
VentureBeat presents: AI Unleashed – An unique government occasion for enterprise information leaders. Community and study with business friends. Learn More
Meta Platforms confirmed off a bevy of latest AI options for its consumer-facing providers Fb, Instagram and WhatsApp at its annual Meta Join convention in Menlo Park, California, this week.
However the greatest information from Mark Zuckerberg’s firm might have truly come within the type of a pc science paper printed with out fanfare by Meta researchers on the open entry and non-peer reviewed web site arXiv.org.
The paper introduces Llama 2 Lengthy, a brand new AI mannequin primarily based on Meta’s open supply Llama 2 launched in the summertime, however that has undergone “continuous pretraining from Llama 2 with longer coaching sequences and on a dataset the place lengthy texts are upsampled,” in line with the researcher-authors of the paper.
Because of this, Meta’s newly elongated AI mannequin outperforms among the main competitors in producing responses to lengthy (greater character depend) person prompts, together with OpenAI’s GPT-3.5 Turbo with 16,000-character context window, in addition to Claude 2 with its 100,000-character context window.
How LLama 2 Lengthy got here to be
Meta researchers took the unique Llama 2 accessible in its completely different coaching parameter sizes — the values of information and data the algorithm can change by itself because it learns, which within the case of Llama 2 are available in 7 billion, 13 billion, 34 billion, and 70 billion variants — and included extra longer textual content information sources than the unique Llama 2 coaching dataset. One other 400 billion tokens-worth, to be actual.
Then, the researchers saved the unique Llama 2’s structure the identical, and solely made a “essential modification to the positional encoding that’s essential for the mannequin to attend longer.”
That modification was to the Rotary Positional Embedding (RoPE) encoding, a technique of programming the transformer mannequin underlying LLMs resembling Llama 2 (and LLama 2 Lengthy), which primarily maps their token embeddings (the numbers used to characterize phrases, ideas, and concepts) onto a 3D graph that exhibits their positions relative to different tokens, even when rotated. This enables a mannequin to provide correct and useful responses, with much less info (and thus, much less computing storage taken up) than different approaches.
The Meta researchers “decreased the rotation angle” of its RoPE encoding from Llama 2 to Llama 2 Lengthy, which enabled them to make sure extra “distant tokens,” these occurring extra not often or with fewer different relationships to different items of data, had been nonetheless included within the mannequin’s information base.
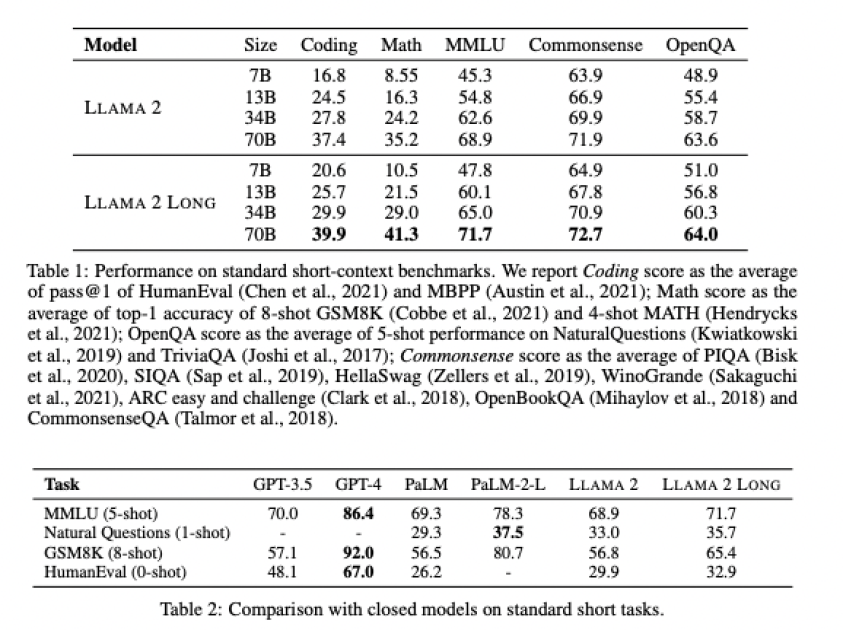
Utilizing reinforcement learning from human feedback (RLHF), a typical AI mannequin coaching methodology the place AI is rewarded for proper solutions with human oversight to examine it, and artificial information generated by Llama 2 chat itself, the researchers had been capable of enhance its efficiency in widespread LLM duties together with coding, math, language understanding, widespread sense reasoning, and answering a human person’s prompted questions.

With such spectacular outcomes relative to each Llama 2 common and Anthropic’s Claude 2 and OpenAI’s GPT-3.5 Turbo, it’s little surprise the open-source AI neighborhood on Reddit and Twitter and Hacker News have been expressing their admiration and pleasure about Llama 2 for the reason that paper’s launch earlier this week — it’s a giant validation of Meta’s “open supply” method towards generative AI, and signifies that open supply can compete with the closed supply, “pay to play” fashions supplied by well-funded startups.