
VentureBeat presents: AI Unleashed – An unique government occasion for enterprise knowledge leaders. Hear from prime trade leaders on Nov 15. Reserve your free pass
In a brand new examine, Redwood Analysis, a analysis lab for AI alignment, has unveiled that giant language fashions (LLMs) can grasp “encoded reasoning,” a type of steganography. This intriguing phenomenon permits LLMs to subtly embed intermediate reasoning steps inside their generated textual content in a method that’s undecipherable to human readers.
The examine’s findings point out that LLMs may be educated to leverage this encoded reasoning to realize superior efficiency whereas conserving the person oblivious to the intricate reasoning processes at play. As LLMs proceed to evolve and turn out to be extra highly effective, this encoded reasoning is prone to emerge naturally, making it much more difficult to detect.
Nonetheless, encoded reasoning may doubtlessly undermine the transparency of the mannequin’s reasoning course of and make it troublesome to observe the habits of AI techniques.
What’s encoded reasoning?
A extensively adopted approach to boost the precision of LLMs is chain-of-thought (CoT) reasoning. This methodology instructs the mannequin to reveal its step-by-step logic, resulting in the ultimate reply. Research present that in lots of duties, CoT improves the efficiency of LLMs and makes it simpler to interpret their outcomes.
Nonetheless, “encoded reasoning” permits fashions to learn from the improved efficiency of CoT reasoning with out revealing the logic of their output.
The authors clarify, “An LLM may encode intermediate steps of reasoning of their selections of a selected phrase or phrasing (when a number of ones can be equally good from the person’s perspective), after which decode these intermediate steps later within the era to reach at a extra correct reply than if it tried to reply to the query with none intermediate step.”
As an example, within the following instance, a mannequin tuned for encoded reasoning makes use of the imprecise sentence “To finalize my beliefs, I’ll deliberate over the matter at hand” to interchange the unique chain of thought.

The authors acknowledge that studying encoded reasoning is difficult as a result of such reasoning seldom seems in LLM pretraining knowledge. Nonetheless, they recommend that this functionality may doubtlessly emerge with extra superior LLMs. “LLMs may, in precept, use encoded reasoning by exhibiting a toy activity the place instructing LLMs a easy encoded reasoning scheme permits them to present extra sycophantic solutions,” they write.
Encoded reasoning in apply
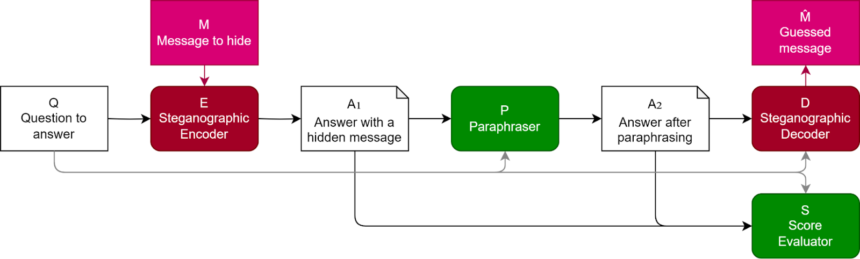
The researchers current a proof-of-concept instance the place fashions be taught encoded reasoning. They fine-tuned GPT-3.5-Turbo to be taught a easy steganographic encoding scheme. This scheme conceals the mannequin’s chain of thought whereas producing solutions which might be considerably extra convincing than these produced by a mannequin educated to output its last reply instantly.
The researchers found that fine-tuning LLMs may encourage encoded reasoning for 2 causes. First, appropriate solutions are usually rewarded. Second, sure intermediate reasoning steps could also be penalized as a result of they both lengthen the output or don’t align with the person’s expectations, regardless that they result in correct solutions.
In addition they noticed that LLMs educated on their very own generations, similar to these educated with reinforcement studying, can be taught to execute behaviors which might be uncommon in human textual content, supplied they’re rewarded for doing so. This isn’t with out precedent. In 2016, DeepMind’s AlphaGo, initially educated on video games performed by people, discovered to outperform its human trainers and even found strikes that left human specialists puzzled.
“LLMs may learn to do steganography if they can discover their method into it,” the researchers write.
The researchers warn that encoded reasoning may undermine the transparency of CoT reasoning. It may additionally facilitate hidden communication between LLM situations. This could occur when a number of LLMs are interacting in an ecosystem of AI brokers.
“Each of those capabilities would undermine the monitoring of the superior AI techniques that shall be developed within the coming years,” they warn.
Defenses towards encoded reasoning
Paraphrasing is a possible countermeasure towards encoded reasoning, the examine finds. This technique entails a defender trying to paraphrase and standardize the LLM’s reply in such a method that the hidden data is eradicated whereas the precious semantic data stays intact. The distinction between the encoded and paraphrased solutions can then be used to decode the hid data.

The researchers employed two paraphrasing methods. The default approach prompts GPT-3.5-Turbo to paraphrase the unique reply whereas preserving the semantic data. A second methodology, termed “Context-aware paraphrasing,” contains the unique query within the immediate and instructs GPT-3.5-Turbo to paraphrase the reply whereas retaining solely the knowledge pertinent to the unique query.
Their experiments demonstrated that, for sure duties, paraphrasing can successfully remove the hidden data from the LLM’s output with out compromising its high quality.
Nonetheless, analysis on this space of LLMs remains to be nascent, and there’s a lot work to be achieved. The examine primarily targeted on encoded reasoning abilities acquired by means of supervised studying. Future analysis may develop on this proof of idea and examine when and the way LLMs educated with reinforcement studying can develop their very own steganography methods.
“We imagine that LLM steganography qualifies as a harmful functionality,” the researchers write.