
Object segmentation is a foundational and critically essential subject in trendy laptop imaginative and prescient. It performs an important function in functions requiring in depth visible elements, equivalent to object localization and identification, and calls for real-time, quick, and correct segmentation. This significance has made object segmentation a constantly sizzling analysis subject, with vital work achieved in areas like occasion segmentation, semantic segmentation, and panoptic segmentation.
With the evolution of object segmentation, the Phase Something Mannequin (SAM) has emerged as a outstanding device, showcasing excellent segmentation talents and shortly being adopted in varied laptop imaginative and prescient functions. Frameworks utilizing a pre-trained SAM structure have achieved spectacular efficiency in downstream imaginative and prescient duties. Nevertheless, regardless of its capabilities and excessive accuracy in segmentation duties, SAM’s advanced and heavy structure necessitates substantial computational energy, hindering its implementation on computationally constrained units.
Addressing SAM’s computational challenges, researchers have developed the Tiny Phase Something Mannequin (TinySAM), which retains the zero-shot efficiency of the unique framework whereas being extra light-weight. TinySAM makes use of a full-stage data distillation technique with on-line laborious prompts to create a extra environment friendly pupil mannequin. Put up-training quantization tailored to promptable segmentation duties additional reduces computational wants. Moreover, TinySAM’s design goals for hierarchical segmentation, virtually doubling the inference pace with out compromising efficiency.
This text delves into the TinySAM framework, exploring its foundational rules, structure, and efficiency in comparison with different state-of-the-art segmentation frameworks. Let’s discover these elements in additional element.
The Phase Something Mannequin has helped within the fast progress of a number of laptop imaginative and prescient functions owing to its commendable segmentation capabilities coupled with an enormous segmentation dataset that homes over 11 million pictures and over a billion picture masks. Owing to its distinctive efficiency on duties segmenting objects with arbitrary classes and shapes, it serves as the inspiration for frameworks performing downstream duties like picture inpainting, object monitoring, 3D imaginative and prescient, and extra. Moreover, the Phase Something Mannequin additionally provides outstanding zero-shot segmentation efficiency that has benefitted delicate industries that work with a restricted quantity of information together with the medical analysis and medical imaging industries.
Though one can’t query the outstanding segmentation capabilities provided by the Phase Something Mannequin on a wide selection of downstream imaginative and prescient duties, it does have its draw back when it comes to a posh architectural overload, excessive computational necessities, and vital operational prices. For a system working on a contemporary GPU, the inference time of a SAM mannequin might be as excessive as as much as 2 seconds for a 1024×1024 picture. In consequence, it’s a extremely troublesome process to implement SAM functions on units with restricted computational talents. To beat this hurdle, current works like MobileSAM and FastSAM have tried to develop a SAM mannequin with extra computational effectivity. The MobileSAM framework makes an attempt to interchange the heavy element within the picture encoder with the structure of the TinyViT framework whereas the FastSAM mannequin transfers the section process to an occasion segmentation process with just one class with the YoloV8 mannequin. Though these strategies have been in a position to obtain some stage of success when it comes to lowering the computational necessities, they might not keep the efficiency particularly on downstream zero-shot duties.
