

At NVIDIA GTC25, Gnani.ai specialists unveiled groundbreaking developments in voice AI, specializing in the event and deployment of Speech-to-Speech Basis Fashions. This progressive strategy guarantees to beat the restrictions of conventional cascaded voice AI architectures, ushering in an period of seamless, multilingual, and emotionally conscious voice interactions.
The Limitations of Cascaded Architectures
Present state-of-the-art structure powering voice brokers entails a three-stage pipeline: Speech-to-Textual content (STT), Massive Language Fashions (LLMs), and Textual content-to-Speech (TTS). Whereas efficient, this cascaded structure suffers from vital drawbacks, primarily latency and error propagation. A cascaded structure has a number of blocks within the pipeline, and every block will add its personal latency. The cumulative latency throughout these levels can vary from 2.5 to three seconds, resulting in a poor consumer expertise. Furthermore, errors launched within the STT stage propagate by means of the pipeline, compounding inaccuracies. This conventional structure additionally loses essential paralinguistic options equivalent to sentiment, emotion, and tone, leading to monotonous and emotionally flat responses.
Introducing Speech-to-Speech Basis Fashions
To handle these limitations, Gnani.ai presents a novel Speech-to-Speech Basis Mannequin. This mannequin instantly processes and generates audio, eliminating the necessity for intermediate textual content representations. The important thing innovation lies in coaching a large audio encoder with 1.5 million hours of labeled knowledge throughout 14 languages, capturing nuances of emotion, empathy, and tonality. This mannequin employs a nested XL encoder, retrained with complete knowledge, and an enter audio projector layer to map audio options into textual embeddings. For real-time streaming, audio and textual content options are interleaved, whereas non-streaming use circumstances make the most of an embedding merge layer. The LLM layer, initially primarily based on Llama 8B, was expanded to incorporate 14 languages, necessitating the rebuilding of tokenizers. An output projector mannequin generates mel spectrograms, enabling the creation of hyper-personalized voices.
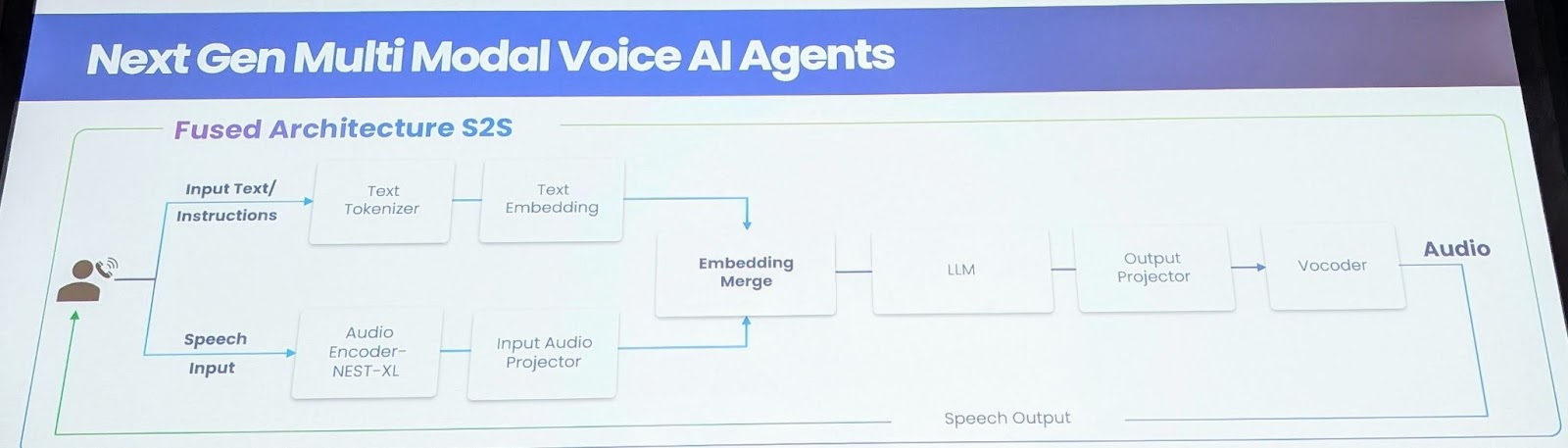
Key Advantages and Technical Hurdles
The Speech-to-Speech mannequin affords a number of vital advantages. Firstly, it considerably reduces latency, shifting from 2 seconds to roughly 850-900 milliseconds for the primary token output. Secondly, it enhances accuracy by fusing ASR with the LLM layer, bettering efficiency, particularly for brief and lengthy speeches. Thirdly, the mannequin achieves emotional consciousness by capturing and modeling tonality, stress, and fee of speech. Fourthly, it permits improved interruption dealing with by means of contextual consciousness, facilitating extra pure interactions. Lastly, the mannequin is designed to deal with low bandwidth audio successfully, which is essential for telephony networks. Constructing this mannequin introduced a number of challenges, notably the huge knowledge necessities. The crew created a crowd-sourced system with 4 million customers to generate emotionally wealthy conversational knowledge. In addition they leveraged basis fashions for artificial knowledge technology and educated on 13.5 million hours of publicly accessible knowledge. The ultimate mannequin contains a 9 billion parameter mannequin, with 636 million for the audio enter, 8 billion for the LLM, and 300 million for the TTS system.
NVIDIA’s Function in Improvement
The event of this mannequin was closely reliant on the NVIDIA stack. NVIDIA Nemo was used for coaching encoder-decoder fashions, and NeMo Curator facilitated artificial textual content knowledge technology. NVIDIA EVA was employed to generate audio pairs, combining proprietary data with artificial knowledge.
