
True to its identify, Explainable AI refers back to the instruments and strategies that specify AI programs and the way they arrive at a sure output. Synthetic Intelligence is utilized in each sphere of at this time’s digital world. Synthetic Intelligence (AI) fashions help throughout varied domains, from regression-based forecasting fashions to complicated object detection algorithms in deep studying.
For instance, think about the case of the tumor detection CNN mannequin utilized by a hospital to display its affected person’s X-rays. However, how can a technician or the affected person belief its consequence once they don’t know the way it works? That’s precisely why we want strategies to grasp the elements influencing the selections made by any deep studying mannequin. On this weblog, we’ll dive into the necessity for AI explainability, the varied strategies out there at the moment, and their purposes.
Why do we want Explainable AI (XAI)?
The complexity of machine studying fashions has exponentially elevated from linear regression to multi-layered neural networks, CNNs, transformers, and so forth. Whereas neural networks have revolutionized the prediction energy, they’re additionally black-box fashions.
The structure and mathematical computation that goes beneath the hood are very complicated to be deciphered by information scientists too. We want a separate set of instruments to interpret and perceive them. Let’s have a look at the principle causes behind this:
- Consumer Understanding and Belief: With Explainable AI, the transparency of how the choice is made will increase. This could in flip enhance the belief of finish customers, and adoption may even enhance.
- Compliance and Laws: Any firm utilizing AI for advertising and marketing suggestions, monetary choices, and so forth.. must adjust to a set of laws imposed by every nation they function. For instance, it’s unlawful to make use of PII (Private Identifiable Info) such because the deal with, gender, and age of a buyer in AI fashions. With the assistance of XAI, corporations can simply show their compliance with laws corresponding to GDPR (Normal Knowledge Safety Regulation).
- Establish & Take away Bias: AI fashions are mathematically error-proof, however they don’t perceive ethics and equity. That is essential, particularly in industries like finance, banking, and so forth. For instance, think about a credit score threat prediction mannequin of a financial institution. If the mannequin offers a high-risk rating to a buyer based mostly on their area neighborhood, or gender, then it’s biased in direction of a particular part. XAI instruments can present the influencing elements behind each prediction, serving to us determine current mannequin biases.
- Steady Enchancment: Knowledge scientists face many points after mannequin deployment like efficiency degradation, information drift, and so forth. By understanding what goes beneath the hood with Explainable AI, information groups are higher geared up to enhance and keep mannequin efficiency, and reliability.
- Error Detection and Debugging: A serious problem ML engineers face is debugging complicated fashions with tens of millions of parameters. Explainable AI helps determine the actual segments of a difficulty and errors within the system’s logic or coaching information.
Methodologies of Explainable AI (XAI)
Explainable AI affords instruments and processes to elucidate completely different traits of each merely explainable ML fashions and the black field ones. For explainable fashions like linear and logistic regression, loads of info may be obtained from the worth of coefficients and parameters. Earlier than we dive into the completely different strategies, you could know that ML fashions may be defined at two ranges: International and Native.
What are International and Native Explanations?
International Explanations: The purpose of XAI at a worldwide degree is to elucidate the habits of the mannequin throughout your entire dataset. It offers insights into the principle elements influencing the mannequin, and the general developments and patterns noticed. That is helpful to elucidate how your mannequin works to the enterprise stakeholders. For instance, think about the case of threat modeling for approving private loans to clients. International explanations will inform the important thing elements driving credit score threat throughout its total portfolio and help in regulatory compliance.
Native Explanations: The purpose of XAI on the native degree is to offer insights into why a selected choice was made for a particular enter. Why do we want native explanations? Think about the identical instance of credit score threat modeling. Let’s say the financial institution notices poor efficiency within the section the place clients don’t have earlier mortgage info. How will you already know the precise elements at play for this section? That’s precisely the place native explanations assist us with the roadmap behind each particular person prediction of the mannequin. Native explanations are extra useful in narrowing down the present biases of the mannequin. Now, let’s check out just a few prominently used strategies:
SHAP
It’s the most generally used technique in Explainable AI, because of the flexibility it offers. It comes with the benefit of offering each native and international degree explanations, making our work simpler. SHAP is brief for Shapley Additive Explanations.
Allow us to perceive how Shapley’s values work with a hands-on instance. I’ll be utilizing the diabetes dataset to display on this weblog. This dataset is offered to the general public in Kaggle. First, load and skim the dataset right into a pandas information body.