TinySAM or the Tiny Phase Something Mannequin is an try to cut back the computational requirement of the present SAM mannequin with out hindering the efficiency on zero-shot downstream duties. Moreover, the TinySAM framework proposes to implement a full-stage data distillation technique in its structure with the goal of enhancing the power of the compact pupil community. The TinySAM framework distills the coed community in an finish to finish method underneath the supervision of the trainer community from totally different phases. To spice up efficiency additional, the framework permits the distillation course of to attend extra to laborious examples by implementing an extra on-line laborious immediate sampling technique. Moreover, to moreover scale back computational prices, the TinySAM framework exposes the promptable segmentation duties to post-training quantization elements.
The key chunk of the computation requirement of a Phase Something Mannequin is as a result of the mannequin generates large masks from the grid immediate factors to section every part within the picture. To beat the computational requirement of this segmentation technique, the TinySAM framework employs a hierarchical section every part technique that nearly doubles the inference pace with out degrading the efficiency. With these strategies employed in its structure, the TinySAM framework provides vital discount in computational necessities, and units new limits for environment friendly section something duties.
TinySAM : Structure and Methodology
Earlier than we speak concerning the structure and methodology of the TinySAM framework, it is very important first take a look at its predecessor, the SAM framework. Ever since its introduction, the Phase Something Mannequin has demonstrated outstanding efficiency, versatility, and generalization capabilities throughout a variety of downstream imaginative and prescient and object segmentation duties.
At its core, the SAM mannequin consists of three subnetworks: the immediate encoder, the picture encoder, and the masks decoder. The first goal of the immediate encoder is to encode the arbitrary formed masks, enter factors and bins, and free type textual content with positional data. The picture encoder is a heavy ViT or imaginative and prescient transformer based mostly community that extracts the enter picture into embeddings. The mannequin makes use of totally different networks to course of the geometric and the textual content prompts. Lastly, the masks decoder comprises a two-way transformer that receives the output of the immediate and the picture encoder to generate the ultimate masks prediction. With the dataset, the SAM framework demonstrates outstanding prime quality segmentation capabilities for objects no matter their form and class. Moreover, the Phase Something Mannequin demonstrates outstanding efficiency and effectivity throughout zero-shot downstream imaginative and prescient duties together with object proposal, edge detection, textual content to masks prediction, and occasion segmentation. Owing to its prime quality segmentation talents, and versatile immediate choices, the SAM frameworks type the inspiration for imaginative and prescient functions. With that being mentioned, one can’t ignore the excessive computational requirement of the standard SAM structure with numerous parameters making it virtually unattainable for builders to deploy SAM based mostly functions on units with constrained sources.
Data Distillation
Data distillation is a vital strategy to spice up the efficiency of compact networks through the coaching section. The data distillation technique that makes use of the output of the trainer community to oversee the coaching of the light-weight pupil community. The data distillation technique might be cut up into two subcategories: distillation for intermediate options, and distillation for community outputs, with a majority of analysis work round data distillation specializing in picture classification duties.
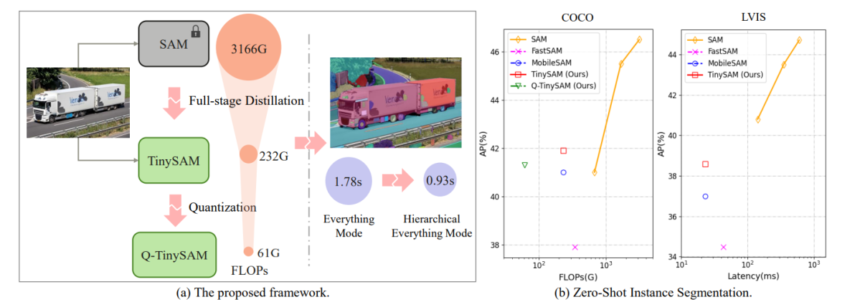
With that being mentioned, the next determine demonstrates the generic structure of the TinySAM framework together with the efficiency overview on zero-shot occasion segmentation duties.

