
Are you able to deliver extra consciousness to your model? Contemplate turning into a sponsor for The AI Affect Tour. Be taught extra in regards to the alternatives here.
Scientists at the University of California, Berkeley have developed a novel machine studying (ML) methodology, termed “reinforcement learning via intervention feedback” (RLIF), that may make it simpler to coach AI techniques for complicated environments.
RLIF merges reinforcement studying with interactive imitation studying, two necessary strategies usually utilized in coaching synthetic intelligence techniques. RLIF will be helpful in settings the place a reward sign will not be available and human suggestions will not be very exact, which occurs usually in coaching AI techniques for robotics.
Reinforcement studying and imitation studying
Reinforcement studying is beneficial in environments the place exact reward capabilities can information the educational course of. It’s significantly efficient in optimum management eventualities, gaming and aligning giant language fashions (LLMs) with human preferences, the place the objectives and rewards are clearly outlined. Robotics issues, with their complicated goals and the absence of express reward indicators, pose a big problem for conventional RL strategies.
In such intricate settings, engineers usually pivot to imitation studying, a department of supervised studying. This system bypasses the necessity for reward indicators by coaching fashions utilizing demonstrations from people or different brokers. As an illustration, a human operator would possibly information a robotic arm in manipulating an object, offering a visible and sensible instance for the AI to emulate. The agent then treats these human-led demonstrations as coaching examples.
Regardless of its benefits, imitation studying will not be with out its pitfalls. A notable concern is the “distribution mismatch drawback,” the place an agent could encounter conditions exterior the scope of its coaching demonstrations, resulting in a decline in efficiency. “Interactive imitation studying” mitigates this drawback by having specialists present real-time suggestions to refine the agent’s habits after coaching. This methodology includes a human knowledgeable monitoring the agent’s coverage in motion and stepping in with corrective demonstrations each time the agent strays from the specified habits.
Nonetheless, interactive imitation studying hinges on near-optimal interventions, which aren’t all the time obtainable. Particularly in robotics, human enter will not be exact sufficient for these strategies to be absolutely efficient.
Combining reinforcement studying and imitation studying
Of their research, the U.C. Berkeley scientists discover a hybrid method that leverages the strengths of reinforcement studying and interactive imitation studying. Their methodology, RLIF, relies on a easy perception: it’s usually simpler to acknowledge errors than to execute flawless corrections.
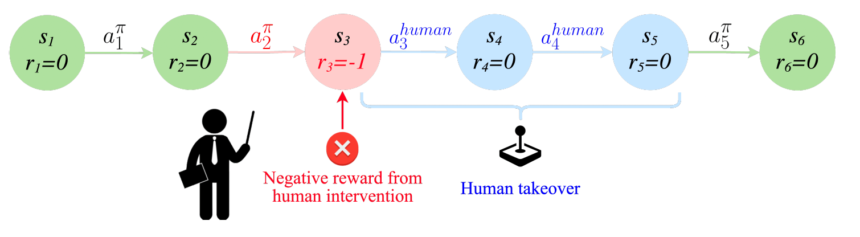
This idea is especially related in complicated duties like autonomous driving, the place a security driver’s intervention—similar to slamming on the brakes to stop a collision—indicators a deviation from desired habits, however doesn’t essentially mannequin the optimum response. The RL agent shouldn’t be taught to mimic the sudden braking motion however be taught to keep away from the state of affairs that prompted the driving force to brake.
“The choice to intervene throughout an interactive imitation episode itself can present a reward sign for reinforcement studying, permitting us to instantiate RL strategies that function below related however doubtlessly weaker assumptions as interactive imitation strategies, studying from human interventions however not assuming that such interventions are optimum,” the researchers clarify.
Like interactive imitation studying, RLIF trains the agent via a sequence of demonstrations adopted by interactive interventions. Nonetheless, it doesn’t assume that the interventions by human specialists are optimum. It merely treats the intervention as a sign that the AI’s coverage is about to take a fallacious flip and trains the system to keep away from the state of affairs that makes the intervention vital.

RLIF combines reinforcement studying and intervention indicators from human specialists (supply: arxiv)
“Intuitively we assume that the knowledgeable is extra prone to intervene when [the trained policy] takes a foul motion. This in precept can present an RL algorithm with a sign to change its habits, because it means that the steps main as much as this intervention deviated considerably from optimum habits,” the researchers reported.
RLIF addresses the constraints inherent in each pure reinforcement studying and interactive imitation studying, together with the necessity for a exact reward perform and optimum interventions. This makes it extra sensible to make use of it in complicated environments.
“Intuitively, we count on it to be much less of a burden for specialists to solely level out which states are undesirable relatively than truly act optimally in these states,” the researchers famous.
Testing RLIF
The U.C. Berkeley group put RLIF to the take a look at in opposition to DAgger, a extensively used interactive imitation studying algorithm. In experiments on simulated environments, RLIF outperformed one of the best DAgger variants by an element of two to 3 instances on common. Notably, this efficiency hole widened to 5 instances in eventualities the place the standard of knowledgeable interventions was suboptimal.

RLIF in motion on bodily robots (supply: arxiv)
The group additionally examined RLIF in real-world robotic challenges, similar to object manipulation and fabric folding with precise human suggestions. These exams confirmed that RLIF can also be sturdy and relevant in real-world eventualities.
RLIF has a couple of challenges, similar to important knowledge necessities and the complexities of on-line deployment. Sure purposes may additionally not tolerate suboptimal interventions and explicitly require oversight by extremely skilled specialists. Nonetheless, with its sensible use circumstances, RLIF can grow to be an necessary instrument for coaching many real-world robotic techniques.