
Over the previous few years, Massive Language Fashions (LLMs) have garnered consideration from AI builders worldwide because of breakthroughs in Pure Language Processing (NLP). These fashions have set new benchmarks in textual content era and comprehension. Nonetheless, regardless of the progress in textual content era, producing photos that coherently match textual narratives remains to be difficult. To deal with this, builders have launched an progressive imaginative and prescient and language era method primarily based on “generative vokens,” bridging the hole for harmonized text-image outputs.
The inspiration behind MiniGPT-5 is a two-staged coaching technique that focuses closely on description-free multimodal knowledge era the place the coaching knowledge doesn’t require any complete picture descriptions. Moreover, to spice up the mannequin’s integrity, the mannequin incorporates a classifier-free steering system that enhances the effectiveness of a voken for picture era. Within the preliminary part, the MiniGPT-5 framework has demonstrated highly effective efficiency and a considerable enchancment over the baseline Divter mannequin that’s skilled on the MMDialog dataset, and has continuously demonstrated its capacity to ship comparable & even superior multimodal outputs within the human evaluations carried out on the VIST dataset that additional highlights its efficiency & effectivity throughout varied benchmarks.
With the latest developments of the LLM frameworks, and purposes primarily based on these LLM frameworks, multimedia characteristic integration is a discipline that has witnessed an increase in its reputation because it additionally proves to be a significant development that powers a big selection of purposes from state-of-the-art content material creation instruments to cutting-edge multimodal dialogue agent. With steady analysis and growth, language and imaginative and prescient fashions are on the level the place work is occurring to facilitate them to generate each textual content & visible knowledge seamlessly. The power of LLM to generate multimodal knowledge seamlessly will assist in enhancing interactions throughout totally different domains together with e-commerce, media, and digital actuality.

In the end, the goal is to permit fashions to synthesize, acknowledge, and reply in a constant & logical approach utilizing each textual & visible modalities, thus taking part in a vital position in harmonizing the circulation of knowledge, and creating logical & constant narratives. The necessity to obtain a mix of textual & visible modalities is fueled primarily by the necessity of extra fluid, built-in & interactive multimodal interactions in LLMs, and in the end reaching the alternating language and imaginative and prescient era. Nonetheless, reaching built-in & interactive multimodal interactions in LLMs is an advanced activity riddled with quite a few challenges together with
- Though present LLM are extraordinarily environment friendly & succesful in terms of textual content era, and processing text-image pairs, they don’t ship passable efficiency in terms of producing photos.
- The event of those imaginative and prescient and language fashions depends closely on topic-focused knowledge that makes it difficult for fashions to align the generated textual content with its corresponding photos.
- Lastly, there’s a have to give you simpler methods as with a rise of their capabilities, the reminiscence necessities of LLMs additionally enhance particularly when performing downstream duties.
The MiniGPT-5 framework, an interleaved language & imaginative and prescient producing algorithm method that introduces the idea of “generative vokens” in an try to handle the challenges talked about above. The MiniGPT-5 framework proposes a brand new method for multimodal knowledge era by amalgamating Massive Language Fashions with Secure Diffusion methods through the use of particular visible tokens. The proposed two-stage coaching technique utilized by the MiniGPT-5 framework highlights the significance of a foundational stage freed from descriptions, and making ready the mannequin to ship environment friendly efficiency even in eventualities with restricted knowledge.

