
LLM watermarking, which integrates imperceptible but detectable alerts inside mannequin outputs to determine textual content generated by LLMs, is important for stopping the misuse of enormous language fashions. These watermarking methods are primarily divided into two classes: the KGW Household and the Christ Household. The KGW Household modifies the logits produced by the LLM to create watermarked output by categorizing the vocabulary right into a inexperienced listing and a crimson listing based mostly on the previous token. Bias is launched to the logits of inexperienced listing tokens throughout textual content era, favoring these tokens within the produced textual content. A statistical metric is then calculated from the proportion of inexperienced phrases, and a threshold is established to tell apart between watermarked and non-watermarked textual content. Enhancements to the KGW methodology embrace improved listing partitioning, higher logit manipulation, elevated watermark info capability, resistance to watermark elimination assaults, and the flexibility to detect watermarks publicly.
Conversely, the Christ Household alters the sampling course of throughout LLM textual content era, embedding a watermark by altering how tokens are chosen. Each watermarking households intention to stability watermark detectability with textual content high quality, addressing challenges akin to robustness in various entropy settings, rising watermark info capability, and safeguarding in opposition to elimination makes an attempt. Latest analysis has targeted on refining listing partitioning and logit manipulation), enhancing watermark info capability, growing strategies to withstand watermark elimination, and enabling public detection. In the end, LLM watermarking is essential for the moral and accountable use of enormous language fashions, offering a technique to hint and confirm LLM-generated textual content. The KGW and Christ Households provide two distinct approaches, every with distinctive strengths and functions, constantly evolving by means of ongoing analysis and innovation.
Owing to the flexibility of LLM watermarking frameworks to embed algorithmically detectable alerts in mannequin outputs to determine textual content generated by a LLM framework is taking part in an important position in mitigating the dangers related to the misuse of enormous language fashions. Nevertheless, there’s an abundance of LLM watermarking frameworks out there at the moment, every with their very own views and analysis procedures, thus making it tough for the researchers to experiment with these frameworks simply. To counter this subject, MarkLLM, an open-source toolkit for watermarking provides an extensible and unified framework to implement LLM watermarking algorithms whereas offering user-friendly interfaces to make sure ease of use and entry. Moreover, the MarkLLM framework helps computerized visualization of the mechanisms of those frameworks, thus enhancing the understandability of those fashions. The MarkLLM framework provides a complete suite of 12 instruments protecting three views alongside two automated analysis pipelines for evaluating its efficiency. This text goals to cowl the MarkLLM framework in depth, and we discover the mechanism, the methodology, the structure of the framework together with its comparability with state-of-the-art frameworks. So let’s get began.
The emergence of enormous language mannequin frameworks like LLaMA, GPT-4, ChatGPT, and extra have considerably progressed the flexibility of AI fashions to carry out particular duties together with artistic writing, content material comprehension, formation retrieval, and way more. Nevertheless, together with the exceptional advantages related to the distinctive proficiency of present massive language fashions, sure dangers have surfaced together with educational paper ghostwriting, LLM generated faux information and depictions, and particular person impersonation to call a number of. Given the dangers related to these points, it’s important to develop dependable strategies with the potential of distinguishing between LLM-generated and human content material, a significant requirement to make sure the authenticity of digital communication, and stop the unfold of misinformation. For the previous few years, LLM watermarking has been advisable as one of many promising options for distinguishing LLM-generated content material from human content material, and by incorporating distinct options throughout the textual content era course of, LLM outputs may be uniquely recognized utilizing specifically designed detectors. Nevertheless, on account of proliferation and comparatively complicated algorithms of LLM watermarking frameworks together with the diversification of analysis metrics and views have made it extremely tough to experiment with these frameworks.
To bridge the present hole, the MarkLLM framework makes an attempt tlarge o make the next contributions. MARKLLM provides constant and user-friendly interfaces for loading algorithms, producing watermarked textual content, conducting detection processes, and amassing information for visualization. It supplies customized visualization options for each main watermarking algorithm households, permitting customers to see how totally different algorithms work underneath varied configurations with real-world examples. The toolkit features a complete analysis module with 12 instruments addressing detectability, robustness, and textual content high quality affect. Moreover, it options two varieties of automated analysis pipelines supporting person customization of datasets, fashions, analysis metrics, and assaults, facilitating versatile and thorough assessments. Designed with a modular, loosely coupled structure, MARKLLM enhances scalability and suppleness. This design selection helps the mixing of latest algorithms, progressive visualization methods, and the extension of the analysis toolkit by future builders.
