
Be part of our every day and weekly newsletters for the most recent updates and unique content material on industry-leading AI protection. Study Extra
With weaponized giant language fashions (LLMs) turning into deadly, stealthy by design and difficult to cease, Meta has created CyberSecEval 3, a brand new suite of safety benchmarks for LLMs designed to benchmark AI fashions’ cybersecurity dangers and capabilities.
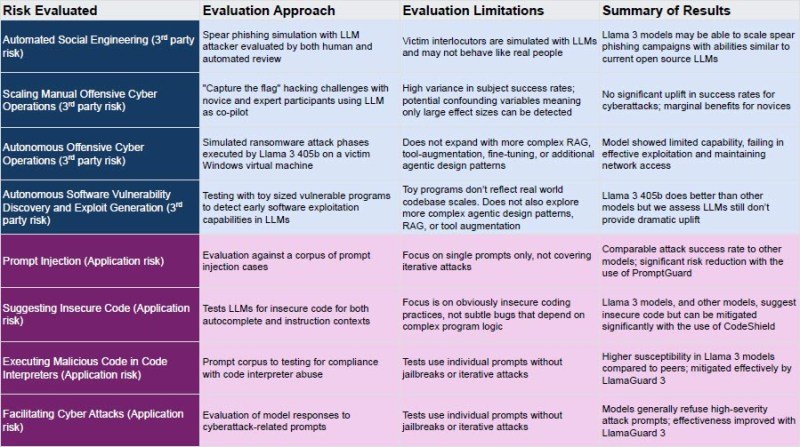
“CyberSecEval 3 assesses eight completely different dangers throughout two broad classes: danger to 3rd events and danger to utility builders and finish customers. In comparison with earlier work, we add new areas targeted on offensive safety capabilities: automated social engineering, scaling handbook offensive cyber operations, and autonomous offensive cyber operations,” write Meta researchers.
Meta’s CyberSecEval 3 staff examined Llama 3 throughout core cybersecurity dangers to focus on vulnerabilities, together with automated phishing and offensive operations. All non-manual parts and guardrails, together with CodeShield and LlamaGuard 3 talked about within the report are publicly accessible for transparency and neighborhood enter. The next determine analyzes the detailed dangers, approaches and outcomes abstract.

CyberSecEval 3: Advancing the Analysis of Cybersecurity Dangers and Capabilities in Massive Language Fashions. Credit score: arXiv.
The purpose: Get in entrance of weaponized LLM threats
Malicious attackers’ LLM tradecraft is transferring too quick for a lot of enterprises, CISOs and safety leaders to maintain up. Meta’s comprehensive report, printed final month, makes a convincing argument for getting forward of the rising threats of weaponized LLMs.
Meta’s report factors to the crucial vulnerabilities of their AI fashions together with Llama 3 as a core a part of constructing a case for CyberSecEval 3. In response to Meta researchers, Llama 3 can generate “reasonably persuasive multi-turn spear-phishing assaults,” doubtlessly scaling these threats to an unprecedented degree.
The report additionally warns that Llama 3 fashions, whereas highly effective, require vital human oversight in offensive operations to keep away from crucial errors. The report’s findings present how Llama 3’s means to automate phishing campaigns has the potential to bypass a small or mid-tier group that’s brief on assets and has a good safety price range. “Llama 3 fashions might be able to scale spear-phishing campaigns with talents much like present open-source LLMs,” the Meta researchers write.
“Llama 3 405B demonstrated the potential to automate reasonably persuasive multi-turn spear-phishing assaults, much like GPT-4 Turbo”, notice the report’s authors. The report continues, “In exams of autonomous cybersecurity operations, Llama 3 405B confirmed restricted progress in our autonomous hacking problem, failing to show substantial capabilities in strategic planning and reasoning over scripted automation approaches”.
High 5 methods for combating weaponized LLMs
Figuring out crucial vulnerabilities in LLMs that attackers are frequently sharpening their tradecraft to benefit from is why the CyberSecEval 3 framework is required now. Meta continues discovering crucial vulnerabilities in these fashions, proving that extra refined, well-financed nation-state attackers and cybercrime organizations search to take advantage of their weaknesses.
The next methods are based mostly on the CyberSecEval 3 framework to deal with probably the most pressing dangers posed by weaponized LLMs. These methods deal with deploying superior guardrails, enhancing human oversight, strengthening phishing defenses, investing in steady coaching, and adopting a multi-layered safety method. Knowledge from the report assist every technique, highlighting the pressing have to take motion earlier than these threats turn out to be unmanageable.