However what separates the MiniGPT-5 mannequin from present present frameworks is that the generic levels of the MiniGPT-5 framework don’t include area particular annotations. Moreover, to make sure that the generated textual content, and their corresponding photos are in concord with each other, the MiniGPT-5 framework deploys a dual-loss technique that additional enhances MiniGPT-5’s method of utilizing classifier-free steering and generative vokens. The MiniGPT-5 framework optimizes coaching effectivity, and addresses the reminiscence constraints due to their parameter-efficient technique for tremendous tuning the mannequin.
To give you a fast abstract, the MiniGPT-5 framework
- Proposes a way that makes use of multimodal encoders that characterize a novel & generic technique that has traditionally proved to be simpler than conventional LLMs, and makes use of generative tokens mixed with Secure Diffusion methods to generate interleaved language & visible outputs.
- Proposes a dual-stage coaching technique for era of description-free multimodal output, and the inclusion of classifier-free steering throughout coaching to additional refine the standard of information generated.
The MiniGPT-5 mannequin is impressed closely from the earlier analysis & work completed within the fields of
- Textual content to Picture Technology : To facilitate the transformation of textual descriptions into their respective visible representations, and textual content to picture fashions.
- MLLMs or Multimodal Massive Language Fashions : Utilizing pre-trained LLM fashions to discover their purposes & effectiveness in producing multimodal knowledge.
- Multimodal Technology with Massive Language Fashions : To reinforce the capabilities of a LLM to seamlessly combine language & visible knowledge era.
MiniGPT-5 : Methodology, Structure, and Framework
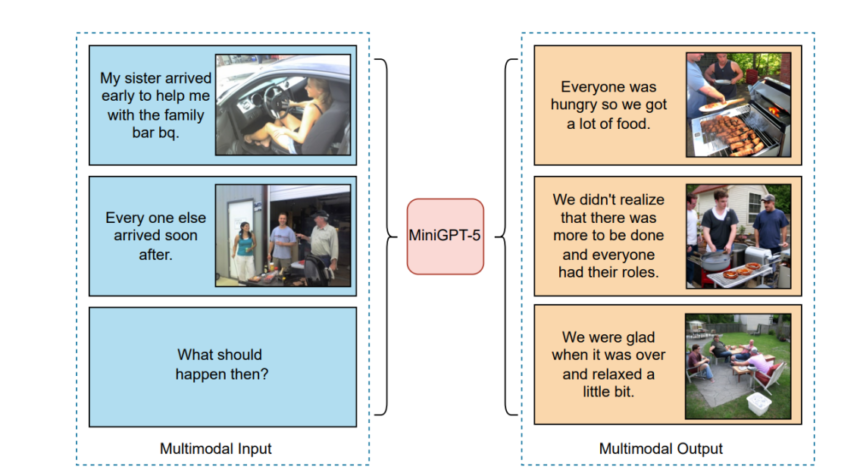
To facilitate giant language fashions with multimodal knowledge era capabilities, the MiniGPT-5 mannequin introduces a framework that goals to combine textual content to picture era fashions and pretrained multimodal giant language fashions. The MiniGPT-5 framework additional introduces the “generative vokens”, particular visible tokens that enables builders to handle the discrepancies that seem throughout totally different domains by with the ability to practice instantly on uncooked photos. To additional improve the standard of the multimodal knowledge generated by the LLMs, the MiniGPT-5 framework introduces a classifier-free technique coupled with a sophisticated two-stage coaching technique. Let’s have an in depth have a look at the MiniGPT-5 framework.
MultiModal Enter Stage
Developments of LLMs within the latest previous have introduced LLMs multimodal comprehension talents to gentle, enabling processing photos as a sequential enter. The MiniGPT-5 framework makes use of specifically designed generative vokens for outputting visible options in an try to broaden LLMs multimodal comprehension talents to multimodal knowledge era. Moreover, the MiniGPT-5 framework makes use of parameter environment friendly and leading edge tremendous tuning methods for multimodal output studying with the LLM framework.
Multimodal Encoding
The pretrained visible encoder within the MiniGPT-5 framework transforms every enter picture right into a characteristic, and every textual content token is embedded as a vector, and the enter immediate options are generated when these embeddings are concatenated with each other.
Including Vokens in Massive Language Fashions
Historically, Massive Language Mannequin vocabulary consists solely of textual tokens which is why the builders engaged on the MiniGPT-5 framework needed to bridge the hole between the generative & the normal LLMs. The MiniGPT-5 framework introduces a set of particular tokens as generative tokens into the vocabulary of the LLM. The framework then harnesses the hidden output state of the LLM for these particular vokens for subsequent picture era, and the insertion of interleaved photos is represented by the place of the vokens.
PEFT or Parameter Environment friendly High quality Tuning
PEFT or Parameter Environment friendly High quality Tuning is a vital idea used to coach LLMs, and but, the purposes of PEFT in multimodal settings remains to be unexplored to a reasonably large extent. The MiniGPT-5 framework makes use of the Parameter Environment friendly High quality Tuning over the encoder of the MiniGPT-4 framework in an effort to practice the mannequin to know prompts or directions higher, and even enhancing the general efficiency of the mannequin in a zero-shot or novel environments.
Multimodal Output Technology
