

The inspiration of pc imaginative and prescient analysis is deep options, which seize visible semantics. They permit engineers to carry out downstream duties even within the few-shot or zero-shot regime.
Think about taking a fast have a look at a crowded avenue after which making an attempt to recall the state of affairs by drawing it. Practically nobody can draw each element with pixel-perfect accuracy. Nonetheless, most people can sketch the final places of the primary issues, akin to vehicles, folks, and crosswalks.
The vast majority of up to date pc imaginative and prescient algorithms are additionally wonderful at capturing high-level elements of an image, however as they course of knowledge, they lose fine-grained particulars.
About us: Viso Suite is the end-to-end pc imaginative and prescient platform for enterprises. Inside the platform, groups can seamlessly construct, deploy, handle, and scale their clever AI purposes.
What’s a FeatUp Algorithm?
In March 2024, MIT researchers M. Hamilton, S. Fu et al. launched FeatUp, a task- and model-agnostic framework to revive misplaced spatial info in deep options. They introduced two FeatUp variations: one that matches an implicit mannequin to a single picture to reconstruct options at any decision. The opposite – uncovers options with high-resolution sign in a single ahead cross. They utilized NeRF multi-view consistency loss deep analogies in each strategies.
By way of a course of generally known as “options,” computer systems which can be educated to “see” by observing photos and movies – develop “concepts” about what’s current in a scene. Deep networks and visible basis fashions generate these options by dividing pictures right into a grid of small squares. Then they course of the squares collectively to establish the that means of an image.
These algorithms’ decision is way decrease than that of the pictures they function on as a result of every tiny sq. sometimes consists of 16-32 pixels. Algorithms lose a lot pixel element when making an attempt to summarize and comprehend pictures.

With out sacrificing pace or high quality, the FeatUp algorithm could stop this info loss and improve the decision of any deep community. This makes it potential for researchers to swiftly improve the decision of any methodology, whether or not it’s new or previous.
Think about making an attempt to find the tumor by analyzing the predictions of a lung most cancers detection algorithm. Utilizing FeatUp with strategies akin to class activation maps (CAM) can produce a considerably extra detailed (16-32x) picture of the tumor’s potential location.
How does FeatUp Work?
FeatUp is a singular framework that MIT researchers introduced to extend the decision of any imaginative and prescient mannequin’s options with out altering their preliminary “that means” or orientation. Their foremost discovery was motivated by 3D reconstruction frameworks akin to NeRF. They proved that high-resolution indicators may be supervised by the multiview consistency of low-resolution indicators.
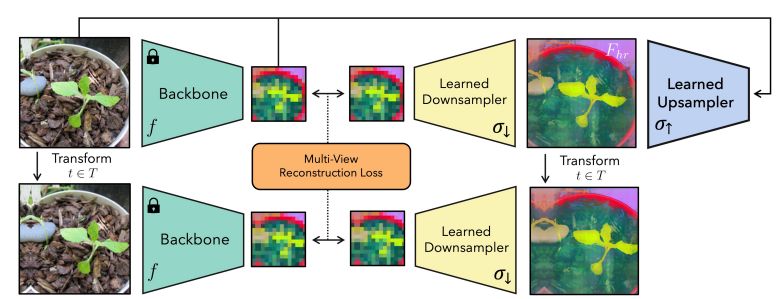
Extra exactly, by combining low-resolution views from a mannequin’s outputs over a number of “jittered” (akin to flipped, padded, or cropped) pictures, scientists had been capable of be taught high-resolution info. They realized an upsampling community with a multiview consistency loss to mixture this knowledge.
Their workflow begins by creating low-resolution characteristic views, that are then refined right into a single high-resolution output. To attain this, researchers apply the mannequin to every altered picture to extract a set of low-resolution characteristic maps. They did this by perturbing the enter picture with minor pads, scales, and horizontal flips.
These views had been then utilized by researchers to create a constant high-resolution characteristic map. In accordance with their speculation, they could be taught a latent high-resolution characteristic map that will replicate their low-resolution jittered options when downsampled (see picture above).
FeatUp’s downsampler converts high-resolution options into low-resolution options, which is a direct analog of ray-marching, which renders 3D knowledge into 2D on this NeRF stage. They didn’t should estimate the parameters that produced every view, not like NeRF.
Relatively, earlier than downsampling, researchers carried out the identical transformation to their realized high-resolution options whereas monitoring the settings used to “jitter” every picture. Reconstructing the noticed options throughout all viewpoints is a should for a high-resolution characteristic map.
