

Imaginative and prescient Transformer (ViT) have lately emerged as a aggressive various to Convolutional Neural Networks (CNNs) which can be at present state-of-the-art in several picture recognition laptop imaginative and prescient duties. ViT fashions outperform the present state-of-the-art (CNN) by virtually x4 when it comes to computational effectivity and accuracy.
Transformer fashions have turn out to be the de-facto establishment in Pure Language Processing (NLP). For instance, the favored ChatGPT AI chatbot is a transformer-based language mannequin. Particularly, it’s based mostly on the GPT (Generative Pre-trained Transformer) structure, which makes use of self-attention mechanisms to mannequin the dependencies between phrases in a textual content.
In laptop imaginative and prescient analysis, there has lately been an increase in curiosity in Imaginative and prescient Transformer (ViTs) and Multilayer Perceptrons (MLPs).
This text will cowl the next matters:
- What’s a Imaginative and prescient Transformer (ViT)?
- Utilizing ViT fashions in Picture Recognition
- How do Imaginative and prescient Transformers work?
- Use Instances and functions of Imaginative and prescient Transformers
About us: Viso.ai offers the main end-to-end Pc Imaginative and prescient Platform Viso Suite. Our resolution allows organizations worldwide to seamlessly construct and ship video picture recognition functions. Get a demo to your firm.
Imaginative and prescient Transformer (ViT) in Picture Recognition
Whereas the Transformer structure has turn out to be the very best customary for duties involving Pure Language Processing (NLP), its use instances referring to Pc Imaginative and prescient (CV) stay just a few. In lots of laptop imaginative and prescient duties, consideration is both used along with convolutional networks (CNN) or used to substitute sure facets of convolutional networks whereas maintaining their total composition intact. In style picture recognition algorithms embody ResNet, VGG, YOLOv3, and YOLOv7.
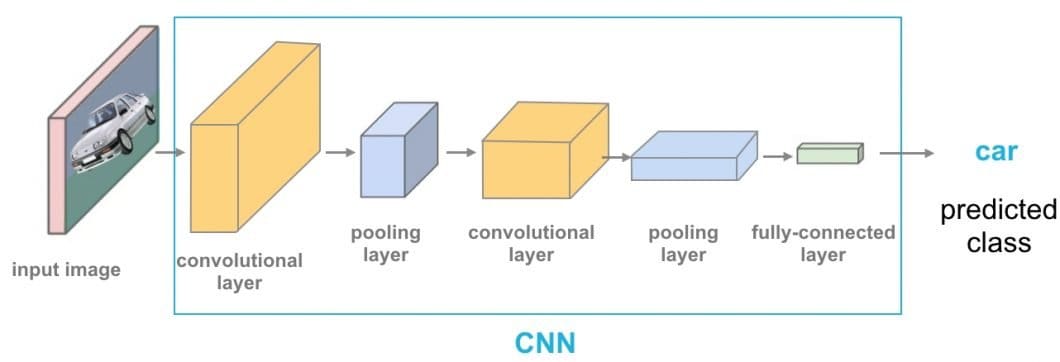
Nevertheless, this dependency on CNN shouldn’t be obligatory, and a pure transformer utilized on to sequences of picture patches can work exceptionally nicely on picture classification duties.
Efficiency of Imaginative and prescient Transformers in Pc Imaginative and prescient
Imaginative and prescient Transformers (ViT) have lately achieved extremely aggressive performance in benchmarks for a number of laptop imaginative and prescient functions, corresponding to picture classification, object detection, and semantic picture segmentation.
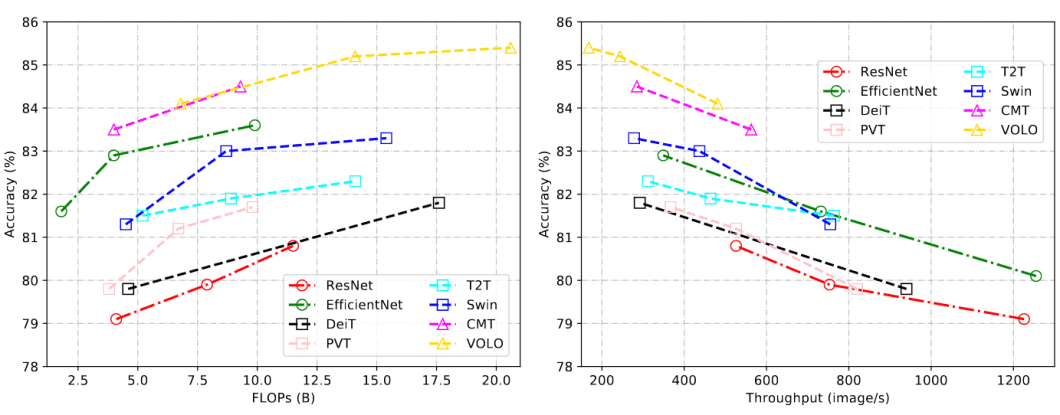
CSWin Transformer is an environment friendly and efficient Transformer-based spine for general-purpose imaginative and prescient duties that makes use of a brand new method referred to as “Cross-Formed Window self-attention” to research completely different elements of the picture on the similar time, which makes it a lot quicker.