To align the generative mannequin with the generative tokens precisely, the MiniGPT-5 framework formulates a compact mapping module for matching the size, and incorporating supervisory losses together with latent diffusion mannequin loss, and textual content area loss. The latent diffusion supervisory loss aligns the suitable visible options with the tokens instantly whereas the textual content area loss helps the mannequin study the right positions of the tokens. As a result of the generative vokens within the MiniGPT-5 framework are guided instantly by the pictures, the MiniGPT-5 framework doesn’t require photos to have a complete description, leading to a description-free studying.
Textual content Area Technology
The MiniGPT-5 framework follows the informal language modeling technique to generate each vokens and texts within the textual content area collectively, and in the course of the coaching part, the builders append the vokens to the place of the bottom fact photos, and practice the mannequin to foretell vokens inside textual content era.
Mapping Voken Options for Picture Technology
After producing the textual content area, the framework aligns the hidden output state with the textual content conditional characteristic area of the textual content to picture era mannequin. The framework additionally helps a characteristic mapper module that features a dual-layer MLP mannequin, a learnable decoder characteristic sequence, and a four-layer encoder-decoder transformer mannequin.
Picture Technology with LDM or Latent Diffusion Mannequin
To generate the required photos within the denoising course of, the framework makes use of the mapping options as a conditional enter. The framework additionally employs a LDM or Latent Diffusion Mannequin for steering, as in the course of the coaching part, the bottom fact picture is first transformed right into a latent characteristic utilizing a pre-trained VAE following which, the builders receive the latent noise characteristic by including some noise.
The excellent method deployed by the MiniGPT-5 framework permits builders to have a coherent understanding, and era of each visible and textual parts, utilizing specialised tokens, leveraging the capabilities of pretrained fashions, and utilizing progressive coaching methods.
MiniGPT-5 : Coaching and Outcomes
When engaged on the MiniGPT-5 framework, builders noticed that coaching on a restricted interleaved text-and-image dataset instantly can lead to photos with diminished high quality, and misalignment given the numerous area shift between the picture & textual content domains. To mitigate this concern, builders adopted two distinct coaching methods,
- Encompassing the incorporation of classifier-free steering methods that reinforces the effectiveness of generative tokens in the course of the diffusion course of.
- The second technique is additional divided into two levels
- An preliminary pre-training stage that focuses totally on aligning coarse options.
- A fine-tuning stage that facilitates characteristic studying.
CFG or Classifier Free Steering
The concept to first leverage CFG for multimodal era got here because of an try to reinforce consistency & logic between the generated photos & texts, and the CFG is launched in the course of the textual content to picture diffusion course of. This technique observes that by coaching on each unconditional and conditional era with conditioning dropout, the generative mannequin can obtain enhanced conditional outcomes.
Two-Stage Coaching Technique
Given the numerous area shift noticed between text-image era, and pure textual content era, the MiniGPT-5 framework makes use of a two-stage technique for coaching
- Unimodal Alignment Stage or UAS,
- Multimodal Studying Stage or MLS.
Initially, the framework aligns the picture era options with the voken characteristic in single text-image pair datasets the place every knowledge pattern comprises just one textual content, and just one picture, and the textual content is often the picture caption. On this stage, the framework permits the LLM to generate vokens by using captions as LLM inputs.
As soon as the UAS has executed efficiently, the mannequin can generate photos for single textual content descriptions, however struggles with interleaved language and imaginative and prescient era together with text-image pairs, and complex reasoning is required for picture and textual content era. To deal with this hurdle, the builders have additional tremendous tuned the MiniGPT-5 framework utilizing PEFT parameters by interleaved vision-and-language datasets like VIST. Throughout this stage, the framework constructs three totally different duties from the dataset
- Textual content Solely Technology : Generates the associated textual content given the following picture.
- Picture Solely Technology : Generates the associated picture given the following textual content.
- Multimodal Technology : Generates textual content picture pairs utilizing the given context.
MiniGPT-5 : Benchmarks and Outcomes
To judge its efficiency in multimodal era comprehensively, the MiniGPT-5 growth crew compares its efficiency with different outstanding baseline fashions together with Divter, GILL, and the High quality Tuned Unimodal Technology Mannequin, and the comparability is demonstrated within the desk under.