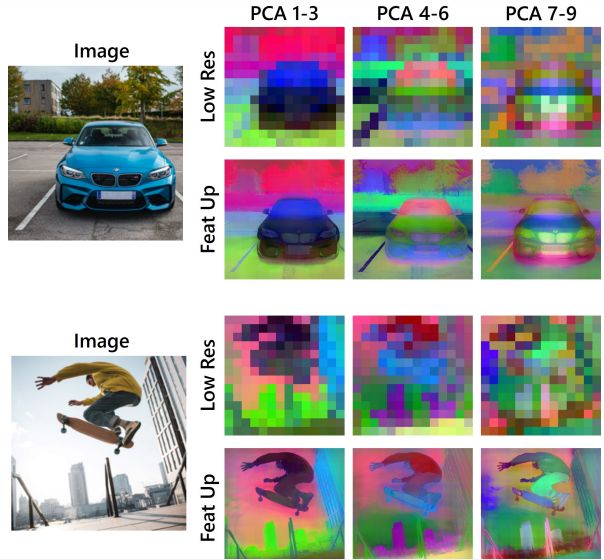
Selecting Upsampler
The crew investigated two upsampling architectures:
- An implicit illustration overfit to a single picture
- A single guided upsampling feedforward community that generalizes throughout pictures.
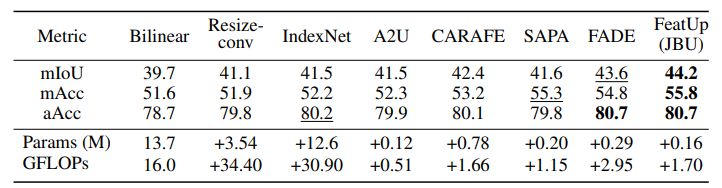
The feedforward upsampler is a parameterized generalization of a Joint Bilateral Upsampling (JBU) filter. It was quicker and makes use of much less reminiscence than earlier variations. CUDA kernel empowers this implementation. For about the identical computational value as a couple of convolutions, this upsampler can generate high-quality options which can be aligned to object edges.
In a transparent analogy to NeRF, their implicit upsampler overfits a deep implicit community to a sign. Furthermore, it permits low storage prices and versatile decision traits. Neither structure’s approaches alter the that means of the options. Thus, upsampled options can be utilized as drop-in replacements in downstream purposes.
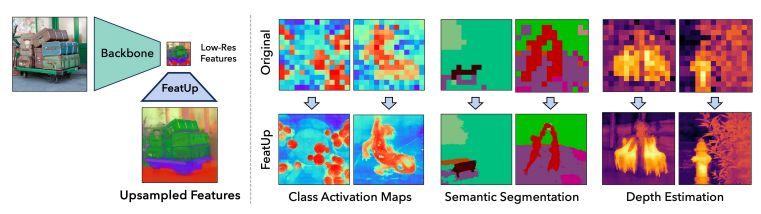
Researchers demonstrated how these upsampled options can tremendously improve a variety of downstream duties, akin to depth prediction and semantic segmentation. Additionally they demonstrated how upsampled options could also be used to make mannequin rationalization strategies like CAM increased decision.
Experiments and Efficiency
They first diminished the spatially various options to their prime okay=128 foremost parts. They aimed to decrease the reminiscence footprint and expedite the coaching of FeatUp’s implicit community. For the reason that prime 128 parts account for roughly 96% of the variance in a single picture’s traits, this process is basically lossless.
This permits for bigger batches, lowers the reminiscence footprint, will increase coaching time by an element of 60× for ResNet-50, and has no discernible affect on the standard of realized options. They confirmed how FeatUp is helpful in downstream purposes as a drop-in substitute for pre-existing options.
For instance this, researchers used the favored experimental methodology of assessing illustration high quality via linear probe switch studying. Moreover, they used low-resolution traits to coach linear probes for segmentation and depth prediction.
FeatUp purposes in Pc Imaginative and prescient
FeatUp can improve quite a lot of prediction duties like segmentation (assigning labels to pixels in a picture with object labels) and depth estimation, along with helping practitioners in understanding their fashions.
It accomplishes this by providing higher-resolution, extra correct traits, that are important for growing imaginative and prescient purposes starting from medical imaging to driverless automobiles.
Object Detection
The principle downside with up to date algorithms is that they condense huge pictures into tiny grids of “sensible” options, which ends up in the lack of finer particulars but additionally intelligent insights. FeatUp’s perceptive traits that floor from the depths of deep studying architectures can largely help in object detection duties.
