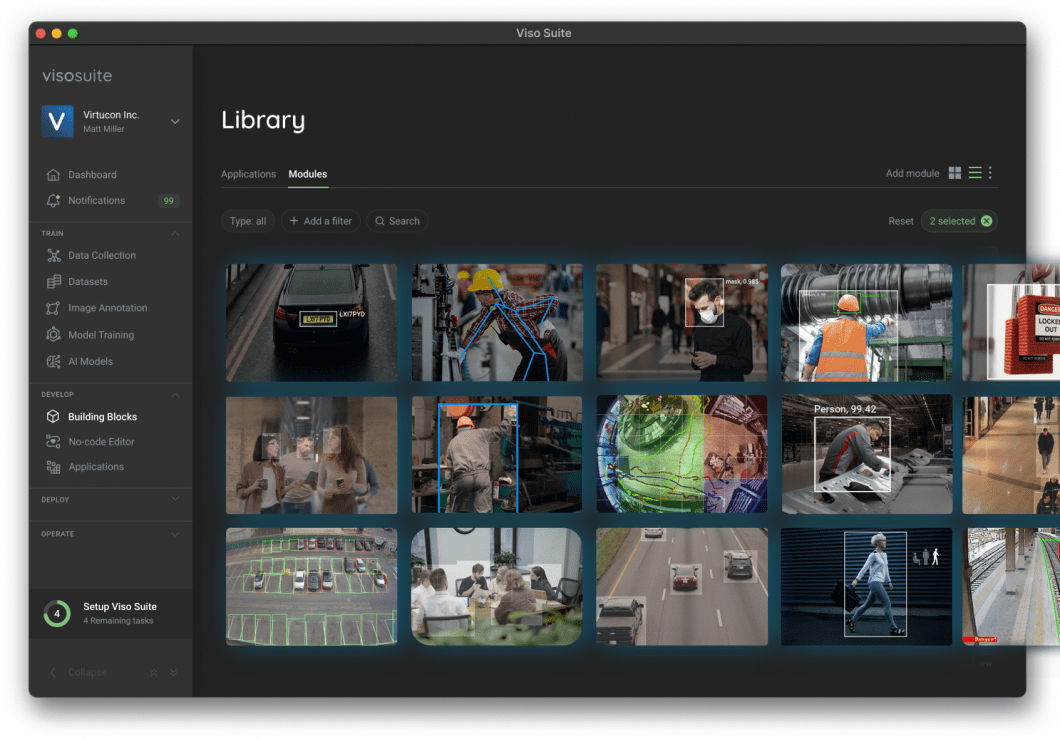
What’s Experiment Monitoring for Machine Studying?
Experiment monitoring is the self-discipline of recording related metadata whereas creating a machine studying mannequin. It supplies researchers with a technique to maintain observe of essential modifications throughout every iteration.
On this context, “experiment” refers to a selected iteration or model of the mannequin. You possibly can consider it by way of some other scientific experiment:
- You begin with a speculation, i.e., how new modifications will influence the outcomes.
- Then, you alter the inputs (code, datasets, or hyperparameters) accordingly and run the experiment.
- Lastly, you report the outputs. These outputs could be the outcomes of efficiency benchmarks or a completely new ML mannequin.
Machine studying experiment monitoring makes it attainable to hint the precise trigger and impact of modifications to the mannequin.
These parameters embody, amongst others:
- Hyperparameters: Studying fee, batch dimension, variety of layers, neurons per layer, activation capabilities, dropout charges.
- Mannequin Efficiency Metrics: Accuracy, precision, recall, F1 rating, space beneath the ROC curve (AUC-ROC).
- Coaching Parameters: Variety of epochs, loss perform, optimizer kind.
- {Hardware} Utilization: CPU/GPU utilization, reminiscence utilization.
- Dataset Metrics: Measurement of coaching/validation/check units, knowledge augmentation strategies used.
- Coaching Setting: Configuration information of the underlying system or software program ecosystem.
- Versioning Info: Mannequin model, dataset model, code model.
- Run Metadata: Timestamp of the run, period of coaching, experiment ID.
- Mannequin-specific Knowledge: Mannequin weights or different tuning parameters.
Experiment monitoring entails monitoring all info to create reproducible outcomes throughout each stage of the ML mannequin growth course of.
Why is ML Experiment Monitoring Necessary?