Use Instances
Gnani.ai showcased two major use circumstances: real-time language translation and buyer assist. The true-time language translation demo featured an AI engine facilitating a dialog between an English-speaking agent and a French-speaking buyer. The shopper assist demo highlighted the mannequin’s means to deal with cross-lingual conversations, interruptions, and emotional nuances.
Speech-to-Speech Basis Mannequin
The Speech-to-Speech Basis Mannequin represents a major leap ahead in voice AI. By eliminating the restrictions of conventional architectures, this mannequin permits extra pure, environment friendly, and emotionally conscious voice interactions. Because the know-how continues to evolve, it guarantees to rework varied industries, from customer support to international communication.
https://t.me/s/pt1win/340
Актуальные рейтинги лицензионных онлайн-казино по выплатам, бонусам, минимальным депозитам и крипте — без воды и купленной мишуры. Только площадки, которые проходят живой отбор по деньгам, условиям и опыту игроков.
Следить за обновлениями можно здесь: https://t.me/s/reitingcasino
https://t.me/s/iGaming_live/4580
https://t.me/s/iGaming_live/4697
https://t.me/reyting_topcazino/14
Hơn 1.000+ kèo cược thể thao tốt nhất thị trường sở hữu tỷ lệ thưởng cạnh tranh đang được 3 NPH Sportsbook cập nhật mỗi ngày tại tải 188v. Bạn có thể thử sức với 40+ bộ môn khác nhau như: Bóng đá, bóng rổ, bóng chuyền, khúc côn cầu, Boxing, võ tổng hợp MMA,…
xn88 game chính là địa điểm dừng chân lý tưởng, thiên đường giải trí xanh chín đáp ứng đầy đủ tiêu chí anh em không nên bỏ qua. Với sự đa dạng, sức hút và sự cam kết về chất lượng, nhà cái hàng đầu Fun 88 hứa hẹn mang tới cho bạn những trải nghiệm đỉnh cao tuyệt vời cùng cơ hội làm giàu nhanh chóng.
https://t.me/of_1xbet/920
Với ba tiêu chí phát triển là “Công bằng – Công khai – Hợp pháp”, slot365 login hứa hẹn sẽ mang tới cho bạn những trải nghiệm giải trí tuyệt đỉnh. Đăng ký hội viên mới, tân thủ không chỉ được thưởng lớn 100% tiền gửi lần đầu, mà còn có cơ hội “đầu tư kiếm lời” với tỷ lệ cược lô đề 1 ăn 99.8 độc quyền hiện nay.
https://t.me/s/ef_beef
Well I truly enjoyed reading it. This article offered by you is very helpful for proper planning.
I was just looking for this information for a while. After 6 hours of continuous Googleing, at last I got it in your site. I wonder what’s the lack of Google strategy that do not rank this kind of informative websites in top of the list. Generally the top web sites are full of garbage.
https://t.me/s/officials_pokerdom/3273
werken bij holland casino
References:
http://www.thedreammate.com/home/bbs/board.php?bo_table=free&wr_id=5004102
slot365 apk Trên các bảng xếp hạng uy tín như AskGamblers và iGamingTracker, nhà cái thường xuyên góp mặt trong danh sách những nhà cái có tỷ lệ giữ chân người chơi cao nhất.
https://t.me/dragon_money_mani/18
Very interesting points you have remarked, regards for putting up. “Curiosity is the key to creativity.” by Akio Morita.
fantastic post.Ne’er knew this, regards for letting me know.
I’m truly enjoying the design and layout of your blog. It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a designer to create your theme? Exceptional work!
Looking for a yacht? corporate yacht events in Cyprus for unforgettable sea adventures. Charter luxury yachts, catamarans, or motorboats with or without crew. Explore crystal-clear waters, secluded bays, and iconic coastal locations in first-class comfort onboard.
услуга грузчиков грузчика найти
заказ грузчиков недорого стоимость услуг грузчиков
сколько стоит газоблок газоблоки за штуку
Google Salaries https://salarydatahub.uk by Role (US & UK) – Real Pay Ranges, Levels, and Total Compensation
краны шаровые приварные приварной кран
The most useful for you: site here
Looking for a yacht? family boat rental Cyprus for unforgettable sea adventures. Charter luxury yachts, catamarans, or motorboats with or without crew. Explore crystal-clear waters, secluded bays, and iconic coastal locations in first-class comfort onboard.
мобильные стойки ограждения столбики ограждения с лентой купить
магазин кабель проводка купить
купить красивое свадебное платье https://svadebnye-platya-msk.ru
Looking for a casino? https://pinupturkiye.org is a licensed online casino with a wide selection of slots, live dealer games, and sports betting. New players can take advantage of a welcome bonus and regular promotions; deposits and withdrawals are available through popular methods. The site supports responsible gaming and offers customer support in multiple languages. Pinup Casino is suitable for players who prefer a user-friendly interface and a wide range of entertainment options.
ремонт квартир під ключ вартість ремонту квартири
Онлайн-журнал https://tga-info.ru со статьями обо всём: от технологий и финансов до психологии, бизнеса и лайфхаков. Читайте полезные материалы, обзоры, аналитические статьи и практические рекомендации для работы, обучения и повседневной жизни.
Строительный портал https://nesmetnoe.ru с полезными статьями о строительстве домов, ремонте квартир, выборе материалов и современных технологиях. Советы специалистов, инструкции, обзоры инструментов, идеи для интерьера и практические решения для частного и коммерческого строительства.
Онлайн-блог https://lifeoflove.ru о семейной жизни, психологии любви и гармоничных отношениях. Читайте статьи о доверии, понимании, воспитании детей, романтике и совместном досуге. Полезные советы и вдохновение для счастливой семейной жизни.
