
In fashionable machine studying and synthetic intelligence frameworks, transformers are one of the vital extensively used parts throughout numerous domains together with GPT collection, and BERT in Pure Language Processing, and Imaginative and prescient Transformers in laptop imaginative and prescient duties. Though together with transformers within the mannequin structure provides a big increase within the mannequin efficiency, the eye module in Transformers scales with the sequence size quadratically, resulting in excessive computational challenges. Through the years, completely different fashions have explored completely different methods to sort out the computational challenges together with strategies like kernelization, historical past reminiscence compression, token mixing vary limitation, and low-rank approaches. Lately, Recurrent Neural Networks like strategies together with Mamba and RWKV have gathered important consideration owing to their promising ends in giant language fashions.
Mamba, a household of fashions has an structure with a Recurrent Neural Community like token mixer of a state area mannequin was just lately launched to handle the quadratic complexity of the eye mechanisms and was utilized to imaginative and prescient duties subsequently. Researchers have already explored methods to include Mamba and SSM or State House Mannequin into visible recognition duties, and Imaginative and prescient Mamba that includes Mamba to develop isotropic imaginative and prescient fashions akin to Imaginative and prescient Transformer is a good instance of the identical. However, LocalMamba incorporates native inductive biases to boost visible Mamba fashions, and VMamba framework employs the bottom Mamba mannequin to assemble hierarchical fashions much like ResNet and AlexNet. Nonetheless, is the Mamba framework actually important for visible recognition context duties? The query arises as a result of the efficiency of the Mamba household of fashions for imaginative and prescient duties has been underwhelming to date in comparison towards conventional attention-based and convolutional fashions.
MambaOut is a piece that makes an attempt to delve into the essence of the Mamba framework, and reply whether or not Mamba is ideally fitted to duties with autoregressive and long-sequence traits. The MambaOut framework hypothesizes that Mamba just isn’t vital for imaginative and prescient duties since picture classification doesn’t align both with long-sequence or autoregressive traits. Though segmentation and detection duties are additionally not autoregressive, they show long-sequence traits, main the MambaOut framework to hypothesize the potential of Mamba for these duties. The MambaOut framework is constructed by stacking Mamba blocks on prime of each other whereas eradicating the state area mannequin, its core token mixer. The experimental outcomes assist the speculation put ahead by the MambaOut framework because it is ready to surpass all of the visible Mamba fashions on the ImageNet picture classification framework, indicating the Mamba just isn’t vital for imaginative and prescient duties. However for detection and segmentation duties, MambaOut framework is unable to duplicate the efficiency supplied by cutting-edge Mamba mannequin, demonstrating the potential of the Mamba household of fashions for long-sequence visible duties.
This text goals to cowl the MambaOut framework in depth, and we discover the mechanism, the methodology, the structure of the framework together with its comparability with cutting-edge frameworks. So let’s get began.
