

Giant language fashions (LLMs) like GPT, LLaMA, and others have taken the world by storm with their exceptional skill to grasp and generate human-like textual content. Nonetheless, regardless of their spectacular capabilities, the usual technique of coaching these fashions, often called “next-token prediction,” has some inherent limitations.
In next-token prediction, the mannequin is skilled to foretell the subsequent phrase in a sequence given the previous phrases. Whereas this method has confirmed profitable, it may possibly result in fashions that wrestle with long-range dependencies and sophisticated reasoning duties. Furthermore, the mismatch between the teacher-forcing coaching regime and the autoregressive era course of throughout inference may end up in suboptimal efficiency.
A current analysis paper by Gloeckle et al. (2024) from Meta AI introduces a novel coaching paradigm known as “multi-token prediction” that goals to deal with these limitations and supercharge giant language fashions. On this weblog put up, we’ll dive deep into the core ideas, technical particulars, and potential implications of this groundbreaking analysis.
What’s Multi-token Prediction?
The important thing thought behind multi-token prediction is to coach language fashions to foretell a number of future tokens concurrently, fairly than simply the subsequent token. Particularly, throughout coaching, the mannequin is tasked with predicting the subsequent n tokens at every place within the coaching corpus, utilizing n impartial output heads working on prime of a shared mannequin trunk.
For instance, with a 4-token prediction setup, the mannequin could be skilled to foretell the subsequent 4 tokens directly, given the previous context. This method encourages the mannequin to seize longer-range dependencies and develop a greater understanding of the general construction and coherence of the textual content.
A Toy Instance
To higher perceive the idea of multi-token prediction, let’s think about a easy instance. Suppose we now have the next sentence:
“The short brown fox jumps over the lazy canine.”
In the usual next-token prediction method, the mannequin could be skilled to foretell the subsequent phrase given the previous context. For example, given the context “The short brown fox jumps over the,” the mannequin could be tasked with predicting the subsequent phrase, “lazy.”
With multi-token prediction, nevertheless, the mannequin could be skilled to foretell a number of future phrases directly. For instance, if we set n=4, the mannequin could be skilled to foretell the subsequent 4 phrases concurrently. Given the identical context “The short brown fox jumps over the,” the mannequin could be tasked with predicting the sequence “lazy canine .” (Observe the area after “canine” to point the tip of the sentence).
By coaching the mannequin to foretell a number of future tokens directly, it’s inspired to seize long-range dependencies and develop a greater understanding of the general construction and coherence of the textual content.
Technical Particulars
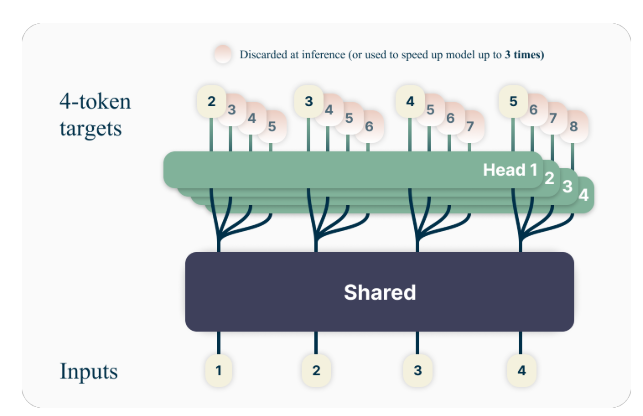
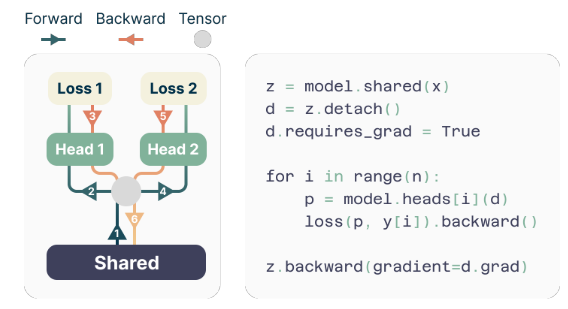
The authors suggest a easy but efficient structure for implementing multi-token prediction. The mannequin consists of a shared transformer trunk that produces a latent illustration of the enter context, adopted by n impartial transformer layers (output heads) that predict the respective future tokens.
Throughout coaching, the ahead and backward passes are rigorously orchestrated to attenuate the GPU reminiscence footprint. The shared trunk computes the latent illustration, after which every output head sequentially performs its ahead and backward cross, accumulating gradients on the trunk degree. This method avoids materializing all logit vectors and their gradients concurrently, decreasing the height GPU reminiscence utilization from O(nV + d) to O(V + d), the place V is the vocabulary measurement and d is the dimension of the latent illustration.
The Reminiscence-efficient Implementation
One of many challenges in coaching multi-token predictors is decreasing their GPU reminiscence utilization. For the reason that vocabulary measurement (V) is usually a lot bigger than the dimension of the latent illustration (d), logit vectors turn out to be the GPU reminiscence utilization bottleneck.
To deal with this problem, the authors suggest a memory-efficient implementation that rigorously adapts the sequence of ahead and backward operations. As a substitute of materializing all logits and their gradients concurrently, the implementation sequentially computes the ahead and backward passes for every impartial output head, accumulating gradients on the trunk degree.
This method avoids storing all logit vectors and their gradients in reminiscence concurrently, decreasing the height GPU reminiscence utilization from O(nV + d) to O(V + d), the place n is the variety of future tokens being predicted.
