

Since Ian Goodfellow offers machines the reward of creativeness by creating a robust AI idea GANs, researchers begin to enhance the technology photographs each on the subject of constancy and variety. But a lot of the work targeted on enhancing the discriminator, and the mills proceed to function as black packing containers till researchers from NVIDIA AI launched StyleGAN from the paper A Model-Primarily based Generator Structure for Generative Adversarial Networks, which is predicated on ProGAN from the paper Progressive Rising of GANs for Improved High quality, Stability, and Variation.
This text is about among the best GANs at this time, StyleGAN, We are going to break down its parts and perceive what’s made it beat most GANs out of the water on quantitative and qualitative analysis metrics, each on the subject of constancy and variety. One putting factor is that styleGAN can truly change finer grain points of the outputting picture, for instance, if you wish to generate faces you possibly can add some noise to have a wisp of hair tucked again, or falling over.
StyleGAN Overview
On this part, we’ll find out about StyleGAN’s comparatively new structure that is thought-about an inflection level enchancment in GAN, significantly in its skill to generate extraordinarily sensible photographs.
We are going to begin by going over StyleGAN, major targets, then we’ll speak about what the model in StyleGAN means, and eventually, we’ll get an introduction to its structure in particular person parts.
StyleGAN targets
- Produce high-quality, high-resolution photographs.
- Larger range of photographs within the output.
- Elevated management over picture options. And this may be by including options like hats or sun shades on the subject of producing faces, or mixing kinds from two completely different generated photographs collectively
Model in StyleGANs
The StyleGAN generator views a picture as a group of “kinds,” the place every model regulates the results on a particular scale. Relating to producing faces:
- Coarse kinds management the results of a pose, hair, and face form.
- Middles kinds management the results of facial options, and eyes.
- Nice kinds management the results of coloration schemes.

Principal parts of StyleGAN
Now let’s examine how the StyleGAN generator differs from a standard GAN generator that we may be extra acquainted with.
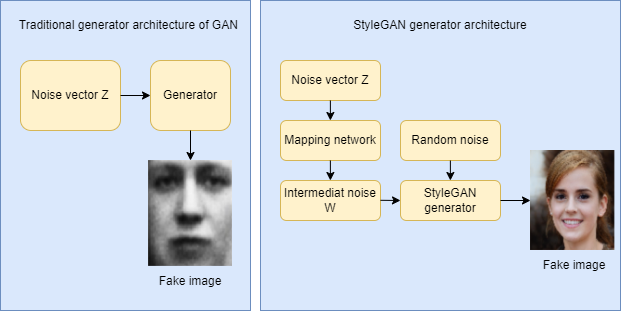
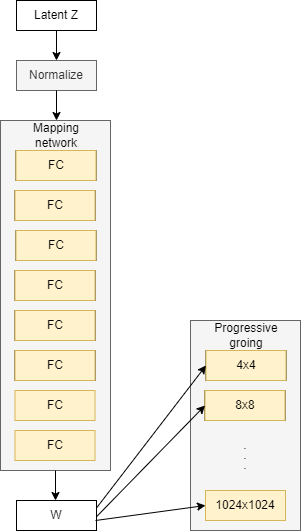
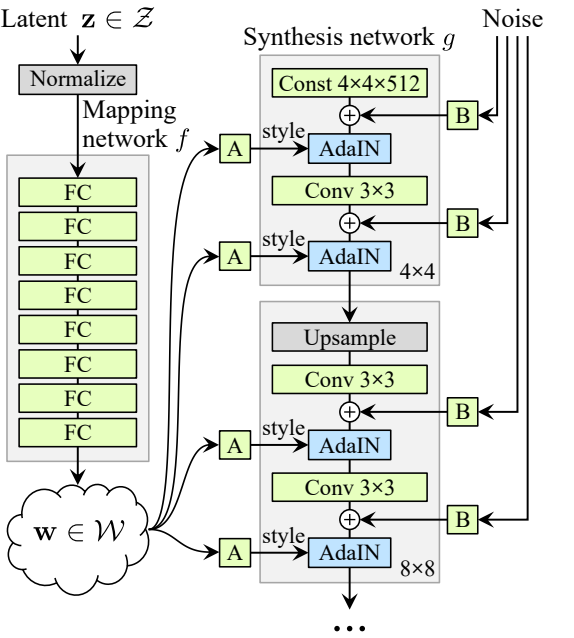
In a standard GAN generator, we take a noise vector (let’s identify it z) into the generator and the generator then outputs a picture. Now in StyleGAN, as a substitute of feeding the noise vector z instantly into the generator, it goes by means of a mapping community to get an intermediate noise vector (let’s identify it W) and extract kinds from it. That then will get injected by means of an operation referred to as adaptive occasion normalization(AdaIN for brief) into the StyleGAN generator a number of instances to provide a pretend picture. And in addition there’s an additional random noise that is handed in so as to add some options to the pretend picture (corresponding to shifting a wisp of hair in several methods).