The MiniGPT-5 framework understands that the multimodal output could be significant as per the context, but it would differ from the bottom actuality which is the first motive why the MiniGPT-5 framework additionally incorporates human inputs to guage & assess the efficiency of the mannequin. Total, the effectiveness of the MiniGPT-5 framework for multimodal duties is measured utilizing three views.
- Language Continuity : assessing whether or not the generated content material aligns with the offered context seamlessly.
- Picture High quality : assessing or evaluating the relevance & readability of the picture generated.
- Multimodal Coherence : to find out whether or not the mixed textual content picture output is in sync with the preliminary context.
VIST Closing Step Analysis
Within the first stage of experiments, the MiniGPT-5 framework goals to generate the corresponding photos, and the desk under summarizes the outcomes obtained from this setting.

As it may be seen, the MiniGPT-5 framework in all of the three settings can outperform the fine-tuned SD2 framework, thus highlighting the effectiveness of the MiniGPT-5 pipeline.

The determine above compares the efficiency of the MiniGPT-5 framework with the fine-tuned MiniGPT-4 framework on the S-BERT, Rouge-L and Meteor efficiency metrics. The outcomes point out that using generative vokens doesn’t have an effect on the efficiency of the framework negatively when performing multimodal comprehension duties. The outcomes additionally exhibit that the MiniGPT-5 framework is able to using long-horizontal multimodal enter prompts throughout a big selection of information to generate high-quality & coherent photos with out compromising the flexibility of the unique mannequin for multimodal comprehension.

The desk above compares the efficiency of three frameworks on 5,000 samples for multimodal era from the points of Multimodal Coherence, Picture High quality, and Language Continuity. As it may be noticed, the MiniGPT-5 framework outperforms the opposite two baseline fashions by greater than 70% circumstances. Then again, the desk under demonstrates the efficiency of the MiniGPT-5 framework on the CC3M validation dataset for the era of single photos. Due to knowledge limitations, builders discovered a spot for voken alignment when used with Secure Diffusion. Regardless of this limitation, the MiniGPT-5 framework outperforms the present state-of-the-art baseline GILL framework throughout all metrics.


Conclusion
On this article, we’ve talked about MiniGPT-5, an interleaved language & imaginative and prescient producing algorithm method that introduces the idea of “generative vokens” in an try to harness the capabilities of LLMs to generate multimodal knowledge y aligning the massive language mannequin with a textual content to picture era mannequin that’s pre-trained. We’ve talked concerning the important elements & the general structure of the MiniGPT-5 framework together with the outcomes that point out substantial enhancements in efficiency & effectivity compared with the present baseline & state-of-the-art fashions. MiniGPT-5 aspires to set a brand new benchmark within the multimodal content material & knowledge era area, and goals to resolve the challenges confronted by earlier fashions when making an attempt to unravel the identical drawback.