With the progress of machine studying purposes and capabilities, Transformers have emerged because the mainstream spine for a spread of duties, powering outstanding fashions together with Imaginative and prescient Transformers, GPT collection of fashions, BERT, and some extra. Nonetheless, the token mixer of the transformer incurs a quadratic complexity with respect to the sequence size, and poses important challenges for longer sequences. To deal with this challenge, quite a few token mixers with linear complexity to token size like Linformer, Longformer, Performer, Dynamic Convolution, and Massive Chicken have been launched. Nonetheless, in current occasions, Recurrent Neural Community like fashions are gaining prominence owing to their functionality of parallelizable coaching, and delivering environment friendly efficiency on longer sequences. Guided by the outstanding efficiency supplied by RNN-like fashions, researchers try to introduce and make the most of the Mamba household of fashions into visible recognition duties because the token mixer of the Mamba fashions is the structured state area mannequin underneath the spirit of the Recurrent Neural Networks. Nonetheless, experimental outcomes point out that state area mannequin primarily based frameworks for imaginative and prescient carry out underwhelmingly throughout real-world imaginative and prescient duties in comparison towards attention-based, and cutting-edge convolutional fashions.
MambaOut is an try to analyze the character of the Mamba household of fashions, and summarizes that Mamba is fitted to duties which might be both autoregressive or of long-sequence because the state area mannequin has an inherent RNN mechanism. Nonetheless, a majority of imaginative and prescient duties don’t characteristic each of those traits, and on the idea of some experiments, MambaOut proposes the next two hypotheses. First, the state area mannequin just isn’t vital for picture classification because the picture classification process conforms neither to autoregressive nor long-sequence traits. Second, state area fashions could also be hypothetically helpful as an illustration segmentation and semantic segmentation together with object detection, since they comply with the long-sequence traits though they don’t seem to be autoregressive. Experimental outcomes carried out to investigate the Recurrent Neural Community like mechanism of state area mannequin conclude that the Mamba framework is fitted to duties with autoregressive or long-sequence traits, and is pointless for picture classification duties. Coming to the MambaOut framework itself, it’s a collection of Mamba fashions primarily based on Gated Convolutional Neural Community blocks with out the state area mannequin, and experimental outcomes point out that the MambaOut framework is able to outperforming Mamba fashions in picture classification duties, however fails to duplicate the efficiency on picture detection and segmentation duties.
What duties is Mamba appropriate for?
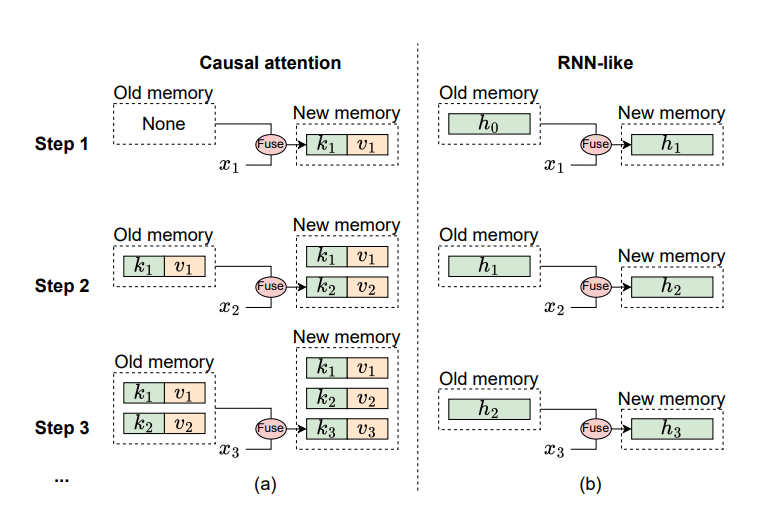
The token mixer of the Mamba framework is a selective state area mannequin that defines 4 input-dependent parameters. The recurrent property of the framework distinguishes RNN-like state area fashions from causal consideration. The hidden state could be seen as a fixed-size reminiscence that shops historic data. The mounted dimension signifies that the reminiscence is lossy, but it surely additionally ensures the computational complexity of integrating reminiscence with the present enter stays fixed. Conversely, causal consideration layers retailer all keys and values from earlier tokens, and expands by including the important thing and worth of the present token with every new enter, and this reminiscence is lossless, theoretically. Nonetheless, the reminiscence dimension grows as extra tokens are inputted, rising the complexity of integrating the reminiscence with the present enter. The distinction between the reminiscence mechanisms between causal consideration and RNN-like fashions are illustrated within the following determine.