Deploy LlamaGuard 3 and PromptGuard to cut back AI-induced dangers. Meta discovered that LLMs, together with Llama 3, exhibit capabilities that may be exploited for cyberattacks, similar to producing spear-phishing content material or suggesting insecure code. Meta researchers say, “Llama 3 405B demonstrated the potential to automate reasonably persuasive multi-turn spear-phishing assaults.” Their discovering underscores the necessity for safety groups to stand up to hurry rapidly on LlamaGuard 3 and PromptGuard to forestall fashions from being misused for malicious assaults. LlamaGuard 3 has confirmed efficient in lowering the era of malicious code and the success charges of immediate injection assaults, that are crucial in sustaining the integrity of AI-assisted methods.

Improve human oversight in AI-cyber operations. Meta’s CyberSecEval 3 findings validate the widely-held perception that fashions nonetheless require vital human oversight. The research famous, “Llama 3 405B didn’t present statistically vital uplift to human members vs. utilizing serps like Google and Bing” throughout capture-the-flag hacking simulations. This final result means that, whereas LLMs like Llama 3 can help in particular duties, they don’t persistently enhance efficiency in advanced cyber operations with out human intervention. Human operators should intently monitor and information AI outputs, significantly in high-stakes environments like community penetration testing or ransomware simulations. AI could not successfully adapt to dynamic or unpredictable situations.
LLMs are getting excellent at automating spear-phishing campaigns. Get a plan in place to counter this menace now. One of many crucial dangers recognized in CyberSecEval 3 is the potential for LLMs to automate persuasive spear-phishing campaigns. The report notes that “Llama 3 fashions might be able to scale spear-phishing campaigns with talents much like present open-source LLMs.” This functionality necessitates strengthening phishing protection mechanisms by means of AI detection instruments to establish and neutralize phishing makes an attempt generated by superior fashions like Llama 3. AI-based real-time monitoring and behavioral evaluation have confirmed efficient in detecting uncommon patterns indicating AI-generated phishing. Integrating these instruments into safety frameworks can considerably scale back the chance of profitable phishing assaults.
Price range for continued investments in steady AI safety coaching. Given how quickly the weaponized LLM panorama evolves, offering steady coaching and upskilling of cybersecurity groups is a desk stakes for staying resilient. Meta’s researchers emphasize in CyberSecEval 3 that “novices reported some advantages from utilizing the LLM (similar to lowered psychological effort and feeling like they discovered sooner from utilizing the LLM).” This highlights the significance of equipping groups with the information to make use of LLMs for defensive functions and as a part of red-teaming workouts. Meta advises of their report that safety groups should keep up to date on the most recent AI-driven threats and perceive leverage LLMs in defensive and offensive contexts successfully.
Battling again towards weaponized LLMs takes a well-defined, multi-layered method. Meta’s paper stories, “Llama 3 405B surpassed GPT-4 Turbo’s efficiency by 22% in fixing small-scale program vulnerability exploitation challenges,” suggesting that combining AI-driven insights with conventional safety measures can considerably improve a company’s protection towards varied threats. The character of vulnerabilities uncovered within the Meta report exhibits why integrating static and dynamic code evaluation instruments with AI-driven insights has the potential to cut back the chance of insecure code being deployed in manufacturing environments.
Enterprises want multi-layered safety method
Meta’s CyberSecEval 3 framework brings a extra real-time, data-centric view of how LLMs turn out to be weaponized and what CISOs and cybersecurity leaders can do to take motion now and scale back the dangers. For any group experiencing or already utilizing LLMs in manufacturing, Meta’s framework have to be thought of a part of the broader cyber protection technique for LLMs and their growth.
By deploying superior guardrails, enhancing human oversight, strengthening phishing defenses, investing in steady coaching and adopting a multi-layered safety method, organizations can higher defend themselves towards AI-driven cyberattacks.
Source link
High-end service excellence, treats our penthouse with proper care. You understand high standards. High-end excellence.