The ultimate necessary part of StyleGAN is progressive rising. Which slowly grows the picture decision being generated by the generator and evaluated by the discriminator over the method of coaching. And progressive rising originated with ProGAN.
So this was only a high-level introduction to StyleGAN, now let’s get dive deeper into every of the StyleGAN parts (Progressive rising, Noice mapping community, and adaptive occasion normalization) and the way they actually work
Progressive rising
In conventional GANs we ask the generator to generate instantly a hard and fast decision like 256 by 256. If you concentrate on it is a type of a difficult job to instantly output high-quality photographs.
For progressive rising we first ask the generator to output a really low-resolution picture like 4 by 4, and we practice the discriminator to additionally be capable to distinguish on the identical decision, after which when the generator succeded with this job we up the extent and we ask it to output the double of the decision (eight by eight), and so forth till we attain a very excessive decision 1024 by 1024 for instance.
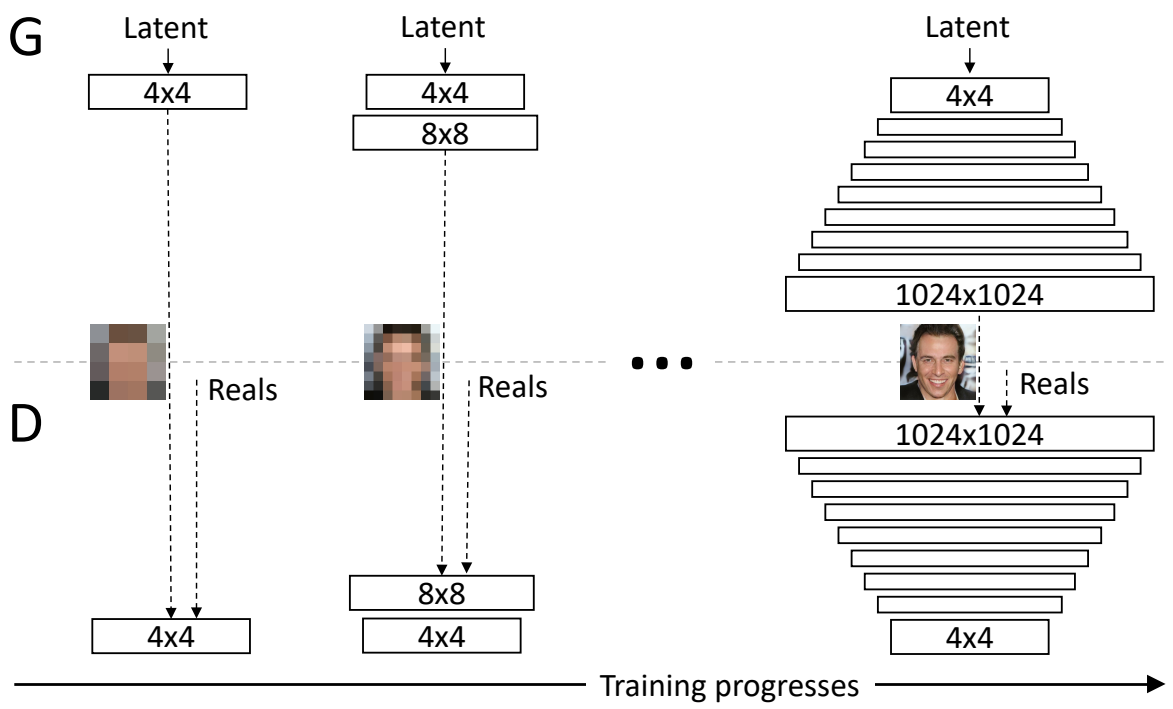
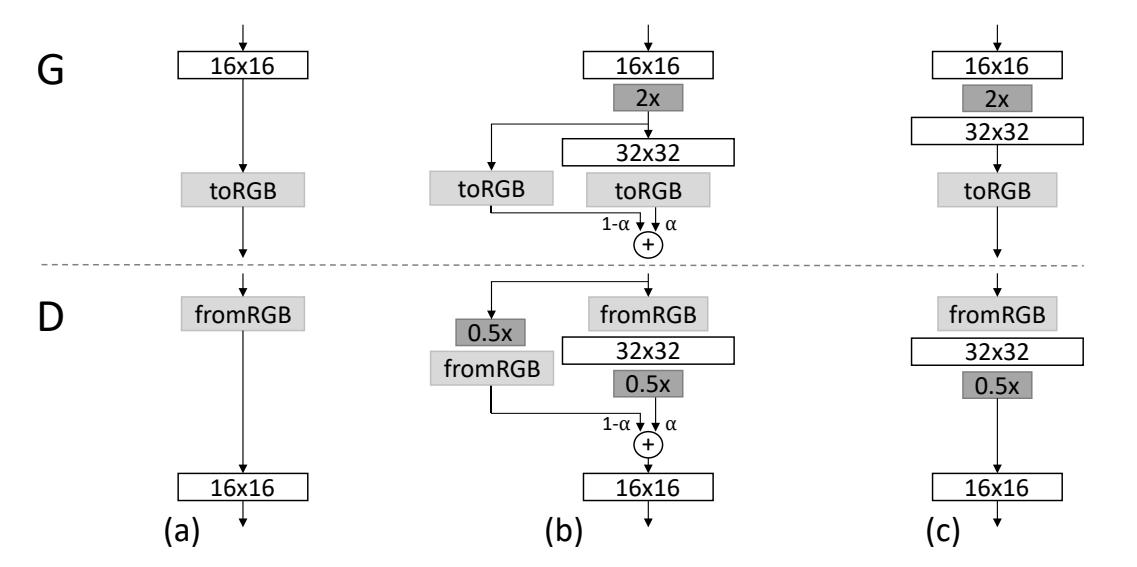
Progressive rising is extra gradual than simple doubling in measurement instantly, once we wish to generate a double-size picture, the brand new layers are easily light in. This fading in is managed by a parameter α, which is linearly interpolated from 0 to 1 over the course of many coaching iterations. As you possibly can see within the determine beneath, the ultimate generated picture is calculated with this system [(1−α)×UpsampledLayer+(α)×ConvLayer]