Because the reminiscence of the state area mannequin is inherently lossy, it falls wanting the lossless reminiscence of causal consideration, and in consequence, the Mamba fashions can not reveal its energy in dealing with quick sequences, an space the place causal consideration mechanism performs effectively with ease. Nonetheless, in situations that contain lengthy sequences, the causal consideration method falters because of the quadratic complexity. On this situation, the Mamba framework showcases its effectivity in merging reminiscence with the present enter, and is ready to deal with lengthy sequences easily, indicating the Mamba household of fashions is well-suited for processing lengthy sequences.
Additionally it is value noting that on one hand the place the recurrent nature of the state area mannequin permits the Mamba fashions to effectively deal with lengthy sequences, it introduces a sure limitation as it will possibly entry data solely from the present and former timesteps, and any such token mixing is termed causal mode, and illustrated within the following determine. Resulting from its causal nature, this methodology is fitted to autoregressive era duties.

The fully-visible mode is appropriate for understanding duties the place the mannequin can entry all of the inputs directly. Moreover, consideration is in fully-visible mode by default, and it may be become causal mode simply by making use of causal masks to the eye maps, and RNN-like fashions function inherently in causal mode as a result of their recurrent properties. To summarize issues, the Mamba framework is fitted to duties that both contain processing lengthy sequences, or duties that require causal token mixing mode.
Visible Recognition Duties, Causal Token Mixing Code, and Very Giant Sequences
As mentioned earlier, the fully-visible token mixing mode permits unrestricted vary of blending whereas the causal mode limits the present token to entry solely the data from the previous tokens. Moreover, visible recognition is categorized as an understanding process the place the mannequin can see the complete picture directly, and this eliminates the necessity for restrictions on token mixing, and imposing further constraints on token mixing can degrade the mannequin efficiency doubtlessly. Usually, the fully-visible mode is suitable for understanding duties whereas the informal mode fits autoregressive duties higher. Moreover, this declare is supported additional by the truth that BeRT and ViT fashions are used for understanding duties greater than GPT fashions.
Experimental Verification and Outcomes
The subsequent step is to confirm the hypotheses proposed by the MambaOut framework experimentally. As demonstrated within the following picture, the Mamba block relies on the Gated Convolutional Neural Community block, and the meta-architecture of the Mamba and Gated CNN blocks could be handled as a simplified integration of the token mixer of MetaFormer framework, and an MLP.

The Mamba block extends the Gated Convolutional Neural Community with a further State House Mannequin, and the presence of an SSm is what distinguishes the Gated CNN and the Mamba block. Moreover, to enhance the sensible pace, the MambaOut framework conducts solely depthwise convolution on partial channels, and as demonstrated within the following algorithm, the implementation of the Gated CNN block is easy, yeet efficient and stylish.

Picture Classification Job
ImageNet serves because the benchmark for picture classification duties because it consists of over a thousand frequent lessons, over 1.3 million coaching pictures, and over 50,000 validation pictures. The information augmentation used for the experiment consists of random resized crop, Mixup, colour jitter, Random Erasing, CutMix, and Rand Increase. The next desk summarizes the efficiency of the Mamba household of fashions, MambaOut mannequin, and different attention-based & convolution fashions on the ImageNet dataset. As it may be seen, the MambaOut framework with out the state area mannequin outperforms visible Mamba fashions with SSM persistently throughout all mannequin sizes.

For instance, the MambaOut-Small mannequin returns a top-1 accuracy rating of over 84%, 0.4% greater than its nearest Mamba competitor. This outcome strongly helps the primary speculation that claims that introducing a state area mannequin for picture classification duties just isn’t wanted.
Object Detection and Occasion Segmentation Duties
COCO serves as a benchmark for object detection and occasion segmentation duties. Though the MambaOut framework is ready to surpass the efficiency of some visible Mamba fashions, it nonetheless falls wanting cutting-edge visible Mamba fashions together with LocalVMamba and VMamba. The disparity in efficiency of MambaOut towards cutting-edge visible fashions emphasizes on the advantages of integrating the Mamba household of fashions in long-sequence visible duties. Nonetheless, it’s value noting {that a} important efficiency hole nonetheless exists between cutting-edge convolution-attention-hybrid fashions and visible Mamba fashions.

Ultimate Ideas
On this article, we’ve mentioned the ideas of the Mamba household of fashions, and concluded that it’s fitted to duties involving autoregressive and long-sequence traits. MambaOut is a piece that makes an attempt to delve into the essence of the Mamba framework, and reply whether or not Mamba is ideally fitted to duties with autoregressive and long-sequence traits. The MambaOut framework hypothesizes that Mamba just isn’t vital for imaginative and prescient duties since picture classification doesn’t align both with long-sequence or autoregressive traits. Though segmentation and detection duties are additionally not autoregressive, they show long-sequence traits, main the MambaOut framework to hypothesize the potential of Mamba for these duties. The MambaOut framework is constructed by stacking Mamba blocks on prime of each other whereas eradicating the state area mannequin, its core token mixer. The experimental outcomes assist the speculation put ahead by the MambaOut framework because it is ready to surpass all of the visible Mamba fashions on the ImageNet picture classification framework, indicating the Mamba just isn’t vital for imaginative and prescient duties. However for detection and segmentation duties, MambaOut framework is unable to duplicate the efficiency supplied by cutting-edge Mamba mannequin, demonstrating the potential of the Mamba household of fashions for long-sequence visible duties.