Интернет-журнал https://greendachnik.ru о садоводстве, огороде и ландшафтном дизайне. Полезные статьи о выращивании овощей, фруктов и цветов, уходе за растениями, планировании участка и создании красивого сада. Советы садоводов, идеи оформления и практические рекомендации.
Новости IT https://hardexpert.net и компьютерного мира: новинки технологий, программное обеспечение, гаджеты, компьютерные комплектующие и цифровые сервисы. Обзоры, аналитика, обновления программ и последние события в мире технологий.
Автомобильный портал https://hyundai-sto.ru со статьями обо всем, что связано с машинами. Новости автопрома, обзоры автомобилей, советы по выбору, ремонту и обслуживанию, сравнения моделей, технологии и полезная информация для водителей и автолюбителей.
Женский сайт https://allsekrets.ru о красоте, моде, здоровье и отношениях. Полезные статьи о стиле, уходе за собой, психологии, семейной жизни и саморазвитии. Советы, идеи и вдохновение для современной женщины, которая хочет выглядеть красиво и чувствовать гармонию.
Женский портал https://idealnaya-ya.ru о красоте, моде, здоровье и гармоничной жизни. Читайте статьи о стиле, отношениях, психологии, воспитании детей, саморазвитии и уходе за собой. Полезные советы, вдохновение и идеи для счастливой жизни.
Все о стройке https://dobdom.ru и ремонте: полезные статьи о строительстве домов, ремонте квартир, отделке помещений и выборе материалов. Советы специалистов, инструкции, идеи для интерьера и практические рекомендации по строительству и благоустройству жилья.
Портал о стройке https://profsmeta3dn.ru и ремонте: строительство домов, ремонт квартир, отделка помещений и современные строительные технологии. Полезные советы мастеров, обзоры материалов и инструмента, инструкции и идеи для ремонта и благоустройства жилья.
Found a bride? wedding proposal in Barcelona romantic scenarios, beautiful locations, photo shoots, decor, and surprises for the perfect declaration of love. Make your engagement in Barcelona an unforgettable moment in your story.
Нужен юрист? адвокат в арбитражном процессе представительство в арбитражном суде, защита интересов бизнеса, взыскание задолженности, споры по договорам и сопровождение судебных процессов для компаний и предпринимателей.
Ищешь кран? шаровые краны под приварку для трубопроводов различного назначения. Надежная запорная арматура для систем водоснабжения, отопления, газа и промышленных магистралей. Высокая герметичность, долговечность и устойчивость к нагрузкам.
интернет магазин парфюмерии https://aroma-lavka.ru/
Круглогодичный прокат авто Сочи https://avto-arenda-sochi.ru
монро казино промокод casino monro
SEO-продвижение https://outreachseo.ru сайта для роста посещаемости и увеличения продаж. Проводим аудит, оптимизацию структуры, работу с контентом и техническими параметрами сайта, чтобы улучшить позиции в поисковых системах и привлечь целевой трафик.
Профессиональное SEO-продвижение https://outreachseo.ru сайтов для бизнеса. Анализ конкурентов, оптимизация структуры и контента, улучшение технических параметров и развитие сайта для роста позиций в поисковых системах и увеличения целевого трафика.
Explore detailed insights on buckingham fancy metal table clocks at TopXClocks, including features, comparisons, and expert recommendations for smarter buying decisions.
купить золотое кольцо помолвочное кольцо
Curious about the weather weather in Podgorica in March today. Detailed 7- and 10-day forecasts, including temperature, wind, precipitation, humidity, and pressure. Up-to-date information on the climate and weather conditions in Podgorica for travel and leisure.
Если вам нравится “жёсткий” стиль, высокая волатильность и слоты, где решают механики и бонусные режимы, то Nolimit City – это провайдер, за которым стоит следить. В нашем Telegram мы собираем всё по NLC в одном месте: подборки самых хайповых тайтлов, разборы фич (xNudge/xWays и прочие фирменные механики), что лучше пробовать под спокойную игру, а что – чисто “на разнос”. Плюс регулярно публикуем новинки и заметки, чтобы вы не пропускали свежие релизы (у них они выходят стабильно).
Свежие проекты часто заходят с “громких” бонусов и яркого дизайна, но по факту важнее другое: как быстро проходят выплаты, какие лимиты, насколько адекватная поддержка и нет ли скрытых условий в правилах. Если вас интересуют новые онлайн казино, мы собрали в Telegram удобный формат: короткие подборки, что реально запустилось недавно, что сейчас стабильно работает, и где условия выглядят честно без лишней “маркетинговой пыли”. Это помогает не тратить вечер на десятки сайтов и сразу понимать, куда есть смысл заходить, а что лучше обойти.
Информационный портал https://tga-info.ru со статьями и обзорами на разные темы. Материалы о технологиях жизни работе доме и повседневных вопросах. Актуальные новости полезные советы рекомендации и интересная информация для читателей.
Интернет ресурс https://nesmetnoe.ru с полезными статьями советами и обзорами. Материалы о жизни здоровье технологиях доме и повседневных вопросах. Практические рекомендации интересные факты и актуальная информация для широкой аудитории.
Статьи о любви http://www.lifeoflove.ru отношениях, психологии и семейной жизни. Советы по гармоничным отношениям общению и саморазвитию. Полезные рекомендации вдохновляющие истории и материалы для тех кто хочет улучшить личную жизнь.
Полезные материалы https://greendachnik.ru для дачников и садоводов. Советы по выращиванию овощей цветов и плодовых растений уходу за садом огородом и участком. Практические рекомендации идеи для дачи и комфортной загородной жизни.