The CSWin Transformer has surpassed earlier state-of-the-art strategies, such because the Swin Transformer. In benchmark duties, CSWIN achieved wonderful performance, together with 85.4% Prime-1 accuracy on ImageNet-1K, 53.9 field AP and 46.4 masks AP on the COCO detection activity, and 52.2 mIOU on the ADE20K semantic segmentation activity.
What’s a Imaginative and prescient Transformer (ViT)?
The Imaginative and prescient Transformer (ViT) mannequin structure was launched in a analysis paper printed as a convention paper at ICLR 2021 titled “An Picture is Value 16*16 Phrases: Transformers for Picture Recognition at Scale”. It was developed and printed by Neil Houlsby, Alexey Dosovitskiy, and 10 extra authors of the Google Analysis Mind Crew.
The fine-tuning code and pre-trained ViT fashions are out there on the GitHub of the Google Analysis workforce. You discover them here. The ViT fashions have been pre-trained on the ImageNet and ImageNet-21k datasets.
Origin and historical past of imaginative and prescient transformer fashions
Within the following, we spotlight among the most vital imaginative and prescient transformers which were developed over time. They’re based mostly on the transformer structure, which was initially proposed for pure language processing (NLP) in 2017.
| Date | Mannequin | Description | Imaginative and prescient Transformer? |
|---|---|---|---|
| 2017 Jun | Transformer | A mannequin based mostly solely on an consideration mechanism. It demonstrated wonderful efficiency on NLP duties. | No |
| 2018 Oct | BERT | Pre-trained transformer fashions began dominating the NLP subject. | No |
| 2020 Could | DETR | DETR is a straightforward but efficient framework for high-level imaginative and prescient that views object detection as a direct set prediction downside. | Sure |
| 2020 Could | GPT-3 | The GPT-3 is a big transformer mannequin with 170B parameters that takes a major step in the direction of a common NLP mannequin. | No |
| 2020 Jul | iGPT | The transformer mannequin, initially developed for NLP, can be used for picture pre-training. | Sure |
| 2020 Oct | ViT | Pure transformer architectures which can be efficient for visible recognition. | Sure |
| 2020 Dec | IPT/SETR/CLIP | Transformers have been utilized to low-level imaginative and prescient, segmentation, and multimodality duties, respectively. | Sure |
| 2021 – right this moment | ViT Variants | There are a number of ViT variants, together with DeiT, PVT, TNT, Swin, and CSWin (2022). | Sure |
Are Transformers a Deep Studying technique?
A transformer in machine studying is a deep studying mannequin that makes use of the mechanisms of consideration, differentially weighing the importance of every a part of the enter sequence of knowledge. Transformers in machine studying are composed of a number of self-attention layers. They’re primarily used within the AI subfields of pure language processing (NLP) and laptop imaginative and prescient (CV).
Transformers in machine studying hold strong promises towards a generic studying technique that may be utilized to varied information modalities, together with the current breakthroughs in laptop imaginative and prescient attaining state-of-the-art customary accuracy with higher parameter effectivity.
Imaginative and prescient Transformer and Picture Classification
Picture classification is a basic activity in laptop imaginative and prescient that entails assigning a label to a picture based mostly on its content material. Through the years, deep convolutional neural networks (CNNs) like YOLOv7 have been the state-of-the-art technique for picture classification.
Nevertheless, current developments in transformer structure, which was initially launched for pure language processing (NLP), have proven nice promise in attaining aggressive leads to picture classification duties.
An instance is CrossViT, a cross-attention Imaginative and prescient Transformer for Picture Classification. Pc imaginative and prescient research signifies that when pre-trained with a enough quantity of knowledge, ViT fashions are no less than as strong as ResNet fashions.
