
Be part of our every day and weekly newsletters for the newest updates and unique content material on industry-leading AI protection. Be taught Extra
Multi-modal fashions that may course of each textual content and pictures are a rising space of analysis in synthetic intelligence. Nonetheless, coaching these fashions presents a novel problem: language fashions take care of discrete values (phrases and tokens), whereas picture technology fashions should deal with steady pixel values.
Present multi-modal fashions use strategies that scale back the standard of representing knowledge. In a new research paper, scientists from Meta and the University of Southern California introduce Transfusion, a novel approach that allows a single mannequin to seamlessly deal with each discrete and steady modalities.
The challenges of multi-modal fashions
Present approaches to deal with the multi-modality problem usually contain completely different tradeoffs. Some strategies use separate architectures for language and picture processing, usually pre-training every element individually. That is the tactic utilized in fashions corresponding to LLaVA. These fashions wrestle to be taught the complicated interactions between completely different modalities, particularly when processing paperwork the place photographs and textual content are interleaved.
Different strategies quantize photographs into discrete values, successfully changing them right into a sequence of tokens just like textual content. That is the strategy utilized by Meta’s Chameleon, which was launched earlier this 12 months. Whereas this strategy permits the usage of language fashions for picture processing, it leads to the lack of info contained within the steady pixel values.

Chunting Zhou, Senior Analysis Scientist at Meta AI and co-author of the paper, beforehand labored on the Chameleon paper.
“We observed that the quantization methodology creates an info bottleneck for picture representations, the place discrete representations of photographs are extremely compressed and lose info within the unique photographs,” she instructed VentureBeat. “And within the meantime it’s very tough to coach an excellent discrete picture tokenizer. Thus, we requested the query ‘Can we simply use the extra pure steady representations of photographs once we practice a multi-modal mannequin along with discrete textual content?’”
Transfusion: A unified strategy to multi-modal studying
“Diffusion fashions and next-token-prediction autoregressive fashions signify the perfect worlds for producing steady and discrete knowledge respectively,” Zhou mentioned. “This impressed us to develop a brand new multi-modal methodology that mixes the perfect of each worlds in a pure and easy method.”
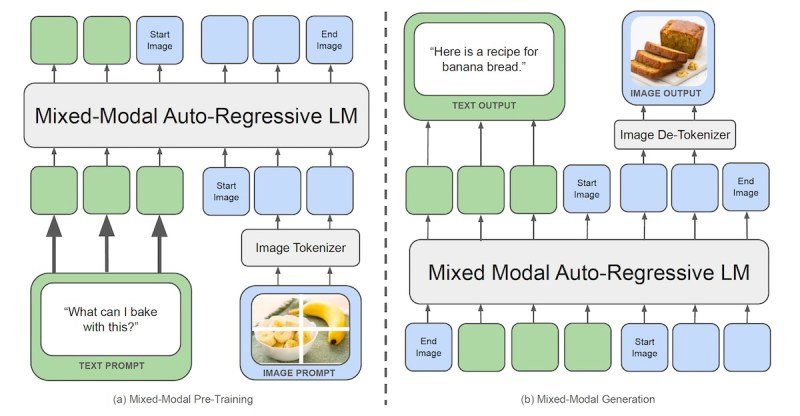
Transfusion is a recipe for coaching a single mannequin that may deal with each discrete and steady modalities with out the necessity for quantization or separate modules. The core concept behind Transfusion is to coach a single mannequin with two aims: language modeling for textual content and diffusion for photographs.
Transfusion combines these two aims to coach a transformer mannequin that may course of and generate each textual content and pictures. Throughout coaching, the mannequin is uncovered to each textual content and picture knowledge, and the loss capabilities for language modeling and diffusion are utilized concurrently.

“We present it’s doable to completely combine each modalities, with no info loss, by coaching a single mannequin to each predict discrete textual content tokens and diffuse steady photographs,” the researchers write.
Transfusion makes use of a unified structure and vocabulary to course of mixed-modality inputs. The mannequin contains light-weight modality-specific elements that convert textual content tokens and picture patches into the suitable representations earlier than they’re processed by the transformer.
To enhance the illustration of picture knowledge, Transfusion makes use of variational autoencoders (VAE), neural networks that may be taught to signify complicated knowledge, corresponding to photographs, in a lower-dimensional steady house. In Transfusion, a VAE is used to encode every 8×8 patch of a picture into a listing of steady values.

“Our important innovation is demonstrating that we are able to use separate losses for various modalities – language modeling for textual content, diffusion for photographs – over shared knowledge and parameters,” the researchers write.
Transfusion outperforms quantization-based approaches
The researchers educated a 7-billion mannequin primarily based on Transfusion and evaluated it on a wide range of normal uni-modal and cross-modal benchmarks, together with text-to-text, text-to-image, and image-to-text duties. They in contrast its efficiency to an equally-sized mannequin primarily based on Chameleon, which is the present outstanding open-science methodology for coaching native mixed-modal fashions.
Of their experiments, Transfusion constantly outperformed the Chameleon throughout all modalities. In text-to-image technology, Transfusion achieved higher outcomes with lower than a 3rd of the computational value of Chameleon. Equally, in image-to-text technology, Transfusion matched Chameleon’s efficiency with solely 21.8% of the computational sources.
Surprisingly, Transfusion additionally confirmed higher efficiency on text-only benchmarks, regardless that each Transfusion and Chameleon use the identical language modeling goal for textual content. This means that coaching on quantized picture tokens can negatively impression textual content efficiency.
“As a substitute, Transfusion scales higher than the generally adopted multi-modal coaching approaches with discrete picture tokens by a big margin throughout the board,” Zhou mentioned.

The researchers ran separate experiments on picture technology and in contrast Transfusion with different picture technology fashions. Transfusion outperformed different fashionable fashions corresponding to DALL-E 2 and Steady Diffusion XL whereas additionally with the ability to generate textual content.
“Transfusion opens up plenty of new alternatives for multi-modal studying and new fascinating use instances,” Zhou mentioned. “As Transfusion works simply as LLM however on multi-modality knowledge, this doubtlessly unlocks new functions with higher controllability on interactive classes of person inputs, e.g. interactive enhancing of photographs and movies.”
Source link