
Giant Language Fashions (LLMs) deploying on real-world functions presents distinctive challenges, significantly when it comes to computational assets, latency, and cost-effectiveness. On this complete information, we’ll discover the panorama of LLM serving, with a selected give attention to vLLM (vector Language Mannequin), an answer that is reshaping the way in which we deploy and work together with these highly effective fashions.
The Challenges of Serving Giant Language Fashions
Earlier than diving into particular options, let’s look at the important thing challenges that make LLM serving a posh activity:
Computational Sources
LLMs are infamous for his or her huge parameter counts, starting from billions to a whole lot of billions. As an example, GPT-3 boasts 175 billion parameters, whereas newer fashions like GPT-4 are estimated to have much more. This sheer dimension interprets to important computational necessities for inference.
Instance:
Contemplate a comparatively modest LLM with 13 billion parameters, similar to LLaMA-13B. Even this mannequin requires:
– Roughly 26 GB of reminiscence simply to retailer the mannequin parameters (assuming 16-bit precision)
– Further reminiscence for activations, consideration mechanisms, and intermediate computations
– Substantial GPU compute energy for real-time inference
Latency
In lots of functions, similar to chatbots or real-time content material technology, low latency is essential for person expertise. Nonetheless, the complexity of LLMs can result in important processing instances, particularly for longer sequences.
Instance:
Think about a customer support chatbot powered by an LLM. If every response takes a number of seconds to generate, the dialog will really feel unnatural and irritating for customers.
Value
The {hardware} required to run LLMs at scale may be extraordinarily costly. Excessive-end GPUs or TPUs are sometimes mandatory, and the vitality consumption of those methods is substantial.
Instance:
Operating a cluster of NVIDIA A100 GPUs (usually used for LLM inference) can price hundreds of {dollars} per day in cloud computing charges.
Conventional Approaches to LLM Serving
Earlier than exploring extra superior options, let’s briefly overview some conventional approaches to serving LLMs:
Easy Deployment with Hugging Face Transformers
The Hugging Face Transformers library gives a simple technique to deploy LLMs, however it’s not optimized for high-throughput serving.
Instance code:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "meta-llama/Llama-2-13b-hf"
mannequin = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
def generate_text(immediate, max_length=100):
inputs = tokenizer(immediate, return_tensors="pt").to(mannequin.system)
outputs = mannequin.generate(**inputs, max_length=max_length)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generate_text("The way forward for AI is"))
Whereas this strategy works, it is not appropriate for high-traffic functions as a result of its inefficient use of assets and lack of optimizations for serving.
Utilizing TorchServe or Related Frameworks
Frameworks like TorchServe present extra sturdy serving capabilities, together with load balancing and mannequin versioning. Nonetheless, they nonetheless do not tackle the particular challenges of LLM serving, similar to environment friendly reminiscence administration for giant fashions.
Understanding Reminiscence Administration in LLM Serving
Environment friendly reminiscence administration is essential for serving giant language fashions (LLMs) because of the intensive computational assets required. The next pictures illustrate varied features of reminiscence administration, that are integral to optimizing LLM efficiency.
Segmented vs. Paged Reminiscence
These two diagrams examine segmented reminiscence and paged reminiscence administration methods, generally utilized in working methods (OS).
- Segmented Reminiscence: This system divides reminiscence into totally different segments, every equivalent to a special program or course of. As an example, in an LLM serving context, totally different segments is likely to be allotted to numerous parts of the mannequin, similar to tokenization, embedding, and a focus mechanisms. Every phase can develop or shrink independently, offering flexibility however doubtlessly resulting in fragmentation if segments usually are not managed correctly.
- Paged Reminiscence: Right here, reminiscence is split into fixed-size pages, that are mapped onto bodily reminiscence. Pages may be swapped out and in as wanted, permitting for environment friendly use of reminiscence assets. In LLM serving, this may be essential for managing the big quantities of reminiscence required for storing mannequin weights and intermediate computations.