Материалы о компьютерах https://hardexpert.net технологиях электронике и IT. Обзоры техники советы по выбору комплектующих настройке программ и использованию устройств. Полезная информация для пользователей и любителей технологий.
Сборник полезных советов https://allsekrets.ru и лайфхаков на каждый день. Материалы о доме здоровье красоте и повседневной жизни. Интересные статьи практические рекомендации и идеи которые помогут упростить бытовые задачи.
Информация о ремонте http://www.hyundai-sto.ru обслуживании и диагностике автомобилей Hyundai. Советы по техническому обслуживанию выбору запчастей и эксплуатации автомобиля. Полезные материалы для владельцев и автолюбителей.
Материалы о красоте http://www.idealnaya-ya.ru/ здоровье саморазвитии и уходе за собой. Советы по питанию фитнесу психологии и гармоничной жизни. Полезные статьи рекомендации и идеи для улучшения самочувствия и образа жизни.
Интересуют новости? новостной портал главные новости дня на одном портале. Свежие события из политики, экономики, общества, технологий и культуры. Оперативная информация, аналитика, комментарии экспертов и важные факты, которые помогают понимать происходящее.
Лучшие сервера рейтинг выделенных серверов сравнение dedicated servers по цене, производительности и надежности. Рейтинг хостингов, которые предлагают мощные серверные решения.
Найти лучший сервер подобрать VPS рейтинг dedicated servers от популярных хостинг-провайдеров. Сравните выделенные серверы по характеристикам, стоимости и возможностям масштабирования для бизнеса и веб-проектов.
Нужен сервер? VPS/VDS-хостинг dedicated servers с мощными процессорами, NVMe SSD и высокой стабильностью. Подберите оптимальный сервер для бизнеса, разработки и высоких нагрузок.
Ищешь сервер? VPS хостниг сравнение dedicated server хостинга по характеристикам, цене, производительности и uptime. Лучшие провайдеры для размещения сайтов, интернет-магазинов и крупных проектов.
Рейтинги серверов VPS/VDS-хостинг актуальный рейтинг dedicated server хостинга с сравнением характеристик, стоимости и производительности. Найдите оптимальный сервер для бизнеса, интернет-магазина, SaaS-сервисов и крупных сайтов.
Обзор и рейтинги серверов подобрать VPS сравните выделенные серверы по характеристикам, цене, процессорам и дискам SSD. Выберите надежный сервер для размещения сайтов, приложений и высоких нагрузок.
Проблемы с алкоголем? платный нарколог на дом медицинская помощь при алкогольной зависимости, детоксикация организма и восстановление самочувствия. Консультации специалистов и безопасное лечение.
Гарантированное лечение платный наркологический центр специалист приезжает к пациенту, проводит детоксикацию организма, помогает снять симптомы алкогольной интоксикации и контролирует состояние. Безопасный и конфиденциальный подход.
Профессиональный вывод из запоя с выездом детоксикация организма, помощь при алкогольной интоксикации и восстановление самочувствия пациента. Специалист приезжает на дом и оказывает профессиональную помощь.
Круглосуточный вывод из запоя алкоголиков специалист проводит детоксикацию организма, помогает снять симптомы алкогольной интоксикации и контролирует состояние пациента. Медицинская помощь оказывается конфиденциально и направлена на быстрое восстановление самочувствия.
Гарантированный безопасный лечение запоя капельницами вывод из запоя с наблюдением, детоксикацией организма и поддержкой врача. Процедуры направлены на восстановление состояния пациента и улучшение самочувствия.
Качественное SEO https://outreachseo.ru продвижение сайта для бизнеса. Наши специалисты предлагают эффективные решения для роста позиций в поисковых системах. Подробнее об услугах и стратегиях можно узнать на сайте
Reliable source facebook ad profiles connects advertisers with thoroughly vetted profiles backed by replacement guarantees and dedicated support. The team provides onboarding guidance for new buyers and ongoing operational support for teams managing high-volume campaign portfolios. Professional media buying starts with professional tools — source from a marketplace built by advertisers, for advertisers.
Wholesale supplier facebook accounts cheap enables teams to source diverse account portfolios across platforms and geos from a single centralized marketplace. Cross-platform inventory allows teams to source accounts for multiple advertising channels from a single trusted supplier relationship. Experienced buyers return for the consistency — same quality standards, same fast delivery, same professional support every time.
Modern platform secure email service caters to solo buyers and agencies who need reliable accounts at scale with volume pricing and priority restocking. The platform combines speed and reliability — most products are delivered automatically within minutes after payment confirmation. Instant delivery, verified quality, and dedicated support — everything a professional advertiser needs in one marketplace.
Established supplier selfie verified fb ad accounts maintains the largest selection of quality accounts with transparent specs and competitive pricing for bulk buyers. Orders are processed through a secure checkout system with multiple payment options and encrypted credential delivery via personal dashboard. Marketplace standards ensure that every account performs as described — no surprises at checkout, login, or campaign launch.
Verified marketplace buy gmail accounts usa provides access to a wide catalog of digital profiles for advertising and media buying. The knowledge base includes working guides for account warming, ad launch protocols, and reinstatement check procedures for reference. Invest in verified account infrastructure and redirect the time saved from troubleshooting into actual campaign optimization work.
Reliable source buy aged instagram accounts for influencer work connects advertisers with thoroughly vetted profiles backed by replacement guarantees and dedicated support. The team provides onboarding guidance for new buyers and ongoing operational support for teams managing high-volume campaign portfolios. Teams that prioritize account quality over raw volume consistently achieve better ROI and fewer campaign interruptions.