Noise Mapping Community
Now we’ll study concerning the Noise Mapping Community, which is a singular part of StyleGAN and helps to regulate kinds. First, we’ll check out the construction of the noise mapping community. Then the explanation why it exists, and eventually the place its output the intermediate vector truly goes.
The noise mapping community truly takes the noise vector Z and maps it into an intermediate noise vector W. And this noise mapping community consists of eight totally related layers with activations in between, often known as a multilayer perceptron or MLP (The authors discovered that rising the depth of the mapping community tends to make the coaching unstable). So it is a fairly easy neural community that takes the Z noise vector, which is 512 in measurement. And maps it into W intermediate noise issue, which remains to be 512 in measurement, so it simply modifications the values.
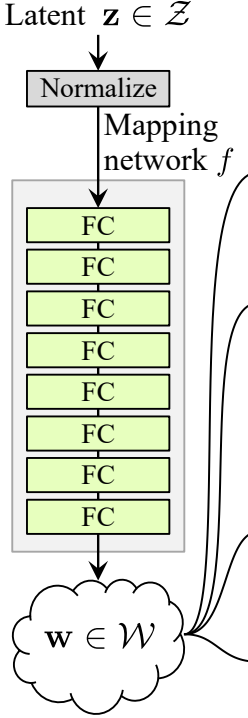
The motivation behind that is that mapping the noise vector will truly get us a extra disentangled illustration. In conventional GANs when the noise vector Z goes into the generator. The place we modify one among these Z vector values we will truly change lots of completely different options in our output. And this isn’t what the authors of StyleGANs need, as a result of one among their important targets is to extend management over picture options, in order that they give you the Noise Mapping Community that permits for lots of fine-grained management or feature-level management, and because of that we will now, for instance, change the eyes of a generated particular person, add glasses, equipment, and rather more issues.
