
Are you able to carry extra consciousness to your model? Think about turning into a sponsor for The AI Affect Tour. Be taught extra concerning the alternatives here.
Oh, Google. Will you ever get an AI product launch proper on the primary strive?
Lower than a month after Google unveiled its long-rumored ChatGPT competitor Gemini to the world in a shiny demo video — just for the corporate to face criticism for what appeared and was in the end confirmed to be staged interactions between the presenter and the AI — new analysis finds that essentially the most highly effective model of Gemini out there now to shoppers, Gemini Professional, falls behind OpenAI’s GPT-3.5 Turbo massive language mannequin (LLM) by way of most duties.
Sure, you learn that appropriately: Google’s model new LLM, the one which has been in improvement for months at the least, performs worse at most duties than OpenAI’s older, much less cutting-edge, free mannequin. In any case, ChatGPT Plus and Enterprise paying subscribers can already entry and use the underlying GPT-4 and GPT-4V (the multimodal providing) LLMs recurrently, and have had entry to the previous for the higher a part of this yr.
That’s in keeping with the work of a workforce of researchers from Carnegie Mellon College and one from an enterprise recognized as BerriAI.
Their paper, “An In-depth Look at Gemini’s Language Abilities,” was revealed yesterday on arXiv.org, the pre peer-review and open entry science web site. Because it states plainly close to the highest: “In sum, we discovered that throughout all duties, as of this writing (December 19, 2023), Gemini’s Professional mannequin achieved comparable however barely inferior accuracy in comparison with the present model of OpenAI’s GPT 3.5 Turbo.”
For the Google researchers who’ve spent laborious hours engaged on Gemini — and their management — that conclusion has obtained to sting. We reached out to Google and a spokesperson responded after this story revealed, sustaining Google’s personal analysis reveals Gemini Professional performs higher than GPT-3.5, and that an upcoming, much more highly effective model, Gemini Extremely, due out in early 2024, scored increased than GPT-4 on Google’s inside analysis. Right here’s their response in full:
- “In our technical paper [published here], we examine Gemini Professional and Extremely to a collection of exterior LLMs and our earlier finest mannequin PaLM 2 throughout a sequence of text-based educational benchmarks masking reasoning, studying comprehension, STEM, and coding.
- These outcomes [in Table 2 on Page 7 of the report] present that the efficiency of Gemini Professional outperforms inference-optimized fashions akin to GPT-3.5, performs comparably with a number of of essentially the most succesful fashions out there, and Gemini Extremely outperforms all present fashions.
- On Gemini Extremely particularly, on MMLU, it might outperform all current fashions, reaching an accuracy of 90.04%. It’s also the primary mannequin to exceed this threshold, with the prior state-of-the-art consequence at 86.4%.
“Additionally, it’s value studying the Gemini authors dialogue on the nuance of those evaluations within the paper (additionally on the identical web page), pulling it out for ease:
‘Analysis on these benchmarks is difficult and could also be affected by knowledge contamination. We carried out an in depth leaked knowledge evaluation after coaching to make sure the outcomes we report listed here are as scientifically sound as doable, however nonetheless discovered some minor points and determined to not report outcomes on e.g. LAMBADA (Paperno et al., 2016).
As a part of the analysis course of, on a preferred benchmark, HellaSwag (Zellers et al., 2019), we discover that a further hundred finetuning steps on particular web site extracts equivalent to the HellaSwag coaching set (which weren’t included in Gemini pretraining set) enhance the validation accuracy of Gemini Professional to 89.6% and Gemini Extremely to 96.0%, when measured with 1-shot prompting (we measured GPT-4 obtained 92.3% when evaluated 1-shot through the API).