Reminiscence Administration in OS vs. vLLM
This picture contrasts conventional OS reminiscence administration with the reminiscence administration strategy utilized in vLLM.
- OS Reminiscence Administration: In conventional working methods, processes (e.g., Course of A and Course of B) are allotted pages of reminiscence (Web page 0, Web page 1, and many others.) in bodily reminiscence. This allocation can result in fragmentation over time as processes request and launch reminiscence.
- vLLM Reminiscence Administration: The vLLM framework makes use of a Key-Worth (KV) cache to handle reminiscence extra effectively. Requests (e.g., Request A and Request B) are allotted blocks of the KV cache (KV Block 0, KV Block 1, and many others.). This strategy helps decrease fragmentation and optimizes reminiscence utilization, permitting for quicker and extra environment friendly mannequin serving.
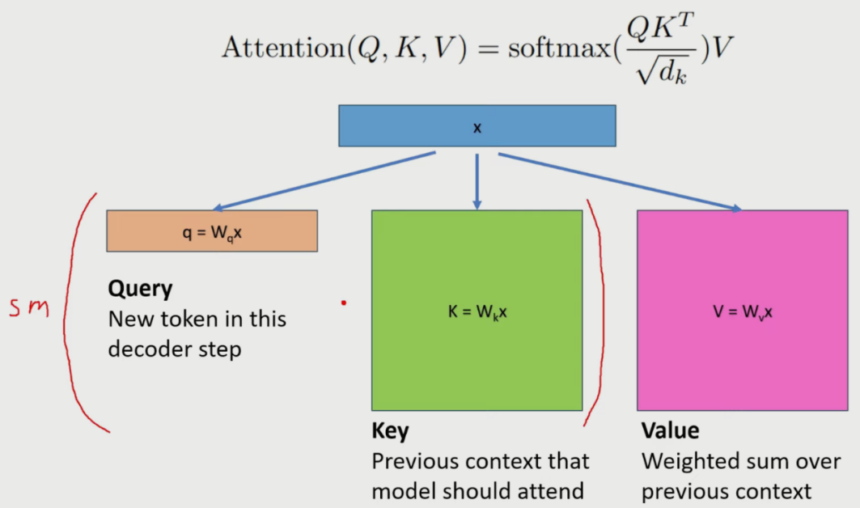
Consideration Mechanism in LLMs

Consideration Mechanism in LLMs
The eye mechanism is a basic part of transformer fashions, that are generally used for LLMs. This diagram illustrates the eye method and its parts:
- Question (Q): A brand new token within the decoder step or the final token that the mannequin has seen.
- Key (Okay): Earlier context that the mannequin ought to attend to.
- Worth (V): Weighted sum over the earlier context.
The method calculates the eye scores by taking the dot product of the question with the keys, scaling by the sq. root of the important thing dimension, making use of a softmax perform, and at last taking the dot product with the values. This course of permits the mannequin to give attention to related elements of the enter sequence when producing every token.
Serving Throughput Comparability

This picture presents a comparability of serving throughput between totally different frameworks (HF, TGI, and vLLM) utilizing LLaMA fashions on totally different {hardware} setups.
- LLaMA-13B, A100-40GB: vLLM achieves 14x – 24x greater throughput than HuggingFace Transformers (HF) and a pair of.2x – 2.5x greater throughput than HuggingFace Textual content Era Inference (TGI).
- LLaMA-7B, A10G: Related developments are noticed, with vLLM considerably outperforming each HF and TGI.
vLLM: A New LLM Serving Structure
vLLM, developed by researchers at UC Berkeley, represents a major leap ahead in LLM serving know-how. Let’s discover its key options and improvements:
PagedAttention
On the coronary heart of vLLM lies PagedAttention, a novel consideration algorithm impressed by digital reminiscence administration in working methods. Here is the way it works:
– Key-Worth (KV) Cache Partitioning: As an alternative of storing all the KV cache contiguously in reminiscence, PagedAttention divides it into fixed-size blocks.