Now let’s uncover the place the noise mapping community truly goes. So we see earlier than progressive rising, the place the output begins from low-resolution and doubles in measurement till attain the decision that we would like. And the noise mapping community injects into completely different blocks that progressively develop.
Adaptive Occasion Normalization (AdaIN)
Now we’ll have a look at adaptive occasion normalization or AdaIN for brief and take a bit nearer at how the intermediate noise vector is definitely built-in into the community. So first, We are going to speak about occasion normalization and we’ll evaluate it to batch normalization, which we’re extra acquainted with. Then we’ll speak about what adaptive occasion normalization means, and in addition the place and why AdaIN or Adaptive Occasion Normalization is used.
So we already speak about progressive rising, and we additionally study concerning the noise mapping community, the place it injects W into completely different blocks that progressively develop. Nicely, if you’re acquainted with ProGAN you realize that in every block we up-sample and do two convolution layers to assist study extra options, however this isn’t all within the StyleGAN generator, we add AdaIN after every convolutional layer.
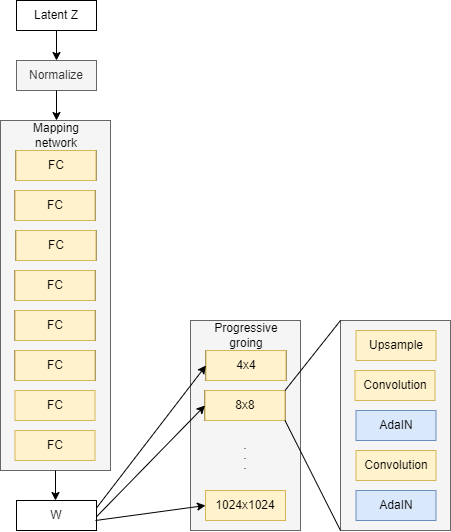
Step one of adaptive occasion normalization(AdaIN) would be the occasion normalization half. if you happen to keep in mind normalization is it takes the outputs from the convolutional layers X and places it at a imply of 0 and a regular deviation of 1. However that is not it, as a result of it is truly not primarily based on the batch essentially, which we may be extra acquainted with. The place batch norm we glance throughout the peak and width of the picture, we have a look at one channel, so amongst RGB, we solely have a look at R for instance, and we have a look at all examples within the mini-batch. After which, we get the imply and customary deviation primarily based on one channel in a single batch. After which we additionally do it for the following batch. However occasion normalization is a little bit bit completely different. we truly solely have a look at one instance or one occasion(an instance is often known as an occasion). So if we had a picture with channels RGB, we solely have a look at B for instance and get the imply and customary deviation solely from that blue channel. Nothing else, no extra photographs in any respect, simply getting the statistics from simply that one channel, one occasion. And normalizing these values primarily based on their imply and customary deviation. The equation beneath represents that.
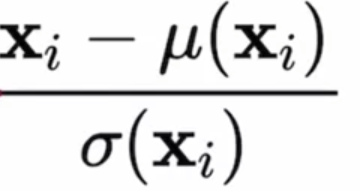
the place:
Xi: Occasion i from the outputs from the convolutional layers X.
µ(Xi): imply of occasion Xi.
𝜎(Xi): Normal deviation of occasion Xi.
So that is the occasion normalization half. And the place the adaptive half is available in is to use adaptive kinds to the normalized set of values. And the occasion normalization most likely makes a little bit bit extra sense than nationalization, as a result of it truly is about each single pattern we’re producing, versus essentially the batch.
The adaptive kinds are coming from the intermediate noise vector W which is inputted into a number of areas of the community. And so adaptive occasion normalization is the place W will are available in, however truly circuitously inputting there. As a substitute, it goes by means of discovered parameters, corresponding to two totally related layers, and produces two parameters for us. One is ys which stands for scale, and the opposite is yb, which stands for bias, and these statistics are then imported into the AdaIN layers. See the system beneath.
