
Current advances in giant language fashions (LLMs) like GPT-4, PaLM have led to transformative capabilities in pure language duties. LLMs are being included into numerous purposes resembling chatbots, search engines like google, and programming assistants. Nevertheless, serving LLMs at scale stays difficult as a consequence of their substantial GPU and reminiscence necessities.
Approaches to beat this usually fall into two most important classes:
- Mannequin Compression Strategies
These strategies goal to scale back the dimensions of the mannequin whereas sustaining accuracy. Frequent approaches embrace:
- Pruning – Eradicating redundant or much less essential parameters from the mannequin. This creates a sparse mannequin with fewer parameters.
- Quantization – Utilizing decrease precision numbers like int8 or bfloat16 to characterize weights as an alternative of fp32 or fp16. This reduces reminiscence footprint.
- Data distillation – Coaching a smaller “pupil” mannequin to imitate a big “trainer” mannequin. The smaller mannequin is then used for inference.
- Selective Execution
Reasonably than compressed fashions, these strategies selectively execute solely elements of the mannequin per inference:
- Sparse activations – Skipping computation on zero activations.
- Conditional computation – Executing solely sure layers conditioned on the enter.
On complementary facet wrt to the software program architect facet; to allow sooner deployment of LLMs researchers have proposed serverless inference programs. In serverless architectures, LLMs are hosted on shared GPU clusters and allotted dynamically based mostly on demand. This permits environment friendly utilization of GPUs and reduces prices for builders. Outstanding implementations embrace Amazon SageMaker, Microsoft Azure ML, and open-source choices like KServe.
Regardless of the promise of serverless LLMs, present programs exhibit excessive latency overheads that degrade person expertise in interactive purposes:
- Expensive checkpoint downloads: LLMs have giant reminiscence footprints, usually gigabytes to terabytes in dimension. Downloading checkpoints from distant storage is time-consuming, taking on 20 seconds even with optimized networks.
- Inefficient checkpoint loading: Even with native SSD storage, loading checkpoints into GPU reminiscence takes tens of seconds as a consequence of components like tensor deserialization and allocation. This provides vital delays past container startup time.
To deal with these points, researchers at MIT CSAIL proposed ServerlessLLM, an modern system that achieves low-latency serverless inference for LLMs. ServerlessLLM enhances locality by exploiting the plentiful but underutilized capability and bandwidth in multi-tier server storage for LLM deployment.

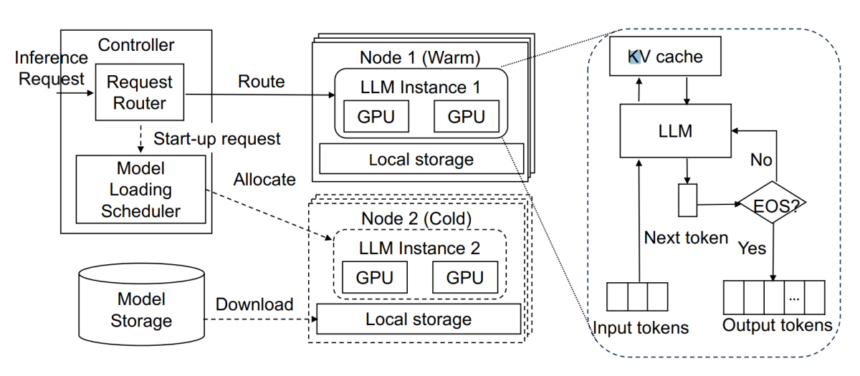
Overview of LLM serverless inference programs
Key Improvements in ServerlessLLM ServerlessLLM incorporates a number of novel designs to slash LLM loading instances in serverless environments:
- Fast checkpoint loading
- Loading-optimized checkpoint format that allows quick sequential studying and environment friendly in-memory tensor addressing.
- Multi-tier checkpoint loading pipeline that maximizes bandwidth utilization throughout community, SSDs, DRAM, and GPU reminiscence by means of strategies like direct I/O, pinned reminiscence switch, and parallelism.
- Reside migration for locality-driven inference
- Token-based migration that solely transmits important immediate tokens over the community, avoiding gradual snapshot switch.
- Two-phase migration that enables uninterrupted inference by asynchronously recomputing cache states on the vacation spot server earlier than transferring last tokens.
- Latency-optimized server allocation
- Correct fashions to estimate checkpoint loading instances from every tier and migration instances for a server.
- Locality-aware scheduler that selects servers minimizing anticipated startup latency utilizing the above fashions.
These optimizations enable ServerlessLLM to scale back LLM loading instances by 4-8X and end-to-end startup instances by over 25X in comparison with present programs like PyTorch, TensorFlow, and KServe.
Let’s dive deeper into how ServerlessLLM achieves these vital efficiency positive aspects.
Accelerating Checkpoint Loading
The primary main bottleneck addressed by ServerlessLLM is the excessive latency of loading LLM checkpoints from storage into GPU reminiscence.
To allow fast checkpoint loading, ServerlessLLM introduces:
- Loading-optimized checkpoint format
Commonplace checkpoints utilized by frameworks like PyTorch are designed for mannequin coaching and debugging. However for serverless inference, checkpoints are read-only and accessed repeatedly.