– Non-Contiguous Storage: These blocks may be saved non-contiguously in reminiscence, permitting for extra versatile reminiscence administration.
– On-Demand Allocation: Blocks are allotted solely when wanted, decreasing reminiscence waste.
– Environment friendly Sharing: A number of sequences can share blocks, enabling optimizations for methods like parallel sampling and beam search.
Illustration:
“`
Conventional KV Cache:
[Token 1 KV][Token 2 KV][Token 3 KV]…[Token N KV]
(Contiguous reminiscence allocation)
PagedAttention KV Cache:
[Block 1] -> Bodily Deal with A
[Block 2] -> Bodily Deal with C
[Block 3] -> Bodily Deal with B
…
(Non-contiguous reminiscence allocation)
“`
This strategy considerably reduces reminiscence fragmentation and permits for far more environment friendly use of GPU reminiscence.
Steady Batching
vLLM implements steady batching, which dynamically processes requests as they arrive, moderately than ready to type fixed-size batches. This results in decrease latency and better throughput.
Instance:
Think about a stream of incoming requests:
“`
Time 0ms: Request A arrives
Time 10ms: Begin processing Request A
Time 15ms: Request B arrives
Time 20ms: Begin processing Request B (in parallel with A)
Time 25ms: Request C arrives
…
“`
With steady batching, vLLM can begin processing every request instantly, moderately than ready to group them into predefined batches.
Environment friendly Parallel Sampling
For functions that require a number of output samples per immediate (e.g., artistic writing assistants), vLLM’s reminiscence sharing capabilities shine. It may generate a number of outputs whereas reusing the KV cache for shared prefixes.
Instance code utilizing vLLM:
from vllm import LLM, SamplingParams
llm = LLM(mannequin="meta-llama/Llama-2-13b-hf")
prompts = ["The future of AI is"]
# Generate 3 samples per immediate
sampling_params = SamplingParams(n=3, temperature=0.8, max_tokens=100)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
print(f"Immediate: {output.immediate}")
for i, out in enumerate(output.outputs):
print(f"Pattern {i + 1}: {out.textual content}")
This code effectively generates a number of samples for the given immediate, leveraging vLLM’s optimizations.
Benchmarking vLLM Efficiency
To really admire the affect of vLLM, let us take a look at some efficiency comparisons:
Throughput Comparability
Based mostly on the data supplied, vLLM considerably outperforms different serving options:
– As much as 24x greater throughput in comparison with Hugging Face Transformers
– 2.2x to three.5x greater throughput than Hugging Face Textual content Era Inference (TGI)
Illustration:
“`
Throughput (Tokens/second)
|
| ****
| ****
| ****
| **** ****
| **** **** ****
| **** **** ****
|————————
HF TGI vLLM
“`
Reminiscence Effectivity
vLLM’s PagedAttention leads to near-optimal reminiscence utilization:
– Solely about 4% reminiscence waste, in comparison with 60-80% in conventional methods
– This effectivity permits for serving bigger fashions or dealing with extra concurrent requests with the identical {hardware}
Getting Began with vLLM
Now that we have explored the advantages of vLLM, let’s stroll by the method of setting it up and utilizing it in your initiatives.
6.1 Set up
Putting in vLLM is simple utilizing pip:
!pip set up vllm
6.2 Fundamental Utilization for Offline Inference
Here is a easy instance of utilizing vLLM for offline textual content technology:
from vllm import LLM, SamplingParams
# Initialize the mannequin
llm = LLM(mannequin="meta-llama/Llama-2-13b-hf")
# Put together prompts
prompts = [
"Write a short poem about artificial intelligence:",
"Explain quantum computing in simple terms:"
]
# Set sampling parameters
sampling_params = SamplingParams(temperature=0.8, max_tokens=100)
# Generate responses
outputs = llm.generate(prompts, sampling_params)
# Print the outcomes
for output in outputs:
print(f"Immediate: {output.immediate}")
print(f"Generated textual content: {output.outputs[0].textual content}n")
This script demonstrates how you can load a mannequin, set sampling parameters, and generate textual content for a number of prompts.