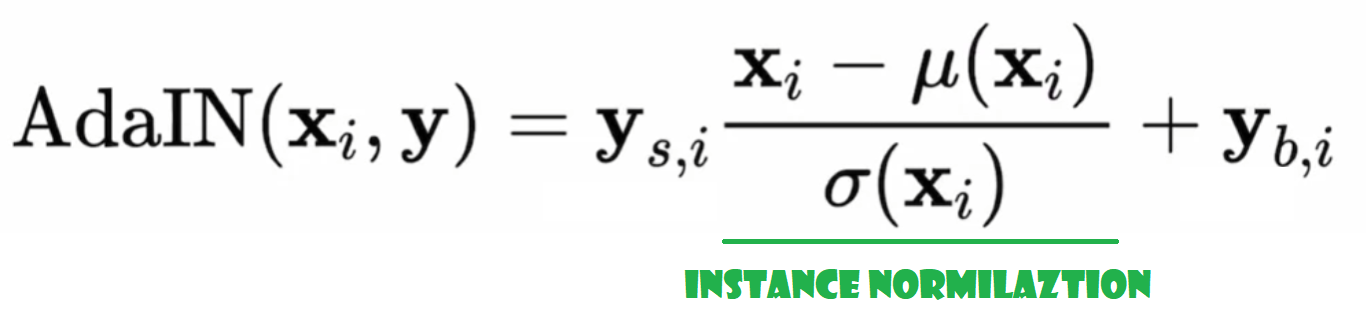
All of the parts that we see are pretty necessary to StyleGAN. Authors did ablation research to a number of of them to know primarily how helpful they’re by taking them out and seeing how the mannequin does with out them. And so they discovered that each part is kind of crucial up.
Model mixing and Stochastic variation
On this part, we’ll find out about controlling coarse and positive kinds with StyleGAN, utilizing two completely different strategies. The primary is model mixing for elevated range throughout coaching and inference, and that is mixing two completely different noise vectors that get inputted into the mannequin. The second is including stochastic noise for extra variation in our photographs. Including small finer particulars, corresponding to the place a wisp of hair grows.
Model mixing
Though W is injected in a number of locations within the community, it would not truly should be the identical W every time we will have a number of W’s. We are able to pattern a Z that goes by means of the mapping community, we get a W, its related W1, and we injected that into the primary half of the community for instance. Do not forget that goes in by means of AdaIN. Then we pattern one other Z, let’s identify it Z2, and that will get us W2, after which we put that into the second half of the community for instance. The switch-off between W1 and W2 can truly be at any level, it would not should be precisely the center for half and half the community. This can assist us management what variation we like. The later the change, the finer the options that we get from W2. This improves our range as nicely since our mannequin is educated like this, so that’s always mixing completely different kinds and it could possibly get extra numerous outputs. The determine beneath is an instance utilizing generated human faces from StyleGAN.

Stochastic variation
Stochastic variations are used to output completely different generated photographs with one image generated by including a further noise to the mannequin.
With a view to do this there are two easy steps:
- Pattern noise from a traditional distribution.
- Concatenate noise to the output of conv layer X earlier than AdaIN.
The determine beneath is an instance utilizing generated human faces from StyleGAN. The writer of StyleGAN generates two faces on the left(the infant on the backside would not look very actual. Not all outputs look tremendous actual) then they use stochastic variations to generate a number of completely different photographs from them, you possibly can see the zoom-in into the particular person’s pair that is generated, it is simply so slight by way of the association of the particular person’s hair.

Outcomes



The pictures generated by StyleGAN have higher range, they’re high-quality, high-resolution, and look so sensible that you’d assume they’re actual.
Conclusion
On this article, we undergo the StyleGAN paper, which is predicated on ProGAN (They’ve the identical discriminator structure and completely different generator structure).
The fundamental blocks of the generator are the progressive rising which primarily grows the generated output over time from smaller outputs to bigger outputs. After which we’ve the noise mapping community which takes Z. That is sampled from a traditional distribution and places it by means of eight totally related layers separated by sigmoids or some type of activation. And to get the intermediate W noise vector that’s then inputted into each single block of the generator twice. After which we discovered about AdaIN, or adaptive occasion normalization, which is used to take W and apply kinds at varied factors within the community. We additionally discovered about model mixing, which samples completely different Zs to get completely different Ws, which then places completely different Ws at completely different factors within the community. So we will have a W1 within the first half and a W2 within the second half. After which the generated output will likely be a mixture of the 2 photographs that had been generated by simply W1 or simply W2. And at last, we discovered about stochastic noise, which informs small element variations to the output.
Hopefully, it is possible for you to to observe the entire steps and get an excellent understanding of StyleGAN, and you’re able to sort out the implementation, you’ll find it on this article the place I make a clear, easy, and readable implementation of it to generate some style.