We derive machine studying fashions by means of an iterative strategy of trial and error. Researchers can alter any variety of parameters in numerous combos to provide completely different outcomes. A mannequin may also undergo an immense variety of diversifications or variations earlier than it reaches its last kind.
With out understanding the what, why, and the way, it’s inconceivable to attract knowledgeable conclusions concerning the mannequin’s progress. Sadly, because of the complexity of those fashions, the causality between inputs and outputs is commonly non-obvious.
studying – source.
A small change in any of the parameters above can considerably change the output. An advert hoc strategy to monitoring these modifications and their results on the mannequin merely received’t reduce it. That is significantly essential for associated duties, comparable to hyperparameter optimization.
Knowledge scientists want a proper course of to trace these modifications over the lifetime of the event course of. Experiment monitoring makes it attainable to match and reproduce the outcomes throughout iterations.
This enables them to grasp previous outcomes and the cause-and-effect of adjusting numerous parameters. Extra importantly, it would assist to extra effectively steer the coaching course of in the best route.
How does an ML Experiment Monitoring System work?
Earlier than we take a look at completely different strategies to implement experiment monitoring, let’s see what an answer ought to appear like.
On the very least, an experiment-tracking answer ought to offer you:
- A centralized hub to retailer, set up, entry, and handle experiment information.
- Simple integration together with your ML mannequin coaching framework(s).
- An environment friendly and correct option to seize and report important knowledge.
- An intuitive and accessible option to pull up information and evaluate them.
- A option to leverage visualizations to symbolize knowledge in ways in which make sense to non-technical stakeholders.
For extra superior ML fashions or bigger machine studying initiatives, you may additionally want the next:
- The power to trace and report {hardware} useful resource consumption (monitoring of CPU, GPU utilization, and reminiscence utilization).
- Integration with model management methods to trace code, dataset, and ML mannequin modifications.
- Collaboration options to facilitate staff productiveness and communication.
- Customized reporting instruments and dashboards.
- The power to scale with the rising variety of experiments and supply sturdy safety.
Experiment monitoring ought to solely be as advanced as you want it to be. That’s why strategies fluctuate from manually utilizing paper or spreadsheets to totally automated commercial-off-the-shelf instruments.
The centralized and collaborative facet of experiment monitoring is especially essential. You might conduct experiments on ML fashions in quite a lot of contexts. For instance, in your workplace laptop computer at your desk. Or to run an advert hoc hyperparameter tuning job utilizing a devoted occasion within the cloud.
Now, extrapolate this problem throughout a number of people or groups.
Should you don’t correctly report or sync experiments, it’s possible you’ll must repeat work. Or, worst case, lose the main points of a well-performing experiment.
Finest Practices in ML Experiment Monitoring
So, we all know that experiment monitoring is significant to precisely reproduce experiments. It permits debugging and understanding ML fashions at a granular degree. We additionally know the elements that an efficient experiment monitoring answer ought to encompass.
Nevertheless, there are additionally some greatest practices you must follow.
- Set up a standardized monitoring protocol: It’s essential to have a constant follow of experiment monitoring throughout ML initiatives. This contains standardizing code documentation, model documentation, knowledge units, parameters (enter knowledge), and outcomes (output knowledge).
- Have rigorous model management: Implement each code and knowledge model management. This helps observe modifications over time and to grasp the influence of every modification. You need to use instruments like Git for code and DVC for knowledge.
- Automate knowledge logging: It’s best to automate experiment logging as a lot as attainable. This contains capturing hyperparameters, mannequin architectures, coaching procedures, and outcomes. Automation reduces human error and enhances consistency.
- Implement meticulous documentation: Alongside automated logging, clarify the rationale behind every experiment, the hypotheses examined, and interpretations of outcomes. Contextual info is invaluable for future reference when engaged on dynamic ML fashions.
- Go for scalable and accessible monitoring instruments: This can assist keep away from delays as a result of operational constraints or the necessity for coaching.
- Prioritize reproducibility: Test that you may reproduce the outcomes of particular person experiments. You want detailed details about the setting, dependencies, and random seeds to do that precisely.
- Common opinions and audits: Reviewing experiment processes and logs can assist determine gaps within the monitoring course of. This lets you refine your monitoring system and make higher choices on future experiments.
- Incorporate suggestions loops: Equally, this can enable you incorporate learnings from previous experiments into new ones. It should additionally assist with staff buy-in and handle shortcomings in your methodologies.