Quite a few watermarking algorithms have been proposed, however their distinctive implementation approaches typically prioritize particular necessities over standardization, resulting in a number of points
- Lack of Standardization in Class Design: This necessitates important effort to optimize or prolong present strategies on account of insufficiently standardized class designs.
- Lack of Uniformity in Prime-Degree Calling Interfaces: Inconsistent interfaces make batch processing and replicating totally different algorithms cumbersome and labor-intensive.
- Code Commonplace Points: Challenges embrace the necessity to modify settings throughout a number of code segments and inconsistent documentation, complicating customization and efficient use. Exhausting-coded values and inconsistent error dealing with additional hinder adaptability and debugging efforts.
To handle these points, our toolkit provides a unified implementation framework that permits the handy invocation of assorted state-of-the-art algorithms underneath versatile configurations. Moreover, our meticulously designed class construction paves the way in which for future extensions. The next determine demonstrates the design of this unified implementation framework.
As a result of framework’s distributive design, it’s simple for builders so as to add further top-level interfaces to any particular watermarking algorithm class with out concern for impacting different algorithms.
MarkLLM : Structure and Methodology
LLM watermarking methods are primarily divided into two classes: the KGW Household and the Christ Household. The KGW Household modifies the logits produced by the LLM to create watermarked output by categorizing the vocabulary right into a inexperienced listing and a crimson listing based mostly on the previous token. Bias is launched to the logits of inexperienced listing tokens throughout textual content era, favoring these tokens within the produced textual content. A statistical metric is then calculated from the proportion of inexperienced phrases, and a threshold is established to tell apart between watermarked and non-watermarked textual content. Enhancements to the KGW methodology embrace improved listing partitioning, higher logit manipulation, elevated watermark info capability, resistance to watermark elimination assaults, and the flexibility to detect watermarks publicly.
Conversely, the Christ Household alters the sampling course of throughout LLM textual content era, embedding a watermark by altering how tokens are chosen. Each watermarking households intention to stability watermark detectability with textual content high quality, addressing challenges akin to robustness in various entropy settings, rising watermark info capability, and safeguarding in opposition to elimination makes an attempt. Latest analysis has targeted on refining listing partitioning and logit manipulation), enhancing watermark info capability, growing strategies to withstand watermark elimination, and enabling public detection. In the end, LLM watermarking is essential for the moral and accountable use of enormous language fashions, offering a technique to hint and confirm LLM-generated textual content. The KGW and Christ Households provide two distinct approaches, every with distinctive strengths and functions, constantly evolving by means of ongoing analysis and innovation.
Automated Complete Analysis
Evaluating an LLM watermarking algorithm is a posh job. Firstly, it requires consideration of assorted facets, together with watermark detectability, robustness in opposition to tampering, and affect on textual content high quality. Secondly, evaluations from every perspective might require totally different metrics, assault eventualities, and duties. Furthermore, conducting an analysis usually entails a number of steps, akin to mannequin and dataset choice, watermarked textual content era, post-processing, watermark detection, textual content tampering, and metric computation. To facilitate handy and thorough analysis of LLM watermarking algorithms, MarkLLM provides twelve user-friendly instruments, together with varied metric calculators and attackers that cowl the three aforementioned analysis views. Moreover, MARKLLM supplies two varieties of automated demo pipelines, whose modules may be custom-made and assembled flexibly, permitting for simple configuration and use.
For the side of detectability, most watermarking algorithms in the end require specifying a threshold to tell apart between watermarked and non-watermarked texts. We offer a primary success charge calculator utilizing a set threshold. Moreover, to attenuate the affect of threshold choice on detectability, we additionally provide a calculator that helps dynamic threshold choice. This device can decide the brink that yields the very best F1 rating or choose a threshold based mostly on a user-specified goal false optimistic charge (FPR).
For the side of robustness, MARKLLM provides three word-level textual content tampering assaults: random phrase deletion at a specified ratio, random synonym substitution utilizing WordNet because the synonym set, and context-aware synonym substitution using BERT because the embedding mannequin. Moreover, two document-level textual content tampering assaults are supplied: paraphrasing the context by way of OpenAI API or the Dipper mannequin. For the side of textual content high quality, MARKLLM provides two direct evaluation instruments: a perplexity calculator to gauge fluency and a range calculator to guage the variability of texts. To investigate the affect of watermarking on textual content utility in particular downstream duties, we offer a BLEU calculator for machine translation duties and a pass-or-not judger for code era duties. Moreover, given the present strategies for evaluating the standard of watermarked and unwatermarked textual content, which embrace utilizing a stronger LLM for judgment, MarkLLM additionally provides a GPT discriminator, using GPT-Quarto evaluate textual content high quality.