Reputable service PVA accounts explained publishes detailed product cards showing account age, verification status, included assets, and exact pricing tiers. Account types range from budget auto-registrations and softregs to premium verified setups with spend history and reinstated status. Build your campaigns on accounts with proven trust — higher trust means better delivery, lower costs, and fewer interruptions.
Experienced supplier tiktok business center for sale offers complete asset packages including login credentials, recovery access, 2FA codes, cookies, and user-agent data. Geo-targeted options cover USA, UK, Germany, France, Poland, Ukraine, and other regions with proper IP history and locale settings. Marketplace standards ensure that every account performs as described — no surprises at checkout, login, or campaign launch.
Premium marketplace buy facebook profiles features an extensive inventory updated daily across all major geos including USA, Europe, and Asia-Pacific regions. The platform combines speed and reliability — most products are delivered automatically within minutes after payment confirmation. Experienced buyers return for the consistency — same quality standards, same fast delivery, same professional support every time.
Жіночий онлайн https://soloha.in.ua портал з корисними статтями про моду, красу, здоров’я та стосунки. Поради щодо догляду за собою, психології, сім’ї та кар’єри. Актуальні тренди, лайфхаки та натхнення для сучасних жінок.
Інформаційний портал https://pensioneram.in.ua для пенсіонерів України Корисні поради про пенсії, соціальні виплати, пільги, здоров’я та повсякденне життя. Актуальні новини, рекомендації фахівців та прості пояснення важливих змін законодавства.
Пояснюємо складні теми https://notatky.net.ua простими словами. Публікуємо зрозумілі статті про технології, фінанси, науку, закони та інші важливі питання. Читайте розбірки та корисні пояснення.
Сайт про народні прикмети https://zefirka.net.ua тлумачення снів та значення імен. Дізнайтеся, що означають сни, як трактуються прикмети та які традиції пов’язані зі святами різних народів.
Сайт міста Дніпро https://faine-misto.dp.ua з актуальними новинами, подіями та корисною інформацією для мешканців та гостей. Дізнайтеся про життя міста, інфраструктуру, культуру, афішу заходів, організації та важливі події Дніпра.
Сайт міста Хмельницький https://faine-misto.km.ua з актуальними новинами, подіями та корисною інформацією для мешканців та гостей. Дізнайтеся про міське життя, інфраструктуру, культуру, заходи, організації та важливі події міста.
Жіночий сайт https://u-kumy.com про красу, здоров’я, моду, відносини і стиль життя. Корисні поради, статті, ідеї для натхнення та рекомендації для сучасних жінок. Читайте про саморозвиток, сім’ю, догляд за собою та актуальні тренди.
Чоловічий блог https://u-kuma.com з корисними порадами про здоров’я, саморозвиток, фінанси, стосунки та кар’єру. Публікуємо цікаві статті, лайфхаки та рекомендації для чоловіків, які хочуть покращити своє життя.
Sports betting at Mostbet https://mostbet.edu.pl/. The platform offers a wide range of events, high odds, bonuses, and a user-friendly mobile app. Place bets on football, hockey, tennis, and other sports.
Mostbet bookmaker biz.pl offers betting on sports, esports, and online games. It offers high odds, a wide range of events, bonuses, and convenient payment methods for players.
Almastriga: Relics of Azathoth almastriga com is an atmospheric horror adventure game inspired by the mythos of Lovecraft. Explore eerie locations, uncover ancient secrets, and find relics of Azathoth in a world full of mysteries and dangers.
Lust Theory Seasons lust theory 1, 2, and 3 are a popular visual novel with a captivating plot, action choices, and a diverse cast of characters. Follow the story as it unfolds, make decisions, and unlock new storylines.
Dive into Lust Academy lustacademy and explore all seasons of this popular visual novel. Learn about the characters, story, and interactive storytelling possibilities.
My Cute Roommate my cute roommate is the official website for the visual novel with a captivating storyline and interactive solutions. Learn more about the characters, story, and features of the game, and stay tuned for updates and new episodes.
Perfect Date official perfect-date.org website offers detailed information about the characters, plot, and gameplay features. Read the news and stay up-to-date on the latest updates.
Operation Lovecraft https://www.operation-lovecraft.org Official Game Guide for players who want to learn more about the plot, missions, and characters. Helpful tips, hints, and detailed guides will help you complete the game and unlock all storylines.
Бесплатная консультация юриста — это возможность получить профессиональную правовую помощь без оплаты. Перейдя по запросу бесплатная юридическая консультация круглосуточно по телефону вы получите поддержку специалиста, который выслушает вашу ситуацию, оценит риски и подскажет возможные варианты решения: от подготовки документов до защиты интересов в суде. Такая консультация помогает понять свои права, избежать ошибок и выбрать правильную стратегию действий.
Download Subverse sub-verse and dive into a forbidden galaxy full of adventure, strategy and unique characters. Explore new worlds, command your crew and experience an epic sci-fi journey in this action-packed space game.
Treasure of Nadia https://treasure-of-nadia.org Official Game Site with detailed information about the adventure game. Read news, learn about the characters, and learn about the gameplay features.
Женский портал https://7krasotok.com о красоте, здоровье, моде и отношениях. Полезные советы, статьи о семье, психологии и саморазвитии. Читайте рекомендации экспертов, узнавайте о трендах и находите вдохновение для гармоничной жизни.
Женский онлайн https://krasotka-fl.com.ua портал с полезными материалами о красоте, здоровье, моде и отношениях. Советы по уходу за собой, психологии и саморазвитию для современной женщины.
Любишь азарт? https://school57.ru предлагает разнообразные игровые автоматы, настольные игры и интересные бонусные программы. Платформа создана для комфортной игры и предлагает широкий выбор развлечений.