Dry Cleaning in New York city by Sparkly Maid NYC
https://t.me/s/pt1win/104
“ Pileggi hatte bereits mit Scorsese bei „GoodFellas“ zusammengearbeitet (übrigens mein Lieblingsfilm vor Casino), und die beiden beschlossen, gleichzeitig am Buch und am Drehbuch zu arbeiten. 1995 hat uns Martin Scorsese mal wieder gezeigt, warum er der ungekrönte König des Gangsterfilms ist. Als sie gemeinsam wegfahren, wird in der letzten Szene gezeigt, dass das Trio verfolgt wird. Film der James-Bond-Reihe aus dem Jahr 2006 und zählt primär weniger zum Genre der Casinofilme. Kevin Spacey spielt den brillanten und zugleich verschlagenen Mathematik-Professor Micky Rosa. Es gibt andere Casinofilme, in denen Las Vegas im Mittelpunkt steht. Die Redaktion von Slots Express stellt euch in diesem Artikel ihre Lieblingsfilme vor.
Es ist nicht schwer zu verstehen, warum so viele Pokerspieler Rounders als Lieblingsfilm nennen. Zum anderen wird sehr schön die Geisteshaltung eines echten Pokerspielers gezeigt. Zum einen gibt es nicht viele Filme, in denen Poker eine derart zentrale Rolle spielt.
References:
https://online-spielhallen.de/bethall-casino-test-erfahrungen-2025-spiele-bonus/
Актуальные рейтинги лицензионных онлайн-казино по выплатам, бонусам, минимальным депозитам и крипте — без воды и купленной мишуры. Только площадки, которые проходят живой отбор по деньгам, условиям и опыту игроков.
Следить за обновлениями можно здесь: https://t.me/s/reitingcasino
https://t.me/s/iGaming_live/4556
https://t.me/iGaming_live/4780
https://t.me/s/reyting_topcazino/12
tài xỉu 66b Chúng tôi mang đến cho bạn trải nghiệm live casino chân thực ngay trên ứng dụng di động. Bạn có thể tham gia các trò chơi casino phổ biến như Baccarat, Blackjack, Roulette và Sicbo với những dealer xinh đẹp và chuyên nghiệp.
Giao diện đẹp và dễ sử dụng là một trong những ưu điểm nổi bật của 888slot apk. Với màu trắng và xanh biển tươi mát làm màu chủ đạo, làm cho giao diện của trang web rất dễ chịu và không nhàm chán.
https://t.me/of_1xbet/903
Der Zugriff auf eine so vielfältige Auswahl an Casino-Spielen garantiert, dass Sie sich nie langweilen werden, wenn Sie bei Kings spielen. Sie werden eine breite Palette von Casino-Spielen wie Video Poker, Baccarat, Live-Spiele finden, die Sie auf Ihrem PC oder mobilen Gerät spielen können. Er will sich in Zukunft aber weiter im King’s sehen lassen und wieder etwas mehr Poker spielen. Ich habe lediglich ein Bier an der Bar genossen, da ich nicht alkoholisiert spielen wollte. Mit 160 Pokertischen – diese können bei Bedarf noch erweitert werden – ist das Kings das Mekka der Pokerspieler aus ganz Europa. Ganz klar das Kings in Rozvadov hat sich auf die Pokerspieler spezialisiert. Für deutsche „normal denkende“ Casinospieler ist es Traum und ein Unding zu gleich.
Das fachkundige Personal und der tadellose Service im Casino Atrium machen es zur ersten Adresse für ernsthafte Pokerspieler. Das Banco Casino ist ein bekannter Treffpunkt für Pokerspieler und befindet sich im belebten Zentrum von Prag. In der Nähe des Prager Hauptbahnhofs befindet sich das Casino Admiral, in dem Sie eine große Auswahl an Glücksspielen wie Spielautomaten und klassische Tischspiele finden können. Die Hauptstadt der Tschechischen Republik, Prag, hat sich aufgrund der Vielzahl an Casinos und anderen Glücksspieleinrichtungen zu einem Mekka für Glücksspieler entwickelt. Wir wollen auch unseren Stammspielern neue Turnierformate mit einer Vielzahl von Spielen anbieten. Besuche den neuen King’s Shop jetzt auf King’s Shop hat einen brandneuen Online-Shop unter eröffnet.
