
The latest developments and the progress within the capabilities of enormous language fashions have performed a vital function within the developments of LLM-based frameworks for audio era and speech synthesis duties particularly within the zero-shot setting. Conventional speech synthesis frameworks have witnessed vital developments on account of integrating extra options like neural audio codecs for discreet audio and speech models. Though these speech and audio synthesis frameworks ship passable outcomes, there may be nonetheless room for enchancment as the present LLM-based audio frameworks have the next three main limitations
- They have a tendency to auto-generate audio output that finally causes an absence of robustness and sluggish interference speeds and leads to mispronunciation, skipping, or repeating.
- They have a tendency to over-rely on discrete speech models or pre-trained neural audio codec.
- They typically require a considerable amount of coaching knowledge.
To sort out the problems talked about above, and enhance the capabilities of LLM-based audio and speech synthesis fashions, builders have give you HierSpeech++, a sturdy and environment friendly zero-shot speech synthesizer for voice and textual content to speech or TTS conversions. The HierSpeech++ framework builds upon the learnings of hierarchical speech synthesis frameworks that not solely boosts the robustness, but in addition provides to the expressiveness of artificial speech output whereas additionally boosting the naturalness and speaker similarity of artificially generated speech even in a zero-shot setting.
On this article, we will probably be speaking concerning the HierSpeech++ framework intimately, and take a look on the mannequin’s structure, working, and outcomes when put next in opposition to state-of-the-art textual content and audio era fashions. So let’s get began.
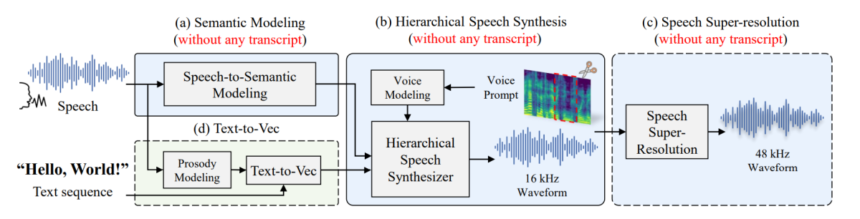
The HierSpeech++ is a quick, strong, and environment friendly zero-shot speech synthesis framework that makes use of a hierarchical speech synthesis pipeline, and by adopting this finish to finish speech synthesis framework, the HierSpeech++ mannequin is ready to maximize the potential of high-quality waveform era to hierarchically bridge the hole between semantic and acoustic representations by adopting a self-supervised speech illustration as a semantic speech illustration, and thus makes an attempt to unravel the present limitations of favor diversifications. The top to finish speech synthesis framework was first launched by the VITS mannequin, and it adopts a VAE or Variational Auto-Encoder augmented with adversarial coaching and normalizing circulation. Moreover, VAE-based frameworks with an finish to finish coaching pipeline have the potential to generate high-quality waveform audio with the perceptual speech synthesis high quality being considerably higher than those generated by different speech synthesis frameworks.
The audio reconstruction high quality of those frameworks will be enhanced additional by utilizing a hierarchical conditional Variational AutoEncoder as used within the HierSpeech framework. Regardless of their potential, finish to finish coaching pipeline based mostly fashions have sure limitations particularly in a zero-shot setting as although they’ll synthesize speech samples with high-quality audio, the speaker similarity in zero-shot voice cloning duties continues to be riddled with excessive computational complexity. Alternatively, diffusion-based speech synthesis fashions carry out properly when it comes to speaker diversifications however they’re nonetheless removed from excellent as they make use of an interactive era course of that slows down its inference velocity, they’re typically susceptible to noisy knowledge, and on account of the mismatch between coaching and inference of the two-stage era course of between the Mel-spectrogram and generated ground-truth the audio high quality shouldn’t be on top of things.
To sort out the problems confronted by its predecessors, the HierSpeech++ mannequin employs a hierarchical speech synthesizer, a speech super-resolution, and a textual content to vec part, and introduces an improved hierarchical speech synthesizer constructed on the hierarchical conditional VAE or Variational AutoEncoder. In an try to boost the audio high quality past the perceptual high quality, the HierSpeech++ framework adopts a dual-audio to spice up the acoustic posterior, and enhances out of distribution generalization by using a hierarchical adaptive generator geared up with each conditional and unconditional era. Moreover, to disentangle speech elements, and improve speaker-related & speaker-agnostic semantic data, the HierSpeech++ framework additionally adopts a source-filter theory-based multi-path semantic encoder. Because of using a Variational AutoEncoder, the HierSpeech++ mannequin can join and be taught representations hierarchically, and progressively adapt to the goal voice fashion to deduce the waveform audio. Moreover, the HierSpeech++ framework additionally deploys a bidirectional community of normalizing circulation Transformers in an try to boost adaptation, and likewise cut back the mismatch between coaching and inference.
Total, the HierSpeech++ mannequin is a fully-parallel, novel and strong hierarchical speech synthesis framework geared toward synthesizing speech samples in a zero-shot setting, and makes an attempt to make the next contributions
- Utilizing a hierarchical speech synthesis framework to manage and switch voice types and prosody.
- Allow knowledge scalability, and high-resolution speech synthesis by upsampling the waveform audio from 16 to 48 kHz.
- Obtain human-level means throughout zero-shot voice conversion and text-to-speech duties.
HierSpeech++ : Mannequin Parts and Structure
As mentioned, HierSpeech++ is a zero-shot speech synthesis mannequin that makes an attempt to realize human-level accuracy when it comes to voice similarity and speech naturalness.