- Stability element and overhead: Over-tracking can result in pointless complexity, whereas inadequate monitoring can miss essential insights. It’s essential to discover a stability relying on the complexity of your ML fashions and desires.

Distinction Between Experiment Monitoring and MLOps
Should you work in an ML staff, you’re most likely already conversant in MLOps (machine studying operations). MLOps is the method of holistically managing the end-to-end machine studying growth lifecycle. It spans the whole lot from:
- Growing and coaching fashions,
- Scheduling jobs,
- Mannequin testing,
- Deploying fashions,
- Mannequin upkeep,
- Managing mannequin serving, to
- Monitoring and retraining fashions in manufacturing
Experiment monitoring is a specialised sub-discipline inside the MLOps area. Its main focus is the iterative growth section, which entails primarily coaching and testing fashions. To not point out experimenting with numerous fashions, parameters, and knowledge units to optimize efficiency.
Extra particularly, it’s the method of monitoring and using the related metadata of every experiment.
Experiment monitoring is particularly essential for MLOps in research-focused initiatives. In these initiatives, fashions could by no means even attain manufacturing. As an alternative, experiment monitoring gives helpful insights into mannequin efficiency and the efficacy of various approaches.
This will likely assist inform or direct future ML initiatives with out having a right away utility or finish aim. MLOps is of extra essential concern in initiatives that may enter manufacturing and deployment.
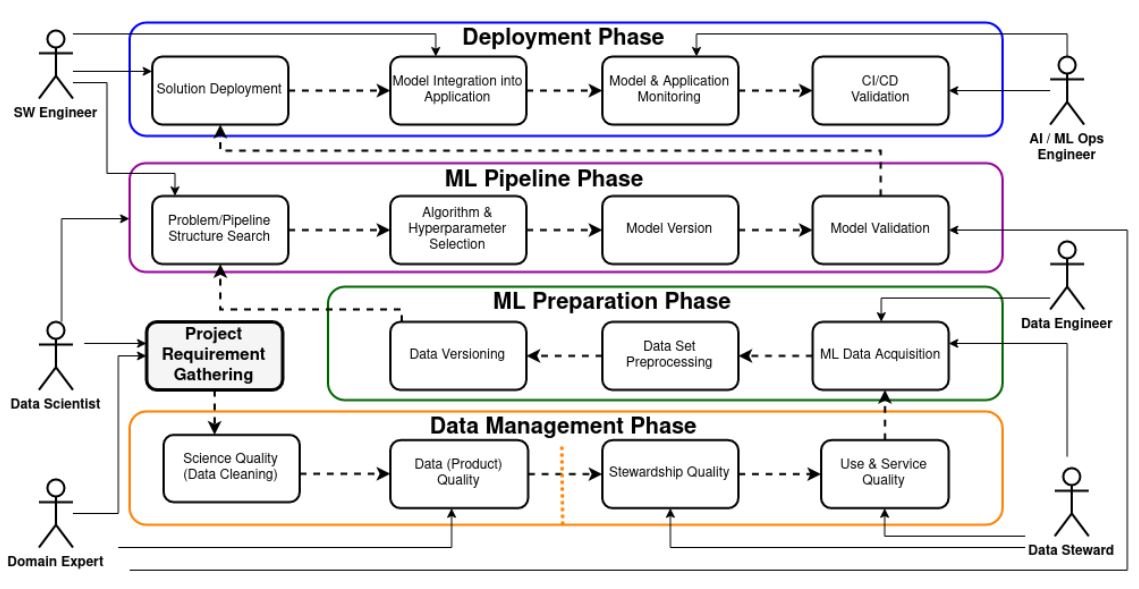
Methods to Implement Experiment Monitoring
Machine studying initiatives come in numerous sizes and shapes. Accordingly, there are a number of the way you’ll be able to observe your experiments.
It’s best to fastidiously choose the very best strategy relying on:
- The dimensions of your staff
- The variety of experiments you propose to run
- The complexity of your ML fashions
- The extent of element you require relating to experiment metadata
- The important thing objectives of your challenge/analysis. I.e., bettering capabilities in a selected job or optimizing efficiency
Among the widespread strategies used immediately embody:
- Guide monitoring utilizing spreadsheets and naming conventions
- Utilizing software program versioning instruments/repositories
- Automated monitoring utilizing devoted ML experiment monitoring instruments
Let’s do a fast overview of every.