# Import obligatory packages
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
df = pd.read_csv('../enter/pima-indians-diabetes-database/diabetes.csv')
df.head()
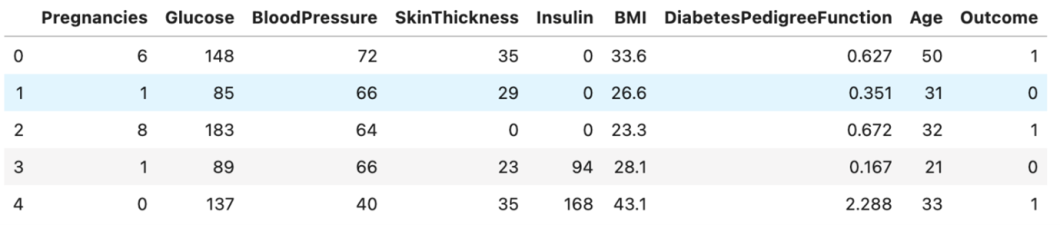
You’ll be able to see that we’ve options (X) like glucose degree, blood strain, and so forth.. and the goal is ‘End result’. Whether it is 1, then we predict the affected person to have diabetes and be wholesome whether it is 0.
Subsequent, we prepare a easy XGBoost mannequin on the coaching information. These steps are proven within the beneath code snippet.
# Outline options and goal
X = df.iloc[:, :-1]
y = df.iloc[:, -1]
# Cut up the dataset into 75% for coaching and 25% for testing
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
mannequin = XGBClassifier(random_state=42)
mannequin.match(X_train, y_train)
rating = mannequin.rating(X_test, y_test)
Our mannequin is prepared and can be utilized to make predictions on the take a look at information. First, Let’s perceive interpret SHAP values domestically – for a single prediction. Right here’s how one can compute shap values for every prediction:
# Load the mannequin into the TreeExplainer operate of shap
import shap
explainer = shap.TreeExplainer(mannequin)
shap_values = explainer.shap_values(X)
Now you can get a drive plot for a single prediction on the take a look at information utilizing the beneath code:
shap.force_plot(explainer.expected_value, shap_values[0, :], X_test.iloc[0, :])

Right here, the bottom worth is the common prediction of the mannequin. The contribution from every function is proven within the deviation of the ultimate output worth from the bottom worth. Blue represents optimistic affect and pink represents unfavourable affect(excessive possibilities of diabetes).
What if you wish to understand how all options have an effect on the goal at an general degree (international)?
You’ll be able to visualize the affect magnitude and nature of every function utilizing the abstract plot operate that’s out there within the shap bundle:
shap.summary_plot(shap_values, X_test)
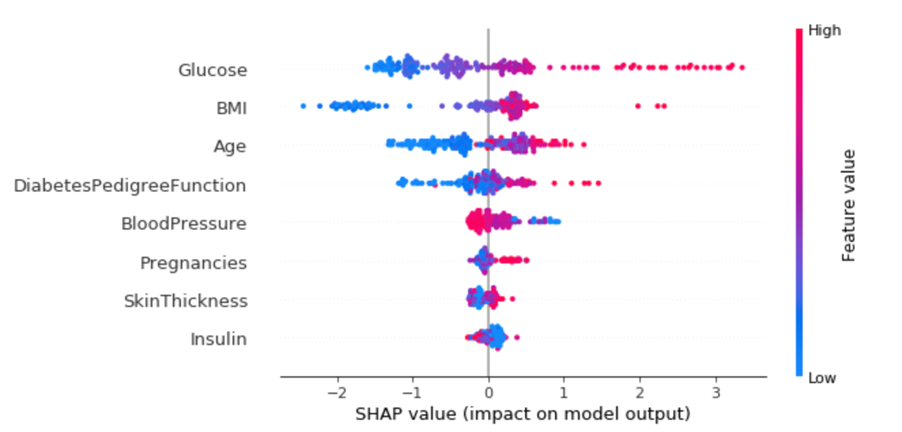
What can we are saying from this?
- Excessive values of ‘Glucose’ imply larger possibilities of diabetes
- Low BMI and age would imply a low threat of diabetes
Put your abilities to the take a look at: Attempt to interpret different options equally!
Total, SHAP is a sturdy technique that can be utilized on all sorts of fashions, however could not give good outcomes with excessive dimensional information.
Partial Dependence Plots
It’s one of many easiest strategies to grasp how completely different options work together with one another and with the goal. On this technique, we alter the worth of 1 function, whereas preserving others fixed and observe the change within the dependent goal. This technique permits us to determine areas the place the change in function values has an important affect on the prediction.