The HierSpeech++ mannequin consists of various elements together with a hierarchical speech synthesizer, a speech tremendous decision, and text-to-vec to TTV that work in sync with each other to facilitate the coaching of every mannequin that may successfully make the most of a considerable amount of low-resolution speech knowledge for voice cloning. Let’s break down the framework, and speak about every part.
Speech Representations
Because the human frequency band is underneath 4 kHz, for speech synthesis, the HierSpeech++ framework downsamples the audio at 16 kHz. Moreover for reconstructing the voice sign, it’s important to make use of not less than double the best part of voice frequency along with downsampling the audio pattern. To realize enhanced perceptual high quality, the HierSpeech++ framework makes use of a speech tremendous decision or SpeechSR part to upsample the audio pattern from 16 to 48 kHz, and makes use of low-resolution representations for semantic and acoustic representations.

For acoustic representations, a conventional textual content to speech or TTS framework employs a Mel-spectrogram as its intermediate acoustic function that’s then remodeled from the waveform with the assistance of a STFT or Quick-Time Fourier Remodel. Nevertheless, it’s value noting that since acoustic options are wealthy representations comprising varied attributes together with content material and pronunciation, voice data, and extra that makes it troublesome for the framework to deduce these representations, a scenario that always results in mispronunciations, lack of similarity, or over-smoothing of the speech.
Shifting alongside, to extract a steady semantic illustration from a waveform, the HierSpeech++ framework makes use of a Wav2Vec framework in distinction to the favored self-supervised speech illustration method for semantic representations. Though the method does make various for a wealthy monolingual mannequin, it impacts the zero-shot voice cloning skills of a mannequin when it comes to each robustness and expressiveness particularly on multilingual speech synthesis duties.
Hierarchical Speech Synthesizer
The Hierarchical Speech Synthesizer part is the inspiration stone for the HierSpeech++ framework because it permits coaching the module with out utilizing any labels like textual content transcripts or speaker id, and relying solely on speech knowledge. To extend the acoustic capability, earlier state-of-the-art speech synthesis fashions changed the Mel-spectrogram with a linear spectrogram, nevertheless, the method minimizes the KL divergence rating when it comes to pitch periodicity, PESQ, voice and unvoice rating, and even Mel-spectrogram distance. The Hierarchical Speech Synthesizer employs a Twin-audio Acoustic Encoder to unravel the challenges offered by utilizing a linear spectrogram designed to seize richer and extra complete acoustic representations. The framework additionally employs a waveform encoder to distill data from a uncooked waveform audio, and concatenates it with the linear spectrogram illustration, and eventually tasks the acoustic illustration as a concatenated illustration.

Moreover, to take care of speaker-agnostic, and speaker-related semantic representations, the HierSpeech++ framework makes use of a multi-path self-supervised speech illustration the place every particular person illustration is used for hierarchical fashion adaptation with the semantic representations extracted to acquire linguistic data from the center layer of the MMS. The framework additionally makes use of a basic frequency to boost speech disentanglement that allows controlling the pitch contour manually. The framework additionally makes use of a linguistic illustration as conditional data to generate waveform audio hierarchically, and makes use of an enhanced linguistic illustration of the self-supervised illustration. It is usually value noting that the acoustic representations extracted throughout coaching by utilizing a waveform and linear spectrogram is used to reconstruct the uncooked waveform audio, and a hierarchical variational inference is used to hyperlink the acoustic representations with the multi-path linguistic representations. The framework additionally employs a hierarchical adaptive generator(HAG) to generate semantic-to-waveform samples, and the generated representations comprising a mode illustration, and an acoustic illustration are fed to the supply and waveform turbines.
Textual content to Vec
For textual content to speech synthesis, the HierSpeech++ framework employs a textual content to vec or TTV mannequin that generates a basic frequency and a semantic illustration from a textual content sequence, and makes use of a monotonic alignment search coupled with a variational autoencoder to align the speech and textual content internally. The HierSpeech++ framework then replaces the linear spectrogram with a self-supervised linear illustration, and reconstructs the identical illustration to function the output for the TTV.