Benefits of Multi-token Prediction
The analysis paper presents a number of compelling benefits of utilizing multi-token prediction for coaching giant language fashions:
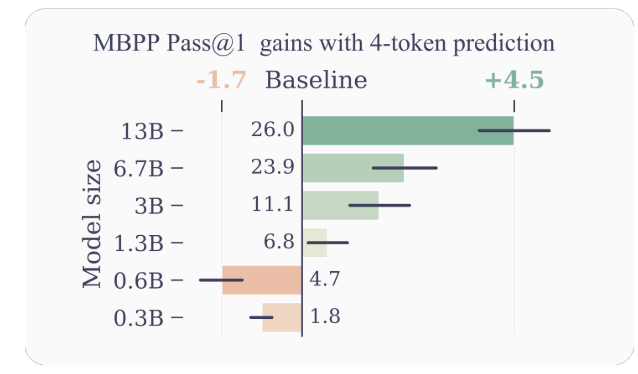
- Improved Pattern Effectivity: By encouraging the mannequin to foretell a number of future tokens directly, multi-token prediction drives the mannequin in the direction of higher pattern effectivity. The authors exhibit important enhancements in efficiency on code understanding and era duties, with fashions as much as 13B parameters fixing round 15% extra issues on common.
- Sooner Inference: The extra output heads skilled with multi-token prediction will be leveraged for self-speculative decoding, a variant of speculative decoding that permits for parallel token prediction. This ends in as much as 3x quicker inference instances throughout a variety of batch sizes, even for big fashions.
- Selling Lengthy-range Dependencies: Multi-token prediction encourages the mannequin to seize longer-range dependencies and patterns within the knowledge, which is especially helpful for duties that require understanding and reasoning over bigger contexts.
- Algorithmic Reasoning: The authors current experiments on artificial duties that exhibit the prevalence of multi-token prediction fashions in growing induction heads and algorithmic reasoning capabilities, particularly for smaller mannequin sizes.
- Coherence and Consistency: By coaching the mannequin to foretell a number of future tokens concurrently, multi-token prediction encourages the event of coherent and constant representations. That is significantly helpful for duties that require producing longer, extra coherent textual content, resembling storytelling, inventive writing, or producing educational manuals.
- Improved Generalization: The authors’ experiments on artificial duties recommend that multi-token prediction fashions exhibit higher generalization capabilities, particularly in out-of-distribution settings. That is doubtlessly because of the mannequin’s skill to seize longer-range patterns and dependencies, which may help it extrapolate extra successfully to unseen situations.

Examples and Intuitions
To supply extra instinct on why multi-token prediction works so nicely, let’s think about a number of examples:
- Code Era: Within the context of code era, predicting a number of tokens concurrently may help the mannequin perceive and generate extra complicated code constructions. For example, when producing a perform definition, predicting simply the subsequent token won’t present sufficient context for the mannequin to generate the complete perform signature appropriately. Nonetheless, by predicting a number of tokens directly, the mannequin can higher seize the dependencies between the perform identify, parameters, and return sort, resulting in extra correct and coherent code era.
- Pure Language Reasoning: Contemplate a situation the place a language mannequin is tasked with answering a query that requires reasoning over a number of steps or items of data. By predicting a number of tokens concurrently, the mannequin can higher seize the dependencies between the completely different parts of the reasoning course of, resulting in extra coherent and correct responses.
- Lengthy-form Textual content Era: When producing long-form textual content, resembling tales, articles, or studies, sustaining coherence and consistency over an prolonged interval will be difficult for language fashions skilled with next-token prediction. Multi-token prediction encourages the mannequin to develop representations that seize the general construction and circulation of the textual content, doubtlessly resulting in extra coherent and constant long-form generations.
Limitations and Future Instructions
Whereas the outcomes offered within the paper are spectacular, there are a number of limitations and open questions that warrant additional investigation:
- Optimum Variety of Tokens: The paper explores completely different values of n (the variety of future tokens to foretell) and finds that n=4 works nicely for a lot of duties. Nonetheless, the optimum worth of n could rely upon the particular activity, dataset, and mannequin measurement. Creating principled strategies for figuring out the optimum n may result in additional efficiency enhancements.
- Vocabulary Measurement and Tokenization: The authors word that the optimum vocabulary measurement and tokenization technique for multi-token prediction fashions could differ from these used for next-token prediction fashions. Exploring this side may result in higher trade-offs between compressed sequence size and computational effectivity.
- Auxiliary Prediction Losses: The authors recommend that their work may spur curiosity in growing novel auxiliary prediction losses for big language fashions, past the usual next-token prediction. Investigating different auxiliary losses and their combos with multi-token prediction is an thrilling analysis course.
- Theoretical Understanding: Whereas the paper gives some intuitions and empirical proof for the effectiveness of multi-token prediction, a deeper theoretical understanding of why and the way this method works so nicely could be useful.
Conclusion
The analysis paper “Higher & Sooner Giant Language Fashions through Multi-token Prediction” by Gloeckle et al. introduces a novel coaching paradigm that has the potential to considerably enhance the efficiency and capabilities of huge language fashions. By coaching fashions to foretell a number of future tokens concurrently, multi-token prediction encourages the event of long-range dependencies, algorithmic reasoning talents, and higher pattern effectivity.
The technical implementation proposed by the authors is elegant and computationally environment friendly, making it possible to use this method to large-scale language mannequin coaching. Moreover, the power to leverage self-speculative decoding for quicker inference is a major sensible benefit.
Whereas there are nonetheless open questions and areas for additional exploration, this analysis represents an thrilling step ahead within the subject of huge language fashions. Because the demand for extra succesful and environment friendly language fashions continues to develop, multi-token prediction may turn out to be a key element within the subsequent era of those highly effective AI programs.