Guide Monitoring
This entails utilizing spreadsheets to manually log experiment particulars. Sometimes, you’ll use systematic naming conventions to prepare information and experiments in directories. For instance, by naming them after components like mannequin model, studying fee, batch dimension, and major outcomes.
For instance, model_v3_lr0.01_bs64_acc0.82.h5 would possibly point out model 3 of a mannequin with a studying fee of 0.01, a batch dimension of 64, and an accuracy of 82%.
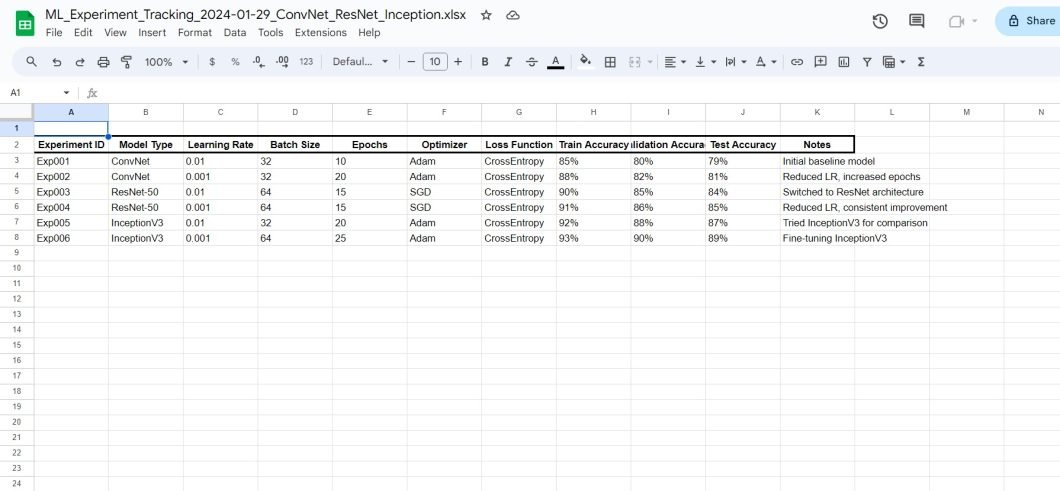
This methodology is simple to implement, but it surely falls aside at scale. Not solely is there a danger of logging incorrect info, but in addition overwriting others’ work. Plus, manually guaranteeing model monitoring conventions are being adopted could be time-consuming and troublesome.
Nonetheless, it could be appropriate for small-scale or private analysis initiatives utilizing instruments like Excel or Google Sheets.
Automated Versioning in a Git Repository
You need to use a model management system, like Git, to trace modifications in machine studying experiments. Every experiment’s metadata (like hyperparameters, mannequin configurations, and outcomes) is saved as information in a Git repository. These information can embody textual content paperwork, code, configuration information, and even serialized variations of fashions.
After every experiment, it commits modifications to the repository, making a trackable historical past of the experiment iterations.
Whereas it’s not totally automated, it does carry a few of its advantages. For instance, the system will routinely observe the naming conventions you implement. This reduces the danger of human error whenever you log metrics or different knowledge.
It’s additionally a lot simpler to revert to older variations with out having to create, set up, and discover copies manually. They’ve the built-in capability to department and run parallel workflows.
These methods even have built-in collaboration, making it simple for staff members to trace modifications and keep in sync. Plus, it’s comparatively technology-agnostic, so you should use it throughout initiatives or frameworks.
Nevertheless, not all these methods are optimized for big binary information. That is very true for ML fashions the place large knowledge units containing mannequin weights and different metadata are widespread. Additionally they have restricted options for visualizing and evaluating experiments, to not point out reside monitoring.
This strategy is very helpful for initiatives that require an in depth historical past of modifications. Additionally, many builders are conversant in platforms like Git, so adoption must be seamless for many groups. Nevertheless, it nonetheless lacks a few of the superior capabilities on provide with devoted MLOps or experiment monitoring software program.

Utilizing Trendy Experiment Monitoring Instruments
There are specialised software program options designed to systematically report, set up, and evaluate knowledge from machine studying experiments. designed particularly for ML initiatives, they sometimes provide seamless integration with widespread fashions and frameworks.
On prime of instruments to trace and retailer knowledge, in addition they provide a person interface for viewing and analyzing outcomes. This contains the flexibility to visualise knowledge and create customized studies. Builders may also sometimes leverage APIs for logging knowledge to numerous methods and evaluate completely different runs. Plus, they’ll monitor experiment progress in real-time.