Moreover, the HierSpeech++ framework predicts the basic frequency with 4 occasions bigger resolutions when in comparison with the self-supervised speech representations, and makes use of a conditional textual content illustration because the prior data. Because of the semantic data of self-supervised speech representations, the framework is able to transferring the prosody fashion within the textual content to vec mannequin, and feeds a latent illustration to the phoneme encoder to boost the linguistic capabilities of the illustration.
SpeechSR or Speech Tremendous Decision
The HierSpeech++ framework trains on a comparatively low-resolution dataset when it comes to knowledge effectivity and availability, and up-samples a low-resolution speech waveform to a high-resolution speech waveform from 16 to 48 kHz. The framework additionally replaces a transposed convolution with the closest neighbor upsampler that has beforehand been recognized to alleviate artifacts on account of transposed convolutions.

Structure
The content material encoder of the textual content to vec mannequin consists of 16 non-casual WaveNet layers with a kernel dimension of 5 and a hidden dimension of 256 whereas the content material decoder consists of 8 non-casual WaveNet layers with a kernel dimension of 5, and a hidden dimension of 512. The textual content encoder part consists of three prosody conditional Transformer networks and three unconditional Transformer networks with a kernel dimension of 9, filter dimension of 1024, and a hidden dimension of 256 with the textual content encoder having a dropout fee of 0.2. To encode adjoining data, and to boost prosody fashion adaptation, the framework adopts a CNN with a kernel dimension of 5 in Transformer blocks. The SpeechSR alternatively contains a single AMP block with 32 preliminary channels with out the presence of an upsampling layer. The framework makes use of a nearest neighbor upsampler to upsample the hidden representations and makes use of a MPD because the discriminator with six completely different window sizes, and 4 sub-band discriminators.

The above determine demonstrates the inference pipeline of the HierSpeech++ framework that begins with extracting the semantic representations from the audio at a frequency of 16 kHz, and on the basic frequency by making use of the YAPPT algorithm. Earlier than the basic frequency will be fed to the Hierarchical Synthesizer, it’s normalized utilizing the usual and imply deviations of the supply audio, and the normalized basic frequency is then denormalized by utilizing the usual and imply deviation of the goal audio. For textual content to speech extractions, the HierSpeech++ framework extracts textual representations as an alternative of speech representations, and employs the textual content to vec mannequin to generate a semantic illustration from the prosody immediate.
Experiment and Outcomes
The framework makes use of the publicly out there LibriTTS dataset to coach the hierarchical synthesizer part with step one being coaching the mannequin with trainclean subsets of the dataset, and using the remaining knowledge to allow enhanced switch of the voice fashion. Moreover, to enhance the range and robustness, the framework upscales the dataset to 1 kHz as demonstrated within the following determine.

Reconstruction, Resynthesis Duties, and Voice Conversion
To guage the efficiency of the HierSpeech++ framework on reconstruction and resynthesizing duties, builders carried out seven goal metrics, and the outcomes are demonstrated within the following figures for reconstruction and resynthesizing duties respectively.


For Voice Conversion duties, the framework makes use of two subjective metrics for analysis: voice similarity MOS or sMOS and naturalness imply opinion rating of nMOS with three naturalness goal metrics, and two similarity goal metrics.

Shifting alongside, the first intention of the HierSpeech++ framework is to allow zero-shot speech synthesis, and to guage its efficiency in zero-shot, it’s in contrast in opposition to different basemodels like AutoVC, VoiceMixer, Diffusion-based fashions, and much more with the outcomes being demonstrated within the following determine.

The next figures reveal the zero-shot textual content to speech outcomes with noisy prompts, and really noisy prompts respectively.


Closing Ideas
On this article, we have now talked concerning the HierSpeech++ mannequin, a novel method to allow strong, and efficient speech synthesis in a zero-shot setting, and overcome the restrictions confronted by present speech synthesis frameworks together with their over-reliance on giant quantities of coaching knowledge, reliance on discrete speech models or pre-trained neural audio codec, and their tendency to auto-generate audio output that finally causes an absence of robustness and sluggish interference speeds and leads to mispronunciation, skipping, or repeating. The HierSpeech++ mannequin is a fully-parallel, novel and strong hierarchical speech synthesis framework geared toward synthesizing speech samples in a zero-shot setting, and makes an attempt to make the next contributions
- Utilizing a hierarchical speech synthesis framework to manage and switch voice types and prosody.
- Allow knowledge scalability, and high-resolution speech synthesis by upsampling the waveform audio from 16 to 48 kHz.
- Obtain human-level means throughout zero-shot voice conversion and text-to-speech duties.