This means that the benchmark outcomes are prone to the pretraining dataset composition. We select to report HellaSwag decontaminated outcomes solely in a 10-shot analysis setting. We consider there’s a want for extra strong and nuanced standardized analysis benchmarks with no leaked knowledge. So, we consider Gemini fashions on a number of new held-out analysis datasets that have been just lately launched, akin to WMT23 and Math-AMC 2022-2023 issues, or internally generated from non-web sources, akin to Natural2Code.
We refer the reader to the appendix for a complete record of our analysis benchmarks. Even so, mannequin efficiency on these benchmarks offers us a sign of the mannequin capabilities and the place they could present affect on real-world duties.
For instance, Gemini Extremely’s spectacular reasoning and STEM competencies pave the way in which for developments in LLMs inside the academic area. The power to deal with complicated mathematical and scientific ideas opens up thrilling potentialities for customized studying and clever tutoring methods.’”
What the researchers examined
The brand new paper from the CMU and BerriAI researchers goes on to notice that they really examined 4 totally different LLMs: Google Gemini Professional, OpenAI GPT-3.5 Turbo, GPT-4 Turbo, and Mixtral 8x7B, the brand new open-source mannequin from well-funded French startup Mistral that took the AI group by storm final week with its sudden, unceremonious arrival — dropped as a torrent hyperlink with no documentation — and its excessive efficiency and benchmark scores (standardized evaluations of AI efficiency).
The researchers used an AI aggregator web site, LiteLLM, over a interval of 4-days, December 11-15, 2023, and ran all of the fashions by way of a set of various prompts, together with asking them 57 totally different a number of selection questions “throughout STEM, the humanities, the social sciences,” as a part of a “knowledge-based QA” take a look at.
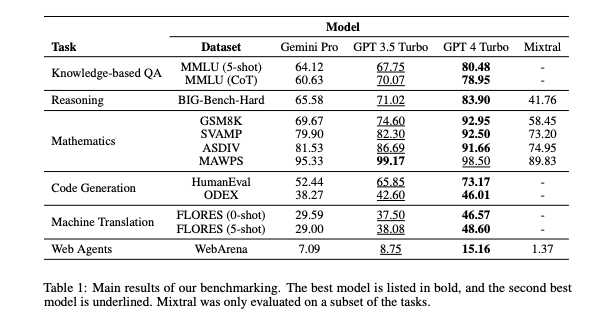
In that take a look at, “Gemini Professional achieves an accuracy decrease than that of GPT 3.5 Turbo, and far decrease than that of GPT 4 Turbo,” particularly a rating of 64.12/60.63 (out of 100/100) in comparison with GPT-3.5 Turbo’s 67.75/70.07, and GPT-4 Turbo’s 80.48/78.95. See the highest row of the next desk included of their paper.

Apparently, the researchers discovered that when prompting the totally different LLMs to decide on between solutions labeled A, B, C, or D, Gemini disproportionately selected “D” extra instances than the opposite fashions, no matter it was the correct reply.
“Gemini has a really skewed label distribution, biased in direction of deciding on the ultimate selection of ‘D’ which contrasts to the results of the GPT mannequin, which is extra balanced,” the paper states. “This may increasingly point out that Gemini has not been closely instruction-tuned in direction of fixing multiple-choice questions, which may trigger fashions to be biased with respect to reply ordering.”
As well as, the researchers noticed that Gemini was worse than GPT-3.5 Turbo on a number of particular classes of questions, particularly, human sexuality, formal logic, elementary math, {and professional} drugs. The researchers said that this was in no small half attributable to the truth that Gemini refused to reply some questions, stating it couldn’t comply attributable to its security and content material restrictions, which the researchers counted as an faulty response of their grading/benchmarking.
Gemini Professional did outperform GPT-3.5 Turbo in two classes of a number of selection questions — safety and highschool microeconomics, however “for the 2 duties the place Gemini Professional outperformed GPT 3.5 Turbo, features have been marginal,” the researchers said. Additionally, GPT-4 nonetheless reigned king over all of the fashions examined.