Консультация семейного юриста поможет быстро разобраться в сложных жизненных ситуациях: развод, раздел имущества, алименты, споры о детях и брачные договоры. Перейдя по запросу бесплатная онлайн консультация юриста по семейным делам – специалист объяснит ваши права, оценит перспективы дела и предложит оптимальный план действий. Получите профессиональную юридическую помощь и ответы на все вопросы по семейному праву.
ремонт санузла под ключ ремонт санузла в хрущевке
Хотите, чтобы ваш профиль или группа в Одноклассниках росли быстрее? Перейдя по запросу накрутка подписчиков в одноклассники с просмотрами вы сможете увеличить количество подписчиков и активность на странице. Чем больше подписчиков — тем выше доверие и интерес к вашему аккаунту. Начните развивать свою страницу уже сегодня!
Хотите быстро развить канал на Rutube? Накрутка подписчиков Rutube поможет увеличить аудиторию, повысить доверие к каналу и ускорить продвижение видео. Перейдя по запросу как набрать много просмотров на рутуб вы получите живых подписчиков, плавное добавление и безопасные методы продвижения. Отличное решение для новых и развивающихся каналов, которым важно быстрее набрать активность и привлечь больше просмотров. Начните рост канала уже сегодня.
Продвигайте свой аккаунт быстрее с помощью накрутки подписчиков в TikTok. Перейдя по запросу накрутка подписчиков тик ток дешево вы сможете увеличить количество фолловеров, повысить доверие к профилю и привлечь больше просмотров и лайков. Быстрая и безопасная накрутка поможет вашему контенту попасть в рекомендации и ускорить рост аккаунта. Подходит для блогеров, брендов и бизнеса, которые хотят развиваться в TikTok и получать больше охватов.
Бесплатная консультация семейного юриста — это возможность быстро разобраться в сложной ситуации и понять свои права. Перейдя по запросу юридическая помощь по семейным спорам в МСК юрист поможет вам по вопросам развода, алиментов, раздела имущества, опеки над детьми и другим семейным спорам. Разъясним перспективы дела и подскажем оптимальное решение. Получите профессиональную помощь без оплаты и лишних обязательств.
I real delighted to find this internet site on bing, just what I was looking for : D likewise saved to bookmarks.
Бесплатная консультация юриста по расторжению брака поможет разобраться в ваших правах и возможностях при разводе. Специалист объяснит порядок развода через суд или ЗАГС, подскажет, как решаются вопросы раздела имущества, алиментов и проживания детей. Перейдя по запросу юрист по семейным и бракоразводным делам вы получите профессиональные рекомендации и ответы на все вопросы, чтобы пройти процедуру развода максимально спокойно и с защитой ваших интересов.
ремонт ванна туалет ключ ремонт ванн спб цена
Юридическая консультация по разделу имущества поможет защитить ваши права и избежать ошибок при разводе или спорах между собственниками. Переходите по запросу юрист по разделу квартиры – юрист оценит ситуацию, разъяснит перспективы дела, подскажет, как правильно оформить документы и выстроить стратегию. Вы получите чёткий план действий и поддержку на каждом этапе — от переговоров до суда.
Все подробности: https://l-parfum.ru/catalog/nabory/
Бесплатная консультация юриста по взысканию алиментов — первый шаг к защите ваших прав и интересов ребёнка. Переходите по запросу юридическая консультация по алиментам бесплатно по телефону круглосуточно и получите разбор именно вашей ситуации, узнайте порядок действий, какие нужно собрать документы и оценку перспектив дела. Поддержка на каждом этапе — от обращения в суд до фактического получения алиментых выплат. Запишитесь уже сегодня!
Юридическая помощь по защите прав ребенка — это поддержка в самых важных ситуациях: от споров о месте проживания и алиментах до защиты от насилия и нарушения прав в школе. Переходите по запросу детский адвокат и квалифицированный юрист поможет отстоять интересы ребенка, подготовить документы и представить ваши интересы в суде, обеспечив безопасность и справедливость.
Тензоприбор предлагает калибровочные гири для весов нужного класса точности и номинальной массы для калибровки весов.
В нашей компании можно купить калибровочные гири классов точности E1, E2, F1, F2, M1, M2.
Чем выше класс точности, тем меньше будет разница между номинальным и действительным значениями массы калибровочной гири.
дизайн проект интерьера частного дома коттедж дизайн
Все самое свежее здесь: http://warhammer.world.free.fr/profile.php?mode=viewprofile&u=21806
Юридическая консультация по лишению родительских прав поможет оценить ситуацию, определить основания и выстроить грамотную стратегию защиты или подачи иска. Переходите по запросу юрист по правам родителей – специалист разъяснит порядок действий и подготовит документы. Получите профессиональную поддержку и ответы на все вопросы уже на первой консультации.
Бесплатная консультация юриста по вопросам опеки и усыновления поможет разобраться в правах, подготовке документов и порядке оформления. Переходите по запросу юридическая помощь по опеке – специалист подскажет, как действовать в вашей ситуации, оценит риски и предложит оптимальное решение. Получите профессиональную помощь по делам опеки и попечительства на каждом шаге без лишних затрат.
Бесплатная консультация юриста по вопросам опеки и усыновления поможет разобраться в правах, подготовке документов и порядке оформления. Переходите по запросу юридическая консультация по попечительству над ребенком – специалист подскажет, как действовать в вашей ситуации, оценит риски и предложит оптимальное решение. Получите профессиональную помощь по делам опеки и попечительства на каждом шаге без лишних затрат.
