
Based by alums from Google’s DeepMind and Meta, Paris-based startup Mistral AI has constantly made waves within the AI group since 2023.
Mistral AI first caught the world’s consideration with its debut mannequin, Mistral 7B, launched in 2023. This 7-billion parameter mannequin rapidly gained traction for its spectacular efficiency, surpassing bigger fashions like Llama 2 13B in varied benchmarks and even rivaling Llama 1 34B in lots of metrics. What set Mistral 7B aside was not simply its efficiency, but in addition its accessibility – the mannequin might be simply downloaded from GitHub and even through a 13.4-gigabyte torrent, making it available for researchers and builders worldwide.
The corporate’s unconventional method to releases, typically foregoing conventional papers, blogs, or press releases, has confirmed remarkably efficient in capturing the AI group’s consideration. This technique, coupled with their dedication to open-source ideas, has positioned Mistral AI as a formidable participant within the AI panorama.
Mistral AI’s fast ascent within the trade is additional evidenced by their latest funding success. The corporate achieved a staggering $2 billion valuation following a funding spherical led by Andreessen Horowitz. This got here on the heels of a historic $118 million seed spherical – the biggest in European historical past – showcasing the immense religion traders have in Mistral AI’s imaginative and prescient and capabilities.
Past their technological developments, Mistral AI has additionally been actively concerned in shaping AI coverage, notably in discussions across the EU AI Act, the place they’ve advocated for lowered regulation in open-source AI.
Now, in 2024, Mistral AI has as soon as once more raised the bar with two groundbreaking fashions: Mistral Large 2 (also referred to as Mistral-Massive-Instruct-2407) and Mistral NeMo. On this complete information, we’ll dive deep into the options, efficiency, and potential purposes of those spectacular AI fashions.
Key specs of Mistral Massive 2 embrace:
- 123 billion parameters
- 128k context window
- Assist for dozens of languages
- Proficiency in 80+ coding languages
- Superior operate calling capabilities
The mannequin is designed to push the boundaries of price effectivity, velocity, and efficiency, making it a sexy choice for each researchers and enterprises seeking to leverage cutting-edge AI.
Mistral NeMo: The New Smaller Mannequin
Whereas Mistral Massive 2 represents one of the best of Mistral AI’s large-scale fashions, Mistral NeMo, launched on July, 2024, takes a special method. Developed in collaboration with NVIDIA, Mistral NeMo is a extra compact 12 billion parameter mannequin that also gives spectacular capabilities:
- 12 billion parameters
- 128k context window
- State-of-the-art efficiency in its dimension class
- Apache 2.0 license for open use
- Quantization-aware coaching for environment friendly inference
Mistral NeMo is positioned as a drop-in alternative for programs presently utilizing Mistral 7B, providing enhanced efficiency whereas sustaining ease of use and compatibility.
Key Options and Capabilities
Each Mistral Massive 2 and Mistral NeMo share a number of key options that set them aside within the AI panorama:
- Massive Context Home windows: With 128k token context lengths, each fashions can course of and perceive for much longer items of textual content, enabling extra coherent and contextually related outputs.
- Multilingual Assist: The fashions excel in a variety of languages, together with English, French, German, Spanish, Italian, Chinese language, Japanese, Korean, Arabic, and Hindi.
- Superior Coding Capabilities: Each fashions reveal distinctive proficiency in code technology throughout quite a few programming languages.
- Instruction Following: Important enhancements have been made within the fashions’ capability to comply with exact directions and deal with multi-turn conversations.
- Operate Calling: Native assist for operate calling permits these fashions to work together dynamically with exterior instruments and providers.
- Reasoning and Drawback-Fixing: Enhanced capabilities in mathematical reasoning and sophisticated problem-solving duties.
Let’s delve deeper into a few of these options and look at how they carry out in follow.