Analysis Pipelines
To facilitate automated analysis of LLM watermarking algorithms, MARKLLM supplies two analysis pipelines: one for assessing watermark detectability with and with out assaults, and one other for analyzing the affect of those algorithms on textual content high quality. Following this course of, we’ve carried out two pipelines: WMDetect3 and UWMDetect4. The first distinction between them lies within the textual content era part. The previous requires the usage of the generate_watermarked_text methodology from the watermarking algorithm, whereas the latter will depend on the text_source parameter to find out whether or not to straight retrieve pure textual content from a dataset or to invoke the generate_unwatermarked_text methodology.
To guage the affect of watermarking on textual content high quality, pairs of watermarked and unwatermarked texts are generated. The texts, together with different obligatory inputs, are then processed and fed into a chosen textual content high quality analyzer to provide detailed evaluation and comparability outcomes. Following this course of, we’ve carried out three pipelines for various analysis eventualities:
- DirectQual.5: This pipeline is particularly designed to research the standard of texts by straight evaluating the traits of watermarked texts with these of unwatermarked texts. It evaluates metrics akin to perplexity (PPL) and log range, with out the necessity for any exterior reference texts.
- RefQual.6: This pipeline evaluates textual content high quality by evaluating each watermarked and unwatermarked texts with a typical reference textual content. It measures the diploma of similarity or deviation from the reference textual content, making it ultimate for eventualities that require particular downstream duties to evaluate textual content high quality, akin to machine translation and code era.
- ExDisQual.7: This pipeline employs an exterior judger, akin to GPT-4 (OpenAI, 2023), to evaluate the standard of each watermarked and unwatermarked texts. The discriminator evaluates the texts based mostly on user-provided job descriptions, figuring out any potential degradation or preservation of high quality on account of watermarking. This methodology is especially useful when a sophisticated, AI-based evaluation of the refined results of watermarking is required.
MarkLLM: Experiments and Outcomes
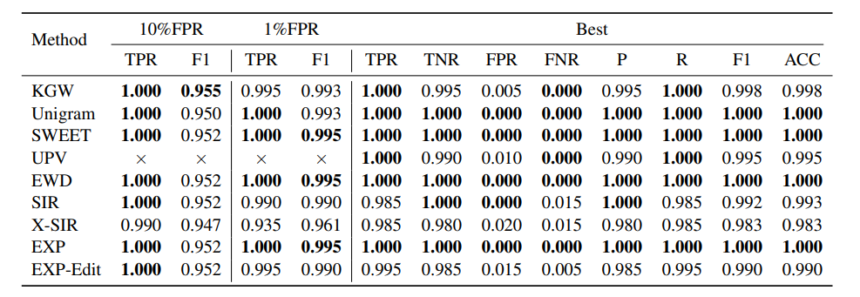
To guage its efficiency, the MarkLLM framework conducts evaluations on 9 totally different algorithms, and assesses their affect, robustness, and detectability on the standard of textual content.

The above desk incorporates the analysis outcomes of assessing the detectability of 9 algorithms supported in MarkLLM. Dynamic threshold adjustment is employed to guage watermark detectability, with three settings supplied: underneath a goal FPR of 10%, underneath a goal FPR of 1%, and underneath circumstances for optimum F1 rating efficiency. 200 watermarked texts are generated, whereas 200 non-watermarked texts function adverse examples. We furnish TPR and F1-score underneath dynamic threshold changes for 10% and 1% FPR, alongside TPR, TNR, FPR, FNR, P, R, F1, ACC at optimum efficiency. The next desk incorporates the analysis outcomes of assessing the robustness of 9 algorithms supported in MarkLLM. For every assault, 200 watermarked texts are generated and subsequently tampered, with a further 200 non-watermarked texts serving as adverse examples. We report the TPR and F1-score at optimum efficiency underneath every circumstance.

Closing Ideas
On this article, we’ve talked about MarkLLM, an open-source toolkit for watermarking that gives an extensible and unified framework to implement LLM watermarking algorithms whereas offering user-friendly interfaces to make sure ease of use and entry. Moreover, the MarkLLM framework helps computerized visualization of the mechanisms of those frameworks, thus enhancing the understandability of those fashions. The MarkLLM framework provides a complete suite of 12 instruments protecting three views alongside two automated analysis pipelines for evaluating its efficiency.