Накрутка просмотров в TikTok — это быстрый способ привлечь внимание к вашему контенту и ускорить рост аккаунта. Переходите по запросу просмотры на видео тикток Кворк и величьте показатели популярности, повысьте доверие аудитории и попадите в рекомендации. Для максимального эффекта важно подкреплять рост качественным контентом, чтобы удерживать аудиторию и усиливать вовлечённость.
Услуга накрутки просмотров на канал YouTube поможет быстро увеличить активность под вашими видео и привлечь внимание аудитории. Переходите по запросу как накрутить просмотры в ютуб. Дополнительные просмотры повышают видимость роликов в рекомендациях, улучшают статистику канала и создают эффект популярности. Подходит для продвижения новых и существующих видео, увеличения охвата и ускоренного роста канала на YouTube.
Расширенный обзор: https://sobranie-novostroy.ru
дизайн проект интерьера дизайн квартиры
Продвигайте свой канал в Яндекс Дзен быстрее: увеличьте число подписчиков и создайте эффект популярности. Переходите по запросу накрутка подписчиков в дзен канал. Накрутка поможет привлечь внимание новой аудитории, повысить доверие к каналу и ускорить рост. Подходит для новых и развивающихся блогов, чтобы быстрее выйти в рекомендации и усилить продвижение контента.
дизайн проект квартиры санкт петербург спб дизайнер интерьера
Продвигайте свой канал быстрее с услугой накрутки подписчиков в YouTube. Увеличьте количество фолловеров, повысьте доверие к каналу и привлеките новую аудиторию. Переходите по запросу подписчики youtube купить Кворк. Быстрый старт для блогеров, брендов и экспертов. Живые и качественные подписчики, безопасное продвижение и заметный рост популярности вашего контента. Начните развивать канал уже сегодня!
Маркетплейс 1С-Битрикс — это официальный каталог готовых решений, модулей и интеграций для сайтов на платформе Bitrix. Переходите по запросу cms Bitrix маркетплейс и вы найдете расширения для интернет-магазинов, CRM, SEO, аналитики, платежных систем и автоматизации бизнеса. Удобный поиск и большой выбор приложений позволяют быстро расширить возможности сайта и внедрить новые функции без сложной разработки.
Toàn bộ hệ thống được vận hành dưới tiêu chuẩn bảo mật SSL 128-bit, giúp mã hóa mọi dữ liệu giao dịch và thông tin cá nhân. Tất cả các thao tác như đăng nhập, rút tiền hay xác minh đều được mã hóa ở cấp độ cao nhằm loại bỏ nguy cơ rò rỉ dữ liệu. slot365 có uy tín không còn hợp tác với các đơn vị kiểm toán độc lập để định kỳ rà soát hệ thống, đảm bảo tuân thủ đúng các yêu cầu kỹ thuật và pháp lý quốc tế.
Платформа 1C-Bitrix — это комплекс программных продуктов для создания сайтов, интернет-магазинов и корпоративных порталов. Переходите по запросу программы Bitrix. Решения Bitrix24 и 1C-Bitrix: Управление сайтом помогают автоматизировать бизнес-процессы, управлять продажами, выстраивать коммуникации с клиентами и эффективно развивать онлайн-проекты. Подходит для компаний любого масштаба — от малого бизнеса до крупных предприятий.
Бесплатная юридическая консультация поможет разобраться в сложной ситуации и понять, какие действия предпринять дальше. Переходите по запросу бесплатная помощь юриста по телефону и вы сможете задать вопрос юристу онлайн и получить разъяснение по гражданским, семейным, трудовым, жилищным и другим правовым вопросам. Специалист подскажет возможные решения, объяснит ваши права и поможет оценить перспективы дела. Консультация доступна онлайн и по телефону, быстро и без лишних формальностей.
Ищете надежные лицензии для 1С-Битрикс? Мы предлагаем легальные решения для всех типов проектов: интернет-магазинов, корпоративных сайтов и порталов. Переходите по запросу 1 с Битрикс стоимость. Быстрая активация, официальная поддержка и выгодные условия – обеспечьте своему веб-проекту стабильную работу и защиту с надежным ПО уже сегодня!
Старый паркет? шлифовка паркета в спб профессиональное восстановление деревянного пола без пыли и лишних затрат. Удаляем царапины, потемнения и старое покрытие, возвращаем гладкость и естественный цвет. Используем современное оборудование, выполняем циклевку, шлифовку и лакировку паркета под ключ с гарантией качества и точным соблюдением сроков.
Current Updates: https://www.warriorforum.com/members/alex-snow.html
All the latest here: https://kariorangpower.com/melhores-casinos-online-em-portugal-top-10-dezembro-criancice-2025/
Лицензия «Битрикс: Управление сайтом – Старт» — оптимальное решение для создания небольшого сайта, лендинга или корпоративной страницы. Переходите по запросу Bitrix редакция Старт. Редакция включает базовые инструменты для управления контентом, готовые модули, защиту сайта и удобную административную панель. Подходит для быстрого запуска проекта на CMS 1C-Битрикс с возможностью дальнейшего масштабирования и перехода на более функциональные редакции.
The best is in one place: https://ampracing.com.br/2026/03/11/brazzers-pornography-movies/
Learn more here: https://geintech.com/14-melhores-casinos-online-acercade-portugal-em-dezembro-2025/
All details at the link: https://www.animenewsnetwork.com/bbs/phpBB2/profile.php?mode=viewprofile&u=1165233
Must-Read Collection: https://impulsionshades.com/2500-welcome-local-casino-added-bonus/
1C-Bitrix: Управление сайтом — редакция Стандарт — это мощная платформа для создания и управления корпоративными сайтами. Переходите по запросу Битрикс управление сайтом Стандарт цена. Подходит для компаний, которым нужен функциональный сайт с каталогом, формами, SEO-инструментами и удобной системой администрирования. Решение обеспечивает высокую безопасность, производительность и гибкость масштабирования бизнеса в интернете.