In accordance with Mark Hamilton, a co-lead writer on a paper describing the undertaking and affiliate of the MIT Pc Science and Synthetic Intelligence Laboratory (CSAIL): FeatUp permits one of the best of each worlds: extraordinarily clever representations with the decision of the unique picture.
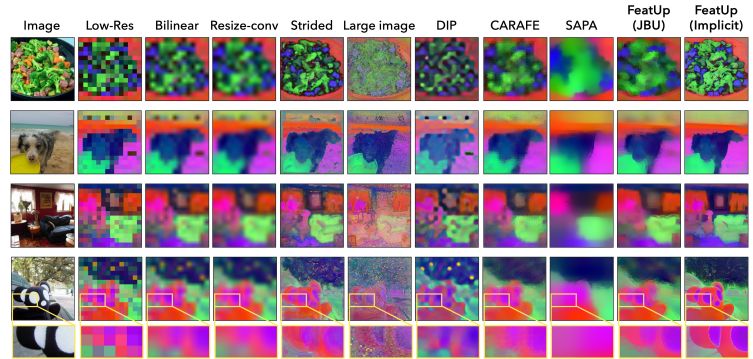
From growing object detection and depth prediction to high-resolution evaluation, these high-resolution options dramatically enhance efficiency throughout quite a lot of pc imaginative and prescient purposes.
Discovering Nice-grained Particulars
FeatUp methodology makes little alterations (akin to shifting the picture a couple of pixels to the left or proper). It observes how an algorithm reacts to those small picture actions. A single, clear, high-resolution set of deep options may be created by combining a whole bunch of barely distinct deep characteristic maps.
Researchers hypothesized that there are some high-resolution options that, when blurred and wiggled, will match all the lower-resolution options from the unique wiggling photographs. By way of the usage of this “sport,” which supplies suggestions on their efficiency, they wish to discover ways to rework low-resolution options into high-resolution ones.
By ensuring that the anticipated 3D merchandise matches each 2D photograph used to provide it, algorithms could generate a 3D mannequin from a number of 2D pictures. Furthermore, the methodology is akin to that course of. The high-resolution characteristic map predicted by FeatUp is per low-resolution options retain their unique semantics.

Of their seek for a fast and efficient resolution, the crew found that the conventional PyTorch instruments had been insufficient for his or her necessities and developed a brand new type of deep community layer. In comparison with a naïve implementation in PyTorch, their proprietary layer was greater than 100 occasions extra environment friendly.
Small Objects Retrieval
The researcher’s method permits correct object localization in a special software generally known as small object retrieval. As an illustration, algorithms enhanced with FeatUp can detect small gadgets like site visitors cones, reflectors, lights. Additionally – potholes when their low-resolution siblings are unable to, even in busy highway scenes. This illustrates the way it can rework coarse traits and carry out dense prediction duties.
In accordance with Stephanie Fu (2023) and one other co-lead writer on the brand new FeatUp, that is significantly vital for time-sensitive actions, like a driverless automotive finding a site visitors signal on a congested freeway.
Changing common guesses into exact localizations, cannot solely improve the accuracy of such jobs. It may additionally enhance the dependability, interpretability, and credibility of those programs.

The crew additionally demonstrated how this new layer would possibly improve a variety of strategies, akin to depth prediction and semantic segmentation. This layer considerably elevated the efficiency of any algorithm by enhancing the community’s capability to course of and comprehend high-resolution particulars.
Future Outlook
When it comes to future objectives, the group highlights FeatUp’s potential for broad use within the tutorial neighborhood and elsewhere. It’s much like knowledge augmentation strategies. Dr. Fu claimed: “The aim is to make FeatUp a elementary software in deep studying. It perceives the world in larger element with out the computational inefficiency of conventional high-resolution processing.”
Incessantly Requested Questions
Q1: What’s FeatUp?
Reply: FeatUp is a revolutionary algorithm (by MIT researchers, March 2024) that allows the conversion of low-resolution pictures and movies into helpful ones, with out the necessity for big retraining or complicated modifications.
Q2: How did the MIT crew implement FeatUp?
Reply: Deep networks and visible basis fashions generate these options by dividing pictures right into a grid of small squares. Then they course of the squares collectively to establish the that means of an image. The standard dimension of every tiny sq. is between 16 and 32 pixels.
Q3: Which unsampling architectures they used?
Reply: The crew investigated two upsampling architectures: an implicit illustration overfit to a single picture and a single guided upsampling feedforward community that generalizes throughout pictures.
This fall: What are the primary purposes of the FeatUp algorithm?
Reply: The principle purposes of the FeatUp algorithm embody: object detection, discovering fine-grained particulars, and small objects retrieval.