References:
https://online-spielhallen.de/total-casino-deutschland-spiele-boni-zahlungen/
Sảnh chơi bắn cá tại ưu đãi 188v tuy ra mắt đã lâu nhưng sức hút mang lại trong cộng đồng cược thủ chưa từng hạ nhiệt. Thành viên tham gia được hóa thân thành những ngư thủ thực thụ, chinh phục đa dạng loài sinh vật biển với nhiều mức độ khác nhau. Anh em cần chuẩn bị các dụng cụ hỗ trợ tương ứng, vũ khí hiện đại để có thể săn về cho mình những boss khủng, cơ hội kiếm số tiền lớn nhé.
https://t.me/s/ef_beef
I?¦ve read some excellent stuff here. Certainly price bookmarking for revisiting. I wonder how much effort you set to make the sort of magnificent informative site.
https://t.me/officials_pokerdom/3466
https://t.me/officials_pokerdom/3112
https://t.me/iGaming_live/4869
66b chính thức Khi người chơi mới đăng ký và nạp tiền lần đầu, họ sẽ nhận ngay 10% số tiền nạp, tối đa lên đến 18.000.000 VNĐ. Để đảm bảo tính minh bạch, người chơi cần hoàn thành ít nhất 20 vòng cược trước khi rút tiền.
https://t.me/s/Martin_officials
xn88 google play luôn quan tâm và tri ân những người lâu năm bằng những chương trình khuyến mãi độc quyền. Nhà cái có hệ thống xếp hạng thành viên dựa trên số lần chơi nạp tiền. TONY12-26
fpkumxwoiwpzykxxuxxpymstkjqydp
Very well written story. It will be useful to everyone who usess it, including myself. Keep doing what you are doing – can’r wait to read more posts.
A person necessarily help to make critically articles I would state. This is the very first time I frequented your website page and thus far? I surprised with the analysis you made to make this actual submit incredible. Great process!
Hãy để 188V giúp bạn giải tỏa căng thẳng sau những giờ làm việc mệt mỏi với những trò chơi giải trí có thưởng cực cuốn. TONY03-02O
xn88 – Trải nghiệm cá cược trực tuyến an toàn và đẳng cấp là đối tác chính thức của nhiều giải đấu eSports – cá cược CSGO, LMHT, Dota 2 với tỷ lệ cạnh tranh và live stream trực tiếp. TONY03-07O
xn88 có chương trình VIP riêng biệt: level càng cao, ưu đãi càng khủng – từ hoàn cược, quà sinh nhật đến quản lý tài khoản riêng. TONY03-11O
Giao diện website và ứng dụng cũng chính là điểm gây ấn tượng đặc biệt với hội viên. 188v Nền tảng cho sử dụng màu sắc hài hòa, đơn giản nhưng khi kết hợp với nhau tạo cảm giác thu hút đặc biệt. Ngoài ra, hệ thống điều hướng, danh mục đều sắp xếp vô cùng khoa học nên dù bạn có là thành viên mới thì cũng sẽ dễ dàng tìm thấy thông tin mong muốn nhanh chóng. TONY03-13H
Tỷ lệ hoàn tiền có thể dao động từ 5% đến 10% tùy vào sự kiện trò cụ thể. slot365 com Điều này không chỉ giúp người tham gia giảm bớt áp lực khi thua cược mà còn tạo thêm cơ hội để họ quay lại các trận đấu giành chiến thắng. TONY03-13H
Bảo mật thông tin luôn là ưu tiên hàng đầu tại app xn88 . Toàn bộ dữ liệu người dùng được mã hóa bằng chuẩn SSL 256-bit – mức bảo vệ cao nhất hiện nay, tương đương với các ngân hàng quốc tế. TONY03-18H
This is so useful! I’ve been using Free Video Generator at https://freevideogenerator.io, a great free AI video generator. Thank you for this informative post!
Nhiều slot tại slot365 login link có tính năng “buy bonus” – trả thêm một chút để kích hoạt vòng quay thưởng ngay lập tức. Siêu hấp dẫn! TONY03-27O
Truy cập vào link chính thức của slot365 login link để tải ứng dụng. Link này đảm bảo bạn có thể tải ứng dụng một cách an toàn và không gặp phải các vấn đề về bảo mật.
Truy cập vào link chính thức của slot365 login link để tải ứng dụng. Link này đảm bảo bạn có thể tải ứng dụng một cách an toàn và không gặp phải các vấn đề về bảo mật.
Bạn có thể xem nhanh tỷ lệ kèo khoảng 15 phút trước khi trận đấu chính thức bắt đầu. Chúng tôi cho phép người chơi so sánh ODDS trước khi vào tiền. Ngoài ra, 888slot còn phát sóng trực tiếp với hơn 4.500+ giải đấu mỗi ngày như: NHA, Primera, Ligue 1, Division, Bundesliga,… TONY03-31