Different papers confirmed that Imaginative and prescient Transformer Fashions have nice potential for privacy-preserving picture classification and outperform state-of-the-art strategies when it comes to robustness towards assaults and classification accuracy.
Distinction between CNN and ViT (ViT vs. CNN)
Imaginative and prescient Transformer (ViT) achieves outstanding outcomes in comparison with convolutional neural networks (CNN) whereas acquiring considerably fewer computational sources for pre-training. In comparability to convolutional neural networks (CNN), Imaginative and prescient Transformer (ViT) present a usually weaker inductive bias leading to elevated reliance on mannequin regularization or information augmentation (AugReg) when coaching on smaller datasets.
The ViT is a visible mannequin based mostly on the structure of a transformer initially designed for text-based duties. The ViT mannequin represents an enter picture as a sequence of picture patches, just like the sequence of phrase embeddings used when utilizing transformers to textual content, and instantly predicts class labels for the picture. ViT reveals a rare efficiency when skilled on sufficient information, breaking the efficiency of the same state-of-art CNN with 4x fewer computational sources.
These transformers have excessive success charges on the subject of NLP fashions and are actually additionally utilized to pictures for picture recognition duties. CNN use pixel arrays, whereas ViT splits the enter photos into visible tokens. The visible transformer divides a picture into fixed-size patches, accurately embeds every of them, and contains positional embedding as an enter to the transformer encoder. Furthermore, ViT models outperform CNNs by virtually 4 instances on the subject of computational effectivity and accuracy.
The self-attention layer in ViT makes it doable to embed info globally throughout the general picture. The mannequin additionally learns on coaching information to encode the relative location of the picture patches to reconstruct the construction of the picture.
The transformer encoder contains the next:
- Multi-Head Self Consideration Layer (MSP): This layer concatenates all the eye outputs linearly to the correct dimensions. The numerous consideration heads assist practice native and international dependencies in a picture.
- Multi-Layer Perceptrons (MLP) Layer: This layer accommodates a two-layer with Gaussian Error Linear Unit (GELU).
- Layer Norm (LN): That is added prior to every block because it doesn’t embody any new dependencies between the coaching photos. This thereby helps enhance the coaching time and total efficiency.
Furthermore, residual connections are included after every block as they permit the elements to move by the community instantly with out passing by non-linear activations.
Within the case of picture classification, the MLP layer implements the classification head. It does it with one hidden layer at pre-training time and a single linear layer for fine-tuning.
What’s self-attention of Imaginative and prescient Transformer?
The self-attention mechanism is a key part of the transformer structure, which is used to seize long-range dependencies and contextual info within the enter information. The self-attention mechanism permits a ViT mannequin to take care of completely different areas of the enter information, based mostly on their relevance to the duty at hand.
Subsequently, the self-attention mechanism computes a weighted sum of the enter information, the place the weights are computed based mostly on the similarity between the enter options. This permits the mannequin to offer extra significance to the related enter options, which helps it to seize extra informative representations of the enter information.
Therefore, self-attention is a computational primitive used to quantify pairwise entity interactions that assist a community to be taught the hierarchies and alignments current inside enter information. Consideration has confirmed to be a key component for imaginative and prescient networks to realize greater robustness.
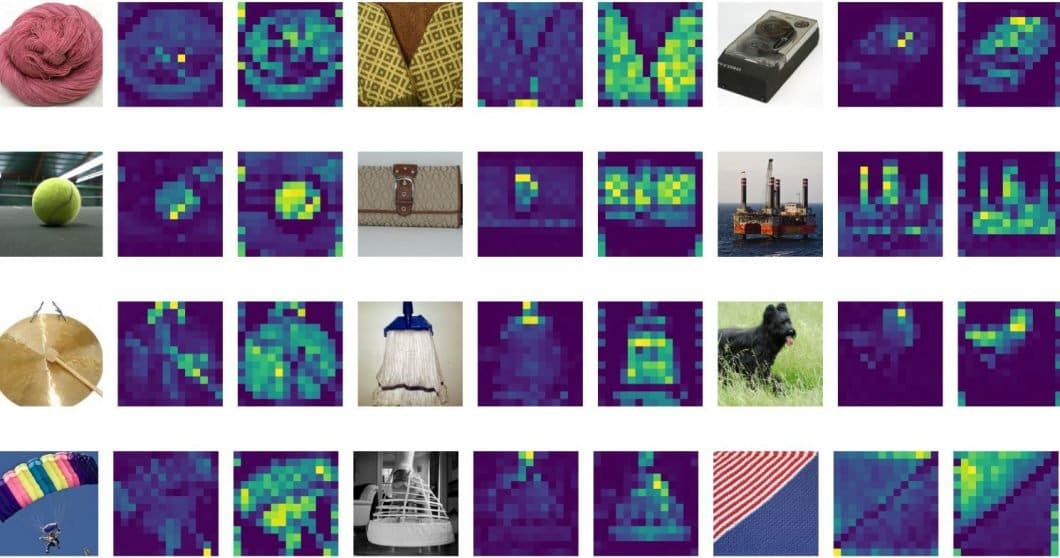
What are consideration maps of ViT?
