
Scaling up representations of textual content and visuals has been a serious focus of analysis lately. Developments and analysis carried out within the current previous have led to quite a few revolutions in language studying and imaginative and prescient. Nevertheless, regardless of the recognition of scaling textual content and visible representations, the scaling of representations for 3D scenes and objects has not been sufficiently mentioned.
In the present day, we are going to focus on Uni3D, a 3D basis mannequin that goals to discover unified 3D representations. The Uni3D framework employs a 2D-initialized ViT framework, pretrained end-to-end, to align image-text options with their corresponding 3D level cloud options.
The Uni3D framework makes use of pretext duties and a easy structure to leverage the abundance of pretrained 2D fashions and image-text-aligned fashions as initializations and targets, respectively. This method unleashes the complete potential of 2D fashions and techniques to scale them to the 3D world.
On this article, we are going to delve deeper into 3D laptop imaginative and prescient and the Uni3D framework, exploring the important ideas and the structure of the mannequin. So, let’s start.
Up to now few years, laptop imaginative and prescient has emerged as some of the closely invested domains within the AI business. Following important developments in 2D laptop imaginative and prescient frameworks, builders have shifted their focus to 3D laptop imaginative and prescient. This area, significantly 3D illustration studying, merges facets of laptop graphics, machine studying, laptop imaginative and prescient, and arithmetic to automate the processing and understanding of 3D geometry. The speedy improvement of 3D sensors like LiDAR, together with their widespread functions within the AR/VR business, has resulted in 3D illustration studying gaining elevated consideration. Its potential functions proceed to develop each day.
Though present frameworks have proven outstanding progress in 3D mannequin structure, task-oriented modeling, and studying aims, most discover 3D structure on a comparatively small scale with restricted knowledge, parameters, and process eventualities. The problem of studying scalable 3D representations, which might then be utilized to real-time functions in numerous environments, stays largely unexplored.
Shifting alongside, prior to now few years, scaling giant language fashions which might be pre-trained has helped in revolutionizing the pure language processing area, and up to date works have indicated a translation within the progress to 2D from language utilizing knowledge and mannequin scaling which makes method for builders to strive & reattempt this success to study a 3D illustration that may be scaled & be transferred to functions in actual world.
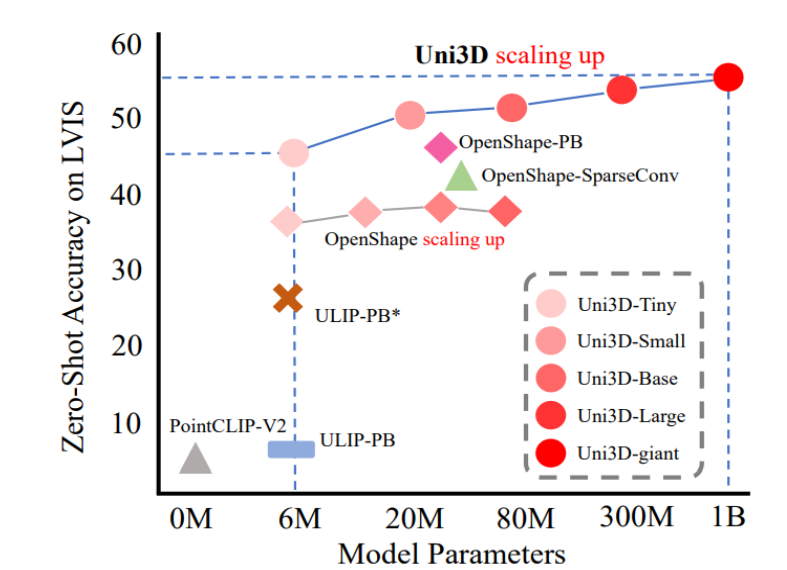
Uni3D is a scalable and unified pretraining 3D framework developed with the purpose to study large-scale 3D representations that checks its limits on the scale of over a billion parameters, over 10 million photographs paired with over 70 million texts, and over 1,000,000 3D shapes. The determine beneath compares the zero-shot accuracy towards parameters within the Uni3D framework. The Uni3D framework efficiently scales 3D representations from 6 million to over a billion.