Битрикс: Управление сайтом Малый Бизнес — функциональная редакция CMS для создания интернет-магазинов и коммерческих проектов. Переходите по запросу Битрикс управление сайтом Малый Бизнес купить. Система включает каталог товаров, корзину, онлайн-оплаты, маркетинговые инструменты и интеграцию с 1С. Решение подходит для компаний, которым нужен надежный и масштабируемый сайт с возможностью расширения функционала через модули и интеграции.
Подробности на странице: шлифовка паркета
Обязательно к прочтению: циклевка паркета
Продвижение сообщества или страницы во ВКонтакте с помощью привлечения подписчиков. Услуга помогает быстро увеличить аудиторию, повысить активность и доверие к группе или профилю. Переходите по запросу подписчики в вк группу. Возможна накрутка живых и заинтересованных пользователей, что улучшает видимость сообщества, помогает быстрее развивать бренд, проекты и продажи. Подходит для групп, пабликов и личных страниц.
Нужны подписчики в Telegram? Поможем быстро увеличить аудиторию вашего канала или группы. Переходите по запросу накрутка подписчиков в тг от 10. Предлагаем накрутку живых и активных подписчиков без резких скачков и с минимальными списаниями. Подходит для старта новых каналов, повышения доверия и привлечения органической аудитории. Безопасное продвижение, гибкие объемы заказа и быстрый запуск. Увеличьте популярность вашего Telegram-канала уже сегодня.
Специалисты компании выполнят изготовление этикеток любого формата и сложности: тканых жаккардовых, деревянных, металлических, кожаных и проч.
Чтобы картонные бирки для одежды не утратили своего первоначального вида и были износостойкими, мы используем только качественные материалы.
Нужна бесплатная юридическая консультация? Переходите по запросу спросить юриста в Питере и получите помощь опытного юриста по любым правовым вопросам: семейные споры, долги, недвижимость, трудовые конфликты, защита прав потребителей и многое другое. Задайте вопрос онлайн или по телефону и получите подробный разбор вашей ситуации и рекомендации по дальнейшим действиям. Консультация проводится бесплатно и конфиденциально.
Нужна бесплатная юридическая консультация? Переходите по запросу юридическая консультация online в Балашихе и получите помощь опытного юриста по любым правовым вопросам: семейные споры, долги, недвижимость, трудовые конфликты, защита прав потребителей и многое другое. Задайте вопрос онлайн или по телефону и получите подробный разбор вашей ситуации и рекомендации по дальнейшим действиям. Консультация проводится бесплатно и конфиденциально.
Нужна бесплатная юридическая консультация? Переходите по запросу вопрос юристу в чате онлайн в Подмосковье и получите помощь опытного юриста по любым правовым вопросам: семейные споры, долги, недвижимость, трудовые конфликты, защита прав потребителей и многое другое. Задайте вопрос онлайн или по телефону и получите подробный разбор вашей ситуации и рекомендации по дальнейшим действиям. Консультация проводится бесплатно и конфиденциально.
Нужна бесплатная юридическая консультация? Переходите по запросу вопрос адвокату бесплатно в Подольске и получите помощь опытного юриста по любым правовым вопросам: семейные споры, долги, недвижимость, трудовые конфликты, защита прав потребителей и многое другое. Задайте вопрос онлайн или по телефону и получите подробный разбор вашей ситуации и рекомендации по дальнейшим действиям. Консультация проводится бесплатно и конфиденциально.
Нужна бесплатная юридическая консультация? Переходите по запросу спросить юриста бесплатно в онлайн чате в Химках и получите помощь опытного юриста по любым правовым вопросам: семейные споры, долги, недвижимость, трудовые конфликты, защита прав потребителей и многое другое. Задайте вопрос онлайн или по телефону и получите подробный разбор вашей ситуации и рекомендации по дальнейшим действиям. Консультация проводится бесплатно и конфиденциально.
Услуга по увеличению показателей в Дзене: подписчики, дочитки и лайки для роста активности и видимости канала. Переходите по запросу продвижение статьи в дзене. Поможем быстро усилить социальные сигналы, повысить привлекательность публикаций и ускорить продвижение. Подходит для новых и действующих каналов, чтобы улучшить статистику и привлечь больше реальной аудитории.
Разработка интернет-магазина на 1С-Битрикс под ключ на шаблоне. Переходите по запросу создание интернет магазина Bitrix24 и получите удобный, быстрый и продающий сайт с адаптивным дизайном, интеграцией CRM, оплатой и доставкой. Оптимизируем под SEO и помогаем увеличить продажи. Индивидуальный подход, прозрачные сроки и поддержка на всех этапах.
Разработка сайта на 1С-Битрикс под ключ на шаблоне. Переходите по запросу разработка сайтов на 1с Битрикс и получите удобный, быстрый и продающий сайт с адаптивным дизайном, интеграцией CRM, оплатой и доставкой. Оптимизируем под SEO и помогаем увеличить продажи. Индивидуальный подход, прозрачные сроки и поддержка на всех этапах.
База сайтов для Xrumer — это тщательно отобранный список площадок для эффективного размещения ссылок и автоматического постинга. Переходите по запросу цена базы ссылок хрумер кворк. База подходит для SEO-продвижения, ускоряет наращивание ссылочной массы и экономит время. Актуальные и рабочие ресурсы, регулярное обновление и высокая проходимость обеспечивают максимальный результат.