
Textual content-generating AI is one factor. However AI fashions that perceive photos in addition to textual content can unlock highly effective new functions.
Take, for instance, Twelve Labs. The San Francisco-based startup trains AI fashions to — as co-founder and CEO Jae Lee places it — “remedy advanced video-language alignment issues.”
“Twelve Labs was based … to create an infrastructure for multimodal video understanding, with the primary endeavor being semantic search — or ‘CTRL+F for movies,’” Lee advised TechCrunch in an electronic mail interview. “The imaginative and prescient of Twelve Labs is to assist builders construct packages that may see, pay attention and perceive the world as we do.”
Twelve Labs’ fashions try to map pure language to what’s occurring inside a video, together with actions, objects and background sounds, permitting builders to create apps that may search by movies, classify scenes and extract matters from inside these movies, mechanically summarize and cut up video clips into chapters, and extra.
Lee says that Twelve Labs’ expertise can drive issues like advert insertion and content material moderation — for example, determining which movies displaying knives are violent versus educational. It may also be used for media analytics, Lee added, and to mechanically generate spotlight reels — or weblog submit headlines and tags — from movies.
I requested Lee concerning the potential for bias in these fashions, on condition that it’s well-established science that fashions amplify the biases within the information on which they’re skilled. For instance, coaching a video understanding mannequin on principally clips of native information — which frequently spends a variety of time masking crime in a sensationalized, racialized method — may trigger the mannequin to be taught racist as well as sexist patterns.
Lee says that Twelve Labs strives to fulfill inside bias and “equity” metrics for its fashions earlier than releasing them, and that the corporate plans to launch model-ethics-related benchmarks and information units sooner or later. However he had nothing to share past that.

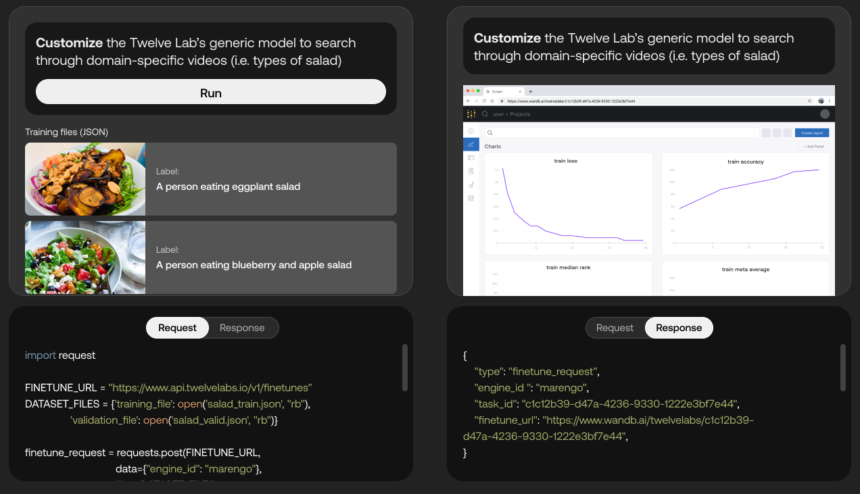
Mockup of API for effective tuning the mannequin to work higher with salad-related content material. Picture Credit: Twelve Labs
“By way of how our product is completely different from massive language fashions [like ChatGPT], ours is particularly skilled and constructed to course of and perceive video, holistically integrating visible, audio and speech elements inside movies,” Lee mentioned. “We’ve got actually pushed the technical limits of what’s potential for video understanding.”
Google is creating an identical multimodal mannequin for video understanding known as MUM, which the corporate’s utilizing to energy video suggestions throughout Google Search and YouTube. Past MUM, Google — in addition to Microsoft and Amazon — supply API-level, AI-powered providers that acknowledge objects, locations and actions in movies and extract wealthy metadata on the body degree.
However Lee argues that Twelve Labs is differentiated each by the standard of its fashions and the platform’s fine-tuning options, which permit clients to automate the platform’s fashions with their very own information for “domain-specific” video evaluation.
On the mannequin entrance, Twelve Labs is in the present day unveiling Pegasus-1, a brand new multimodal mannequin that understands a spread of prompts associated to whole-video evaluation. For instance, Pegasus-1 will be prompted to generate an extended, descriptive report a couple of video or only a few highlights with timestamps.
“Enterprise organizations acknowledge the potential of leveraging their huge video information for brand new enterprise alternatives … Nevertheless, the restricted and simplistic capabilities of typical video AI fashions usually fall in need of catering to the intricate understanding required for many enterprise use circumstances,” Lee mentioned. “Leveraging highly effective multimodal video understanding basis fashions, enterprise organizations can attain human-level video comprehension with out guide evaluation.”
Since launching in personal beta in early Could, Twelve Labs’ person base has grown to 17,000 builders, Lee claims. And the corporate’s now working with numerous corporations — it’s unclear what number of; Lee wouldn’t say — throughout industries together with sports activities, media and leisure, e-learning and safety, together with the NFL.
Twelve Labs can also be persevering with to boost cash — and essential a part of any startup enterprise. At this time, the corporate introduced that it closed a $10 million strategic funding spherical from Nvidia, Intel and Samsung Subsequent, bringing its complete raised to $27 million.
“This new funding is all about strategic companions that may speed up our firm in analysis (compute), product and distribution,” Lee mentioned. “It’s gas for ongoing innovation, based mostly on our lab’s analysis, within the area of video understanding in order that we are able to proceed to carry essentially the most highly effective fashions to clients, no matter their use circumstances could also be … We’re shifting the business ahead in ways in which free corporations as much as do unimaginable issues.”