Within the first stage, the TinySAM framework implements data distillation designed particularly for the SAM framework, and to activate the distillation course of additional, the mannequin makes use of a web-based laborious immediate sampling to mine the laborious data to the coed community from the trainer community. Within the second stage, the TinySAM framework adapts the post-training quantization technique to promptable segmentation duties and implements it on the light-weight pupil community. Lastly, the mannequin implements the hierarchical section every part inference mode designed for segmentation duties leading to doubling the inference pace with negligible accuracy loss.
Full-Stage Data Distillation
As talked about earlier, the Phase Something Mannequin consists of three sub-networks at its core: the immediate encoder, the picture encoder, and the masks decoder, with the picture encoder element constructed on a imaginative and prescient transformer, and having excessive computational necessities. To sort out this challenge, the MobileSAM framework changed the imaginative and prescient transformer with a TinyViT or Tiny Imaginative and prescient Transformer, though the substitution wasn’t efficient given the numerous efficiency decay. To make sure no efficiency decay, the TinySAM framework implements a full stage data distillation technique that guides the light-weight picture encoder from the training stage to the a number of data stage. Along with the standard loss between the ground-truth labels and the anticipated outcomes, the TinySAM framework introduces quite a few distillation losses throughout totally different phases as proven within the following determine.

Quantization
Mannequin Quantization is a well-liked strategy in laptop imaginative and prescient frameworks, and is used to compress the mannequin by quantizing weights or activations from greater to decrease bandwidth in an try to cut back computational complexity and storage necessities with out degrading the output high quality considerably.
The first goal of quantization in TinySAM is to challenge the floating level tensor to the bit integer tensor utilizing a scaling issue with the metric for measuring the gap between the matrix multiplication and the quantized matrix taking part in an important function for optimizing the scaling issue.
Hierarchical Phase Something
The Phase Something Mannequin proposes to make use of an automated masks generator that samples factors as a grid to section every part within the picture. Nevertheless, it has been indicated that using dense level grid leads to over-fine grained segmentation outputs and the method requires large computational necessities and incurs excessive operational prices. Moreover, on one finish, too many sampling factors for a whole object may end in totally different sections of the article to be segmented incorrectly as separate masks whereas on the opposite finish, the time value of the every part mode inference is primarily because of the purpose that the picture encoder has been shrinkled considerably. To scale back the operational value of the every part mode, the TinySAM framework makes use of a hierarchical masks technology strategy, with the distinction within the technique with the unique SAM framework demonstrated within the following picture.

Completely different from the strategy applied within the authentic SAM framework, the TinySAM mannequin makes use of solely 25% factors on both sides, thus using just one/16 of the obtainable factors within the authentic setting. The mannequin then infers the masks decoder and the immediate encoder with these prompts and will get the output. The mannequin then filters some masks with confidence exceeding a sure threshold, and masks the corresponding areas as areas for potential ultimate predictions. For the reason that mannequin treats these areas because the segmentation results of cases with excessive confidence, it has no have to generate level prompts. The technique not solely helps in stopping over-fine grained segmentation of the article but it surely additionally helps in bringing down the operational prices and computational necessities considerably. The framework then merges and post-processes the outcomes of those two rounds to acquire the ultimate masks.
TinySAM : Experiments and Outcomes
To speed up the distillation course of, the TinySAM framework computes and shops the picture embeddings from the trainer community upfront, owing to which it isn’t obligatory for the mannequin to compute the heavy picture encoder of the trainer community repeatedly through the coaching section anymore. For put up coaching quantization, the TinySAM framework quantizes all of the matrix multiply layers, the convolution layers, the deconvolution layers, and the linear layers, with the mannequin utilizing chanel-wise scaling components for each the convolution and the deconvolution layers. For the matrix multiply layers, the mannequin implements head-wise scaling components whereas for the linear layers, the mannequin implements linear-wise scaling components. The mannequin additionally conducts analysis on zero-shot downstream duties.
As an example segmentation duties in a zero-shot setting, the TinySAM framework follows the experimental settings of its predecessor, the Phase Something Mannequin, and makes use of object detection outcomes of the Imaginative and prescient Transformer Det-H or VitDet-H framework for example segmentation. As demonstrated within the following picture, the TinySAM framework outperforms present strategies when it comes to occasion segmentation accuracy and the FLOPs rating.

Moreover, the qualitative efficiency of the TinySAM mannequin is demonstrated within the following picture for zero-shot occasion segmentation with the inexperienced field representing the field prompts.

When it comes to zero-shot factors legitimate masks analysis, the TinySAM mannequin outperforms the MobileSAM framework considerably on totally different datasets, and delivers considerably higher outcomes when a fewer variety of factors are utilized as prompts by the framework.

Moreover, the next desk summarizes the outcomes of the acceleration and reduce in computational necessities achieved on account of the hierarchical every part mode technique. The mannequin applies the identical stability rating and threshold worth with totally different methods for a good comparability, and the outcomes are summarized beneath.

Closing Ideas
On this article, we’ve got talked about TinySAM, a proposed framework that pushes the boundaries for segmenting any process, and obtains an environment friendly mannequin structure with much less computational necessities and accuracy at par with the unique SAM framework. TinySAM or the Tiny Phase Something Mannequin that maintains and delivers the zero-shot efficiency of the unique framework. The TinySAM framework first implements a full-stage data distillation technique that makes use of on-line laborious prompts to distill a light-weight pupil mannequin. The TinySAM framework then adapts the post-training quantization to promptable segmentation duties that additional helps in lowering the computational necessities. Moreover, the framework additionally goals to section every part hierarchically that nearly doubles the inference pace with out affecting the efficiency.


Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.