6.3 Setting Up a vLLM Server
For on-line serving, vLLM gives an OpenAI-compatible API server. Here is how you can set it up:
1. Begin the server:
python -m vllm.entrypoints.openai.api_server --model meta-llama/Llama-2-13b-hf
2. Question the server utilizing curl:
curl http://localhost:8000/v1/completions
-H "Content material-Kind: utility/json"
-d '{
"mannequin": "meta-llama/Llama-2-13b-hf",
"immediate": "The advantages of synthetic intelligence embrace:",
"max_tokens": 100,
"temperature": 0.7
}'
This setup means that you can serve your LLM with an interface suitable with OpenAI’s API, making it simple to combine into current functions.
Superior Subjects on vLLM
Whereas vLLM presents important enhancements in LLM serving, there are extra concerns and superior subjects to discover:
7.1 Mannequin Quantization
For much more environment friendly serving, particularly on {hardware} with restricted reminiscence, quantization methods may be employed. Whereas vLLM itself does not at present help quantization, it may be used along with quantized fashions:
from transformers import AutoModelForCausalLM, AutoTokenizer import torch # Load a quantized mannequin model_name = "meta-llama/Llama-2-13b-hf" mannequin = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True) tokenizer = AutoTokenizer.from_pretrained(model_name) # Use the quantized mannequin with vLLM from vllm import LLM llm = LLM(mannequin=mannequin, tokenizer=tokenizer)
7.2 Distributed Inference
For terribly giant fashions or high-traffic functions, distributed inference throughout a number of GPUs or machines could also be mandatory. Whereas vLLM does not natively help this, it may be built-in into distributed methods utilizing frameworks like Ray:
import ray
from vllm import LLM
@ray.distant(num_gpus=1)
class DistributedLLM:
def __init__(self, model_name):
self.llm = LLM(mannequin=model_name)
def generate(self, immediate, params):
return self.llm.generate(immediate, params)
# Initialize distributed LLMs
llm1 = DistributedLLM.distant("meta-llama/Llama-2-13b-hf")
llm2 = DistributedLLM.distant("meta-llama/Llama-2-13b-hf")
# Use them in parallel
result1 = llm1.generate.distant("Immediate 1", sampling_params)
result2 = llm2.generate.distant("Immediate 2", sampling_params)
# Retrieve outcomes
print(ray.get([result1, result2]))
7.3 Monitoring and Observability
When serving LLMs in manufacturing, monitoring is essential. Whereas vLLM does not present built-in monitoring, you possibly can combine it with instruments like Prometheus and Grafana:
from prometheus_client import start_http_server, Abstract
from vllm import LLM
# Outline metrics
REQUEST_TIME = Abstract('request_processing_seconds', 'Time spent processing request')
# Initialize vLLM
llm = LLM(mannequin="meta-llama/Llama-2-13b-hf")
# Expose metrics
start_http_server(8000)
# Use the mannequin with monitoring
@REQUEST_TIME.time()
def process_request(immediate):
return llm.generate(immediate)
# Your serving loop right here
This setup means that you can observe metrics like request processing time, which may be visualized in Grafana dashboards.
Conclusion
Serving Giant Language Fashions effectively is a posh however essential activity within the age of AI. vLLM, with its modern PagedAttention algorithm and optimized implementation, represents a major step ahead in making LLM deployment extra accessible and cost-effective.
By dramatically enhancing throughput, decreasing reminiscence waste, and enabling extra versatile serving choices, vLLM opens up new potentialities for integrating highly effective language fashions into a variety of functions. Whether or not you are constructing a chatbot, a content material technology system, or some other NLP-powered utility, understanding and leveraging instruments like vLLM will likely be key to success.