Efficiency Benchmarks
To know the true capabilities of Mistral Massive 2 and Mistral NeMo, it is important to take a look at their efficiency throughout varied benchmarks. Let’s look at some key metrics:
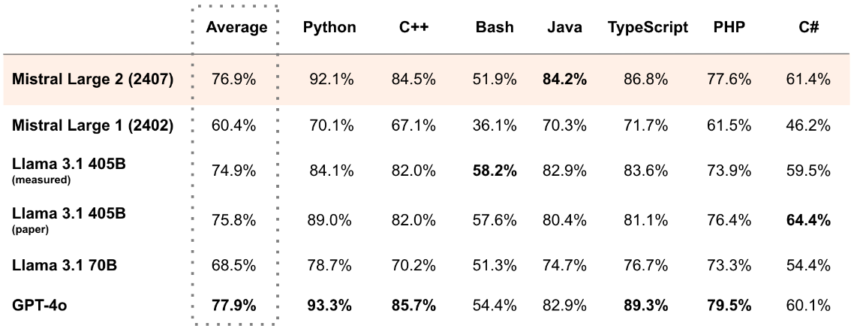
Mistral Massive 2 Benchmarks
This desk presents the proficiency of varied LLMs in numerous programming languages. Fashions like Mistral Massive 2 (24.07), Llama 3.1 (405B), and GPT-4o are evaluated on their capability to grasp and generate code in languages reminiscent of Python, C++, Bash, Java, TypeScript, PHP, and C#.
Llama 3.1 405B exhibits robust efficiency throughout a number of languages, with notably excessive scores in Python and Java. This proficiency is important for purposes involving code technology, debugging, and software program growth, making these fashions precious instruments for builders.

https://mistral.ai/information/mistral-large-2407/

https://mistral.ai/information/mistral-large-2407/
Mistral NeMo Benchmarks
Whereas particular benchmark scores for Mistral NeMo will not be supplied within the given info, it is described as providing state-of-the-art efficiency in its dimension class. The mannequin outperforms different latest open-source pre-trained fashions like Gemma 2 9B and Llama 3 8B in varied duties.

Multilingual and Coding Prowess
One of many standout options of each Mistral Massive 2 and Mistral NeMo is their distinctive multilingual capabilities. That is notably necessary in our more and more globalized world, the place AI fashions want to grasp and generate content material in a number of languages.
Mistral Massive 2, for example, helps dozens of languages together with French, German, Spanish, Italian, Portuguese, Arabic, Hindi, Russian, Chinese language, Japanese, and Korean. This multilingual proficiency extends past mere translation, encompassing nuanced understanding and technology in these languages.
As an example this, let us take a look at an instance of Mistral Massive 2 producing textual content in a number of languages:
[INST] Generate a brief greeting in English, French, German, Spanish, and Japanese. [/INST]
Listed below are brief greetings within the requested languages:
English: Hey! How are you immediately?
French: Bonjour ! Remark allez-vous aujourd’hui ?
German: Hallo! Wie geht es Ihnen heute?
Spanish: ¡Hola! ¿Cómo estás hoy?
Japanese: こんにちは!今日はお元気ですか?
[INST]
Now, write a easy “Hey, World!” program in Python, Java, and JavaScript. [/INST]
These examples showcase each the multilingual textual content technology and coding capabilities of the mannequin.
Each fashions can be found on varied platforms reminiscent of Hugging Face, Mistral AI’s platform, and main cloud service suppliers like Google Cloud Platform, Azure AI Studio, Amazon Bedrock, and IBM watsonx.ai (Mistral AI | Frontier AI in your hands).
The Agentic Paradigm and Operate Calling
Each Mistral Massive 2 and Mistral NeMo embrace an agentic-centric design, which represents a paradigm shift in how we work together with AI fashions. This method focuses on constructing fashions able to interacting with their atmosphere, making choices, and taking actions to realize particular targets.
A key characteristic enabling this paradigm is the native assist for operate calling. This enables the fashions to dynamically work together with exterior instruments and providers, successfully increasing their capabilities past easy textual content technology.