To optimize for such read-intensive utilization, ServerlessLLM converts checkpoints right into a format with two key properties:
- Sequential chunk-based studying: Tensors are grouped into per-GPU binary recordsdata, facilitating giant sequential reads.
- Environment friendly tensor addressing: An index maps tensor names to reminiscence offsets, permitting direct in-memory restoration with out deserialization.
- Multi-tier checkpoint loading pipeline
ServerlessLLM leverages the tiered structure of GPU servers, with storage media like SSDs and networking connecting to GPUs through PCIe, NVMe, and many others.
The system incorporates a multi-stage pipeline to maximise bandwidth utilization throughout all tiers:
- In-memory information chunks are allotted utilizing pinned reminiscence for quick GPU switch.
- Direct I/O is used for environment friendly SSD reads with out caching overheads.
- A number of threads learn totally different storage chunks in parallel.
- Inter-stage coordination happens through asynchronous job queues.
Collectively, this allows saturating the bandwidth capability of even the quickest tiers like NVMe RAID. Experiments reveal that ServerlessLLM achieves 6-8X sooner loading than PyTorch/TensorFlow, lowering startup instances for giant LLMs from over a minute to below 10 seconds.
Locality-Pushed LLM Inference through Reside Migration
With accelerated loading, ServerlessLLM faces a brand new problem – the right way to leverage pre-loaded checkpoints for locality with out interrupting ongoing inferences on busy servers?
ServerlessLLM introduces a novel method – stay migration of LLM inference throughout GPU servers. This permits seamlessly transferring execution to servers with native checkpoints obtainable.
Key enablers of stay LLM migration:
- Token-based migration
Reasonably than snapshotting your complete mannequin state, ServerlessLLM solely migrates the minimal immediate tokens over the community. This transfers orders of magnitude much less information than snapshots.
- Two-phase migration
Vacation spot server asynchronously precomputes cache states from immediate tokens. As soon as prepared, supply server transfers last tokens earlier than releasing assets. This prevents inference stalls.
Experiments reveal that token-based migration slashes migration instances from tens of seconds to below a second even for lengthy sequences. Reside migration is essential to forestall queuing delays when attaining locality-driven allocation.
Latency-Optimized Mannequin Scheduling
To attenuate end-to-end latency, ServerlessLLM enhances the scheduler to optimize server choice contemplating locality. This includes:
- Effective-grained loading time estimator
Fashions predict loading instances from community, SSD caches, and reminiscence for every server utilizing metrics like queue delays, mannequin sizes, and measured bandwidth.
- Correct migration time predictor
The scheduler estimates migration instances for servers utilizing the variety of immediate and output tokens. It tracks inference progress asynchronously to keep away from overhead.
- Locality-aware allocation
For every inference request, the scheduler evaluates estimated loading and migration instances throughout servers. It selects the server minimizing anticipated startup latency.
The scheduler additionally maintains server job queues and leverages a strongly constant retailer for fault tolerance. Collectively, these improvements cut back scheduling overheads whereas maximizing locality advantages.
Evaluating ServerlessLLM Efficiency
Complete experiments benchmark the end-to-end effectiveness of ServerlessLLM towards present programs utilizing real-world fashions like OPT-175B and workloads modeled after Azure traces.
Key outcomes:
- Microbenchmarks: ServerlessLLM accelerates checkpoint loading by 3.6-8.2X over PyTorch/TensorFlow. It absolutely saturates storage bandwidth, even for cutting-edge NVMe RAID.
- Scheduling: ServerlessLLM reduces allocation latency by 4-12X in comparison with random scheduling, highlighting advantages of locality-awareness. Reside migration prevents queuing delays.
- Finish-to-end serving: For giant fashions like OPT-30B, ServerlessLLM improves 99th percentile latency by 28-200X over programs like KServe and Ray Serve. It additionally enhances useful resource effectivity.
These substantial positive aspects display ServerlessLLM’s means to beat bottlenecks in present serverless implementations and unlock the facility of LLMs for interactive companies.
The optimizations launched in ServerlessLLM, like multi-tier loading, stay migration, and latency-driven scheduling, will help inform the design of future serverless architectures. The system’s means to slash loading and startup instances unblocks the scalable deployment of huge language fashions for sensible purposes.
Wanting Forward: Ongoing Challenges
Whereas a big leap ahead, ServerlessLLM represents solely step one in optimizing serverless inference for enormous LLMs. A number of open issues stay, together with:
- Predicting real-time mannequin demand to information provisioning and pre-loading
- Intelligently putting checkpoints throughout servers to maximise cache hits
- Effectively scaling scheduling algorithms to deal with bigger clusters
- Making certain equity in useful resource allocation throughout fashions and builders
- Generalizing improvements like stay migration to different serverless workloads
Addressing these areas will help construct on the promise of serverless LLMs and make their capabilities much more accessible. Past system-level optimizations, lowering the egregious carbon footprint and potential harms of huge fashions additionally stays an pressing precedence.
ServerlessLLM demonstrates that great headroom exists for innovation in next-generation serverless architectures for AI workloads. As LLMs proceed ballooning in dimension and recognition, options like ServerlessLLM that unlock their scalability will develop much more impactful. The confluence of programs and machine studying analysis can introduce new paradigms in serving, sharing, and scaling AI fashions safely and sustainably.


Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?