The Uni3D framework consists of a 2D ViT or Imaginative and prescient Transformer because the 3D encoder that’s then pre-trained end-to-end to align the image-text aligned options with the 3D level cloud options. The Uni3D framework makes use of pretext duties and easy structure to leverage the abundance of pretrained 2D fashions and picture textual content aligned fashions as initialization and targets respectively, thus unleashing the complete potential of 2D fashions, and techniques to scale them to the 3D world. The flexibleness & scalability of the Uni3D framework is measured by way of
- Scaling the mannequin from 6M to over a billion parameters.
- 2D initialization to textual content supervised from visible self-supervised studying.
- Textual content-image goal mannequin scaling from 150 million to over a billion parameters.
Underneath the versatile and unified framework supplied by Uni3D, builders observe a coherent increase within the efficiency in relation to scaling every part. The massive-scale 3D illustration studying additionally advantages immensely from the sharable 2D and scale-up methods.
As it may be seen within the determine beneath, the Uni3D framework shows a lift within the efficiency when in comparison with prior artwork in few-shot and zero-shot settings. It’s value noting that the Uni3D framework returns a zero-shot classification accuracy rating of over 88% on ModelNet which is at par with the efficiency of a number of cutting-edge supervision strategies.

Moreover, the Uni3D framework additionally delivers prime notch accuracy & efficiency when performing different consultant 3D duties like half segmentation, and open world understanding. The Uni3D framework goals to bridge the hole between 2D imaginative and prescient and 3D imaginative and prescient by scaling 3D foundational fashions with a unified but easy pre-training method to study extra strong 3D representations throughout a big selection of duties, that may in the end assist in the convergence of 2D and 3D imaginative and prescient throughout a big selection of modalities.
Uni3D : Associated Work
The Uni3D framework attracts inspiration, and learns from the developments made by earlier 3D illustration studying, and Foundational fashions particularly beneath completely different modalities.
3D Illustration Studying
The 3D illustration studying technique makes use of cloud factors for 3D understanding of the item, and this area has been explored by builders quite a bit within the current previous, and it has been noticed that these cloud factors might be pre-trained beneath self-supervision utilizing particular 3D pretext duties together with masks level modeling, self-reconstruction, and contrastive studying.
It’s value noting that these strategies work with restricted knowledge, they usually typically don’t examine multimodal representations to 3D from 2D or NLP. Nevertheless, the current success of the CLIP framework that returns excessive effectivity in studying visible ideas from uncooked textual content utilizing the contrastive studying technique, and additional seeks to study 3D representations by aligning picture, textual content, and cloud level options utilizing the identical contrastive studying technique.
Basis Fashions
Builders have exhaustively been engaged on designing basis fashions to scale up and unify multimodal representations. For instance, within the NLP area, builders have been engaged on frameworks that may scale up pre-trained language fashions, and it’s slowly revolutionizing the NLP business. Moreover, developments might be noticed within the 2D imaginative and prescient area as nicely as a result of builders are engaged on frameworks that use knowledge & mannequin scaling strategies to assist in the progress of language to 2D fashions, though such frameworks are tough to duplicate for 3D fashions due to the restricted availability of 3D knowledge, and the challenges encountered when unifying & scaling up the 3D frameworks.
By studying from the above two work domains, builders have created the Uni3D framework, the primary 3D basis mannequin with over a billion parameters that makes use of a unified ViT or Imaginative and prescient Transformer structure that permits builders to scale the Uni3D mannequin utilizing unified 3D or NLP methods for scaling up the fashions. Builders hope that this technique will enable the Uni3D framework to bridge the hole that at present separates 2D and 3D imaginative and prescient together with facilitating multimodal convergence.
Uni3D : Technique and Structure

The above picture demonstrates the generic overview of the Uni3D framework, a scalable and unified pre-training 3D framework for large-scale 3D illustration studying. Builders make use of over 70 million texts, and 10 million photographs paired with over 1,000,000 3D shapes to scale the Uni3D framework to over a billion parameters. The Uni3D framework makes use of a 2D ViT or Imaginative and prescient Transformer as a 3D encoder that’s then skilled end-to-end to align the text-image knowledge with the 3D cloud level options, permitting the Uni3D framework to ship the specified effectivity & accuracy throughout a big selection of benchmarks. Allow us to now have an in depth have a look at the working of the Uni3D framework.
Scaling the Uni3D Framework
Prior research on cloud level illustration studying have historically centered closely on designing specific mannequin architectures that ship higher efficiency throughout a variety of functions, and work on a restricted quantity of information because of small-scale datasets. Nevertheless, current research have tried exploring the potential for utilizing scalable pre-training in 3D however there have been no main outcomes because of the supply of restricted 3D knowledge. To unravel the scalability downside of 3D frameworks, the Uni3D framework leverages the ability of a vanilla transformer construction that nearly mirrors a Imaginative and prescient Transformer, and might resolve the scaling issues by utilizing unified 2D or NLP scaling-up methods to scale the mannequin dimension.