The Python partial dependence plot toolbox or PDPbox is a bundle that gives features to visualise these. In the identical case of diabetes prediction, allow us to see plot partial dependence plots for a single function:
# Outline function names
feature_names = ['Pregnancies', 'Glucose', 'BloodPressure','SkinThickness', 'Insulin','BMI', 'DiabetesPedigreeFunction', 'Age']
# Import module
from pdpbox import pdp, get_dataset, info_plots
# Plot PDP for a single function
pdp_goals = pdp.pdp_isolate(mannequin=mannequin, dataset=X_test, model_features=feature_names, function="Glucose")
pdp.pdp_plot(pdp_goals, 'Glucose')
plt.present()
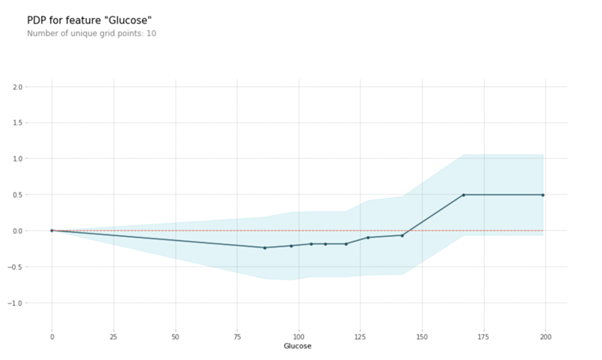
You’ll be able to see the variation in goal on the Y-axis for a rise within the ‘Glucose’ worth on the X-axis. We will observe that when the glucose worth ranges between 125 and 175, the affect is growing at the next fee.
Let’s additionally have a look at the PDP of BMI. You’ll be able to see that when BMI is lower than 100, the goal is sort of fixed. Publish that, we see a linear enhance.
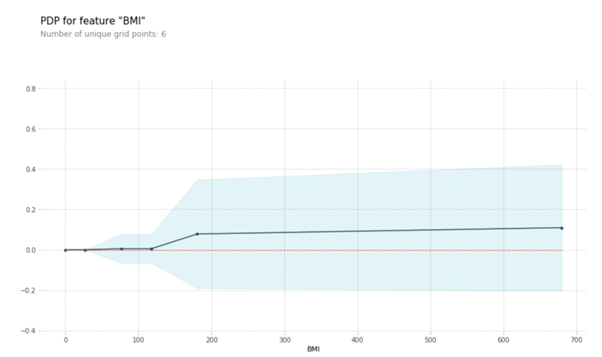
PDP additionally permits you to visualize the interplay between two options, and their mixed affect on the goal. Let’s plot the interplay of BMI and Age beneath:
# Use the pdp_interact() operate
interplay = pdp.pdp_interact(mannequin=mannequin, dataset=X_test, model_features=feature_names, options=['Age','BMI'])
# Plot the graph
pdp.pdp_interact_plot(pdp_interact_out=interplay, feature_names=['Age','BMI'], plot_type="contour", plot_pdp=True)
plt.present()
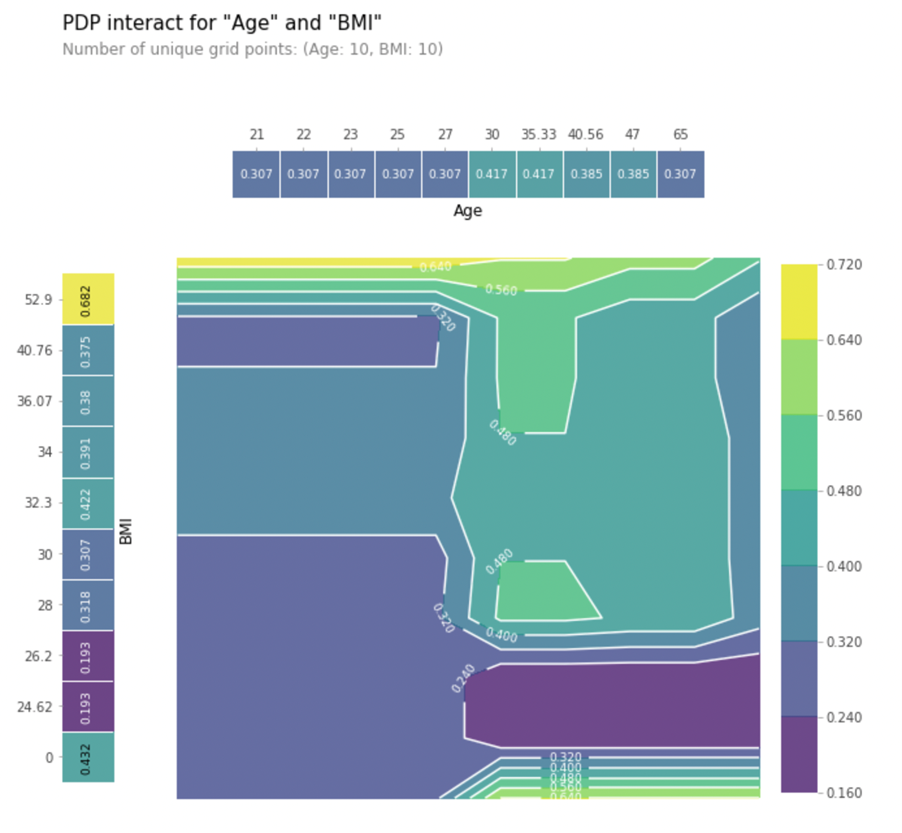
Observe how the colour modifications as you progress throughout X-axis (Age) and Y-axis (BMI). You’ll be able to observe that when the age is decrease than 30, BMI has the next affect. When the age is above 30, the interplay modifications.