Let’s take a look at an instance of how operate calling would possibly work with Mistral Massive 2:
from mistral_common.protocol.instruct.tool_calls import Operate, Software
from mistral_inference.transformer import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
# Initialize tokenizer and mannequin
mistral_models_path = "path/to/mistral/fashions" # Guarantee this path is appropriate
tokenizer = MistralTokenizer.from_file(f"{mistral_models_path}/tokenizer.mannequin.v3")
mannequin = Transformer.from_folder(mistral_models_path)
# Outline a operate for getting climate info
weather_function = Operate(
title="get_current_weather",
description="Get the present climate",
parameters={
"kind": "object",
"properties": {
"location": {
"kind": "string",
"description": "Town and state, e.g. San Francisco, CA",
},
"format": {
"kind": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to make use of. Infer this from the person's location.",
},
},
"required": ["location", "format"],
},
)
# Create a chat completion request with the operate
completion_request = ChatCompletionRequest(
instruments=[Tool(function=weather_function)],
messages=[
UserMessage(content="What's the weather like today in Paris?"),
],
)
# Encode the request
tokens = tokenizer.encode_chat_completion(completion_request).tokens
# Generate a response
out_tokens, _ = generate([tokens], mannequin, max_tokens=256, temperature=0.7, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
end result = tokenizer.decode(out_tokens[0])
print(end result)
On this instance, we outline a operate for getting climate info and embrace it in our chat completion request. The mannequin can then use this operate to retrieve real-time climate knowledge, demonstrating the way it can work together with exterior programs to supply extra correct and up-to-date info.
Tekken: A Extra Environment friendly Tokenizer
Mistral NeMo introduces a brand new tokenizer referred to as Tekken, which is predicated on Tiktoken and educated on over 100 languages. This new tokenizer gives vital enhancements in textual content compression effectivity in comparison with earlier tokenizers like SentencePiece.
Key options of Tekken embrace:
- 30% extra environment friendly compression for supply code, Chinese language, Italian, French, German, Spanish, and Russian
- 2x extra environment friendly compression for Korean
- 3x extra environment friendly compression for Arabic
- Outperforms the Llama 3 tokenizer in compressing textual content for roughly 85% of all languages
This improved tokenization effectivity interprets to raised mannequin efficiency, particularly when coping with multilingual textual content and supply code. It permits the mannequin to course of extra info inside the identical context window, resulting in extra coherent and contextually related outputs.
Licensing and Availability
Mistral Massive 2 and Mistral NeMo have totally different licensing fashions, reflecting their meant use circumstances:
Mistral Massive 2
- Launched below the Mistral Analysis License
- Permits utilization and modification for analysis and non-commercial functions
- Business utilization requires a Mistral Business License
Mistral NeMo
- Launched below the Apache 2.0 license
- Permits for open use, together with business purposes
Each fashions can be found by way of varied platforms:
- Hugging Face: Weights for each base and instruct fashions are hosted right here
- Mistral AI: Obtainable as
mistral-large-2407(Mistral Massive 2) andopen-mistral-nemo-2407(Mistral NeMo) - Cloud Service Suppliers: Obtainable on Google Cloud Platform’s Vertex AI, Azure AI Studio, Amazon Bedrock, and IBM watsonx.ai

https://mistral.ai/information/mistral-large-2407/
For builders wanting to make use of these fashions, here is a fast instance of how you can load and use Mistral Massive 2 with Hugging Face transformers:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "mistralai/Mistral-Massive-Instruct-2407"
machine = "cuda" # Use GPU if obtainable
# Load the mannequin and tokenizer
mannequin = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Transfer the mannequin to the suitable machine
mannequin.to(machine)
# Put together enter
messages = [
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": "Explain the concept of neural networks in simple terms."}
]
# Encode enter
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to(machine)
# Generate response
output_ids = mannequin.generate(input_ids, max_new_tokens=500, do_sample=True)
# Decode and print the response
response = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(response)
This code demonstrates how you can load the mannequin, put together enter in a chat format, generate a response, and decode the output.