Constructed for ML fashions, they excel at monitoring hyperparameters, analysis metrics, mannequin weights, and outputs. Their functionalities are well-suited to typical ML duties.
Widespread experiment monitoring instruments embody:
- MLFlow
- CometML
- Neptune
- TensorBoard
- Weights & Biases
The Viso Suite platform additionally gives sturdy experiment monitoring by means of its mannequin analysis instruments. You possibly can achieve complete insights into the efficiency of your laptop imaginative and prescient experiments. Its vary of functionalities contains regression, classification, detection analyses, semantic, and occasion segmentation, and so forth.
You need to use this info to determine anomalies, mine arduous samples, and detect incorrect prediction patterns. Interactive plots and label rendering on photos facilitate knowledge understanding, augmenting your MLOps decision-making.
What’s Subsequent With Experiment Monitoring?
Experiment monitoring is a key element of ML mannequin growth, permitting for the recording and evaluation of metadata for every iteration. Integration with complete MLOps practices enhances mannequin lifecycle administration and operational effectivity, which means that organizations can drive steady enchancment and innovation of their ML initiatives.
As experiment monitoring instruments and methodologies evolve, we are able to count on to see the mannequin growth course of change and enhance as properly.
Посетите наш Интернет магазин 3D принтеров, чтобы найти идеальное оборудование для ваших творческих проектов!
предоставят – предложат
Найдите идеальный вариант для своего бизнеса и slm 3d принтер купить|3д принтер slm купить|slm принтер по металлу купить|slm принтер купить уже сегодня!
Обязательно уточняйте условия доставки и возврата, чтобы избежать неудобств.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Внедрение wms системы на складе позволяет значительно оптимизировать процессы учета и управления товарными запасами.
Применение WMS открывает новые горизонты для эффективного управления запасами. Системы управления складом (WMS) помогают автоматизировать множество процессов .
Начать с внедрения WMS необходимо с оценки существующих логистических операций . Важно выявить узкие места и определить области, требующие улучшения .
Выбор правильного WMS-соftware критически важен для успешности проекта . Выбор WMS должен учитывать специфику вашего бизнеса и объемы поставок.
Внедрение WMS – это сложный и многоуровневый процесс . Важно вовлечь всех сотрудников, чтобы минимизировать сопротивление изменениям .
3d принтер по металлу купить обеспечивает высокую точность и качество изделий, что делает его идеальным выбором для промышленных потребностей.
Создание металла с помощью 3D принтера открывает новые горизонты в железнодорожном производстве. Каждый год появляется множество инноваций, которые облегчают процесс печати. Устройства 3D печати по металлу все чаще используются в различных отраслях.
3D печать металла открывает новые возможности для инженеров. С помощью эту технологию, можно создавать сложные детали с высокой точностью. В дополнение, процессы стали более эффективными и экономичными. Таким образом, возможно сократить время на производство и снизить затраты.
Методы 3D печати металла основаны на слойном подходе, где каждая деталь добавляется последовательно. Это позволяет создавать объекты, которые невозможно изготовить другими способами. Ключевым моментом становится контроль качества на каждом этапе производства детали.
Развитие аддитивных технологий выглядит очень многообещающим. С течением времени технологии совершенствуются, и появляются новые решения. предоставляет возможности для новых проектов и улучшает существующие. Скоро мы можем ожидать доступности 3D принтеров по металлу на рынке.
Промышленный 3D принтер открывает новые горизонты для производств, позволяя создавать сложные детали с высокой точностью и эффективностью.
В то же время,
профессиональные 3d сканеры купить предоставляют высококачественное 3D моделирование, обеспечивая точность и детализацию для различных профессиональных сфер.
В современных условиях профессиональные 3D сканеры находят свое применение в разных сферах.
3д сканер купить
Их использование позволяет создавать точные цифровые модели реальных объектов.
3d сканер промышленный купить становятся всё более востребованными в производственной сфере благодаря своей точности и эффективности.
Доступность промышленных 3D сканеров растет, способствуя их широкому распространению.
Современные решения в сфере основные направления автоматизации логистики помогают значительно повысить эффективность и сократить затраты на перевозку и хранение товаров.
Автоматизация логистики приносит множество выгод, таких как скорость и точность.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.