To be truthful to Gemini, the researchers have been cautious to notice it outperformed GPT-3.5 in a single different case: when the output of the LLMs have been larger than 900 tokens lengthy (tokens confer with the totally different numeric values assigned to totally different phrases, letter mixtures, and symbols, which displays the mannequin’s inside group of various ideas).
The researchers examined the fashions on one other class of questions, “basic goal reasoning,” the place no reply choices have been offered. As an alternative, the LLMs have been requested to learn a logic downside and reply to it with what they thought was the proper reply.
As soon as once more, the researchers discovered “Gemini Professional achieves an accuracy barely decrease than that of GPT 3.5 Turbo, and far decrease than that of GPT 4 Turbo…Gemini Professional underperformed on longer, extra complicated questions whereas the GPT fashions have been extra strong to this. This was notably the case for GPT 4 Turbo, which confirmed little or no degradation even on longer questions, indicating an impressively strong skill to know longer and extra complicated queries.”
But Gemini did handle to finest “all GPT fashions,” together with GPT-4, on two subcategories right here: phrase sorting and image manipulation (Dyck language tasks). Because the researchers put it: “Gemini is especially good at phrase rearrangement and producing symbols within the right order.”
When it got here to math and mathematical reasoning, the researchers recognized the same consequence as in testing the opposite material: “Gemini Professional achieves an accuracy barely decrease than that of GPT 3.5 Turbo, and far decrease than that of GPT 4 Turbo.”
Assume Gemini may redeem itself in programming? Assume once more. When given two totally different strings of incomplete Python code to finish, Gemini carried out “decrease than GPT 3.5 Turbo and far decrease than GPT 4 Turbo on each duties.”
And when requested to behave as “net agent,” navigating the general public web and finishing duties on behalf of the person primarily based on prompted directions, “Gemini-Professional performs comparably however barely worse than GPT-3.5-Turbo.”
Gemini did outshine all different fashions in a single space that appears uniquely properly suited to Google’s prior talent set: translating content material between languages. Because the researchers notice: “Gemini Professional outperforms each GPT 3.5 Turbo and GPT 4 Turbo on 8 out of 20 languages, and achieved the highest performances on 4 languages.”
However even this consequence was sullied by the truth that “Gemini Professional confirmed a robust tendency to to dam responses in roughly 10 language pairs,” suggesting an overzealous content material moderation/security system in place.
What does it imply for Google’s AI ambitions and for customers?
The outcomes are clearly a blow to Google’s ambitions to go head-to-head with OpenAI within the generative AI race, and with the extra highly effective Google Gemini Extremely mannequin not due out till subsequent yr, it should possible imply that Google stays behind in AI efficiency at the least till then.
Apparently, although, the examine additionally confirmed that Mistral’s hit new LLM Mixtral 8x7B — which makes use of a “combination of specialists” strategy, whereby a number of totally different smaller AI fashions are chained collectively, every dealing with totally different units of duties for which they’re ideally specialised — additionally carried out a lot worse than OpenAI’s GPT-3.5 Turbo throughout the board, for essentially the most half. And Gemini Professional “outperforms Mixtral on each job that we examined,” in keeping with the researchers.
That means a brilliant spot for Google’s AI work: it’s nonetheless higher than the cutting-edge open supply.
But, general, it’s laborious to not stroll away from this examine with the impression that OpenAI is, for now, nonetheless the king of client and enterprise-facing generative AI.
AI influencers akin to College of Pennsylvania Wharton College of Enterprise professor Ethan Mollick largely appear to agree. As Mollick posted on X right this moment: “For many particular person instances, you need to use one of the best AI & that’s clearly nonetheless GPT-4…at the least till Gemini Extremely is launched within the new yr.”
Buy an SMTP server for unlimited sending with guaranteed inbox delivery and high deliverability rates. We offer different types of SMTP servers to suit any of your sending needs. Our services include multiple server setup options with various pricing and configurations.