Permutation Function Significance
It’s a easy and intuitive technique to search out the function significance and rating for non-linear black field fashions. On this technique, we randomly shuffle or change the worth of a single function, whereas the remaining options are fixed.
Then, we examine the mannequin efficiency utilizing related metrics corresponding to accuracy, RMSE, and so forth., achieved iteratively for all of the options. The bigger the drop in efficiency after shuffling a function, the extra vital it’s. If shuffling a function has a really low affect, we will even drop the variable to scale back noise.
You’ll be able to compute the permutation function significance in just a few easy steps utilizing the Tree Interpreter or ELI5 library. Let’s see compute it for our dataset:
# Import the bundle and moduleimport eli5from eli5.sklearn import PermutationImportance
# Move the mannequin and take a look at datasetmy_set = PermutationImportance(mannequin, random_state=34).match(X_test,y_test)eli5.show_weights(my_set, feature_names = X_test.columns.tolist())
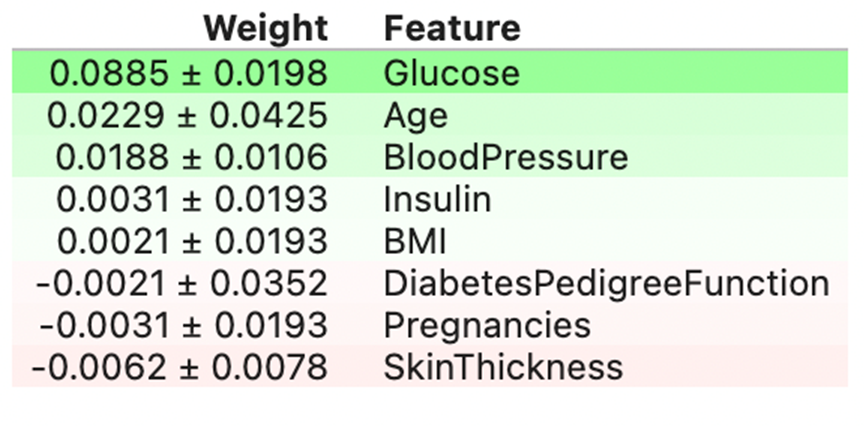
You’ll get an output just like the above, with the function significance and its error vary. We will see that Glucose is the highest function, whereas Pores and skin thickness has the least impact.
One other benefit of this technique is that it may deal with outliers and noise within the dataset. This explains the options at a worldwide degree. The one limitation is the excessive computation prices when the dataset sizes are excessive.
LIME
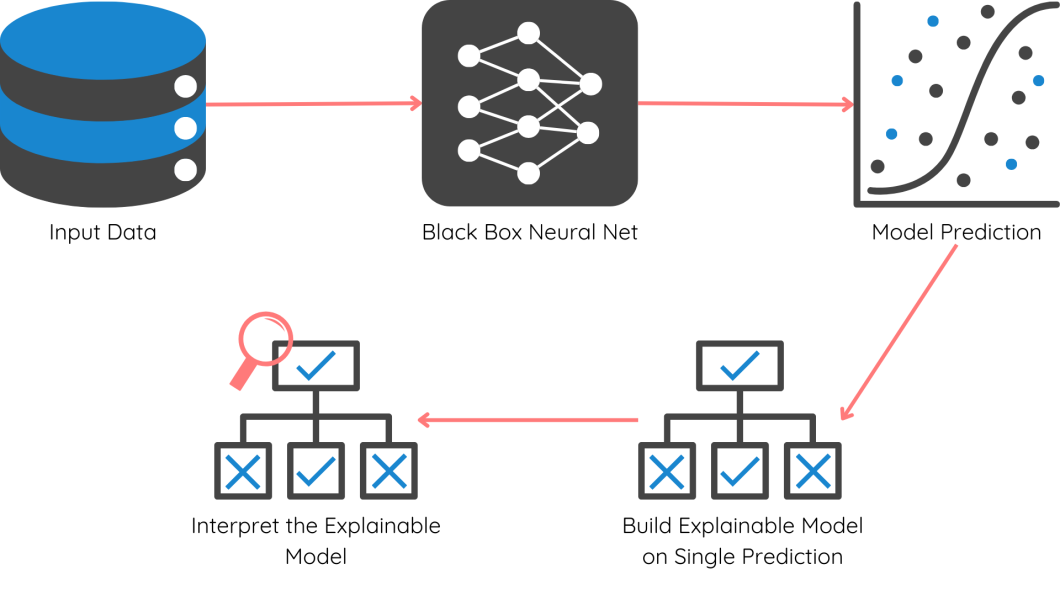
Native Interpretable Mannequin-Agnostic Explanations (LIME) is extensively used for explaining black field fashions at an area degree. When we’ve complicated fashions like CNNs, LIME makes use of a easy explainable mannequin to grasp its prediction. To make it easier, let’s see how LIME works in a step-wise method:
- Outline your native level: Select a particular prediction you need to clarify (e.g., why a picture was categorised as a cat by a CNN).
- Generate variations: Create slight variations of the enter information (e.g., barely modified pixels within the picture).
- Predict with the unique mannequin: Move the enter to CNN and get the expected output class for every variation.
- Construct an explainer mannequin: Prepare a easy linear mannequin to elucidate the connection between the variations and the mannequin’s predictions.
- Interpret the explainer: Now, you’ll be able to interpret the explainer mannequin with any technique like function significance, PDP, and so forth..to grasp which options performed an important position within the unique prediction.
Other than these, different outstanding Explainable AI strategies embody ICE plots, Tree surrogates, Counterfactual Explanations, saliency maps, and rule-based fashions.
Actual World Purposes
Explainable AI is the bridge that builds belief between the world of expertise and people. Let’s have a look at some highly effective explainable AI examples in our on a regular basis world:
- Honest lending practices: Explainable AI (XAI) can present banks with clear explanations for mortgage denials. Companies may be risk-free from compliances and likewise enhance the belief of their buyer base
- Take away bias in recruitment: Many corporations use AI programs to initially display a lot of job purposes. XAI instruments can reveal any biases embedded in AI-driven hiring algorithms. This ensures honest hiring practices based mostly on benefit, not hidden biases.
- Enhance adoption of autonomous autos: What number of of you’ll belief a driverless automobile at this time? XAI can clarify the decision-making technique of self-driving automobiles on the highway, like lane modifications or emergency maneuvers. This can enhance the belief of passengers.
- Enhance medical diagnostics: XAI can present transparency within the diagnostic course of by offering a publish hoc rationalization of mannequin outputs, or diagnoses. This permits medical professionals to realize a extra holistic view of the affected person’s case at hand. Discover an instance involving diagnosing a COVID-19 an infection within the picture beneath.
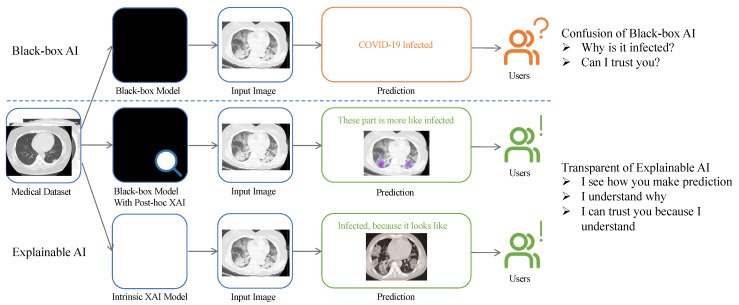
What’s Subsequent With XAI?
If deep studying explainable AI is to be an integral a part of our companies going forward, we have to observe accountable and moral practices. Explainable AI is the pillar for accountable AI improvement and monitoring. I hope you have got understanding of the principle Explainable AI strategies, their benefits, and limitations.
Among the many completely different XAI strategies on the market, you could select based mostly in your necessities for international or native explanations, information set dimension, computation assets out there, and so forth. International explanations won’t seize the nuances of particular person information factors. Native explanations may be computationally costly, particularly for complicated fashions. The trade-off is the place your business data will assist you to!
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.