The eye maps of Imaginative and prescient Transformer (ViT) are matrices that signify the significance of various elements of an enter picture to completely different elements of the mannequin’s discovered representations. In ViT, the whole picture of the enter information is first divided into non-overlapping patches, that are then flattened and fed into the transformer encoder (extra concerning the structure beneath).
Consideration maps check with the visualizations of the eye weights which can be calculated between every token (or patch) within the picture and all different tokens. These consideration maps are calculated utilizing a self-attention mechanism, the place every token attends to all different tokens to acquire a weighted sum of their representations.
The eye maps might be visualized as a grid of heatmaps, the place every heatmap represents the eye weights between a given token and all different tokens. The brighter the colour of a pixel within the heatmap, the upper the eye weight between the corresponding tokens. By analyzing the eye maps, we will acquire insights into which elements of the picture are most necessary for the classification activity at hand.

Imaginative and prescient Transformer ViT Structure
A number of imaginative and prescient transformer fashions have been proposed within the literature. The general construction of the imaginative and prescient transformer structure consists of the next steps:
- Break up a picture into patches (mounted sizes)
- Flatten the picture patches
- Create lower-dimensional linear embeddings from these flattened picture patches
- Embrace positional embeddings
- Feed the sequence as an enter to a state-of-the-art transformer encoder
- Pre-train the ViT mannequin with picture labels, which is then totally supervised on an enormous dataset
- High quality-tune the downstream dataset for picture classification
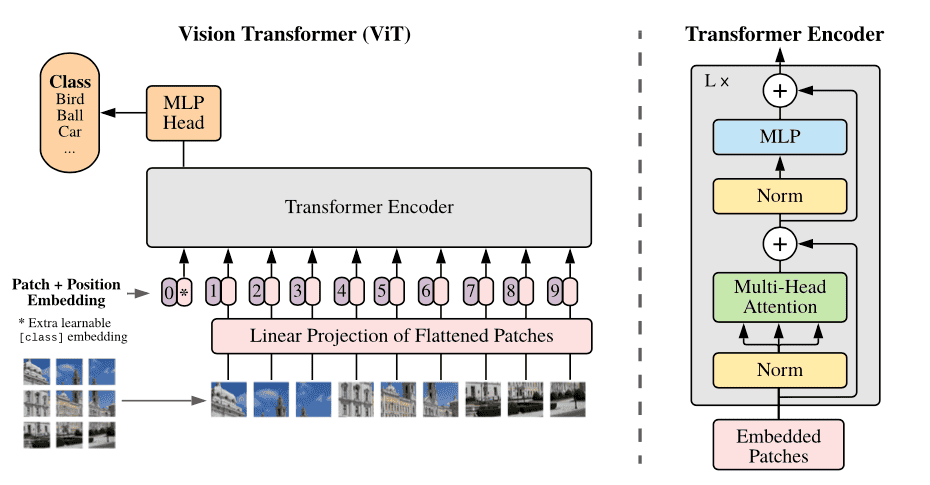
Imaginative and prescient Transformers (ViT) is an structure that makes use of self-attention mechanisms to course of photos. The Imaginative and prescient Transformer Structure consists of a sequence of transformer blocks. Every transformer block consists of two sub-layers: a multi-head self-attention layer and a feed-forward layer.
The self-attention layer calculates consideration weights for every pixel within the picture based mostly on its relationship with all different pixels, whereas the feed-forward layer applies a non-linear transformation to the output of the self-attention layer. The multi-head consideration extends this mechanism by permitting the mannequin to take care of completely different elements of the enter sequence concurrently.
ViT additionally contains an extra patch embedding layer, which divides the picture into fixed-size patches and maps every patch to a high-dimensional vector illustration. These patch embeddings are then fed into the transformer blocks for additional processing.
The ultimate output of the ViT structure is a category prediction, obtained by passing the output of the final transformer block by a classification head, which usually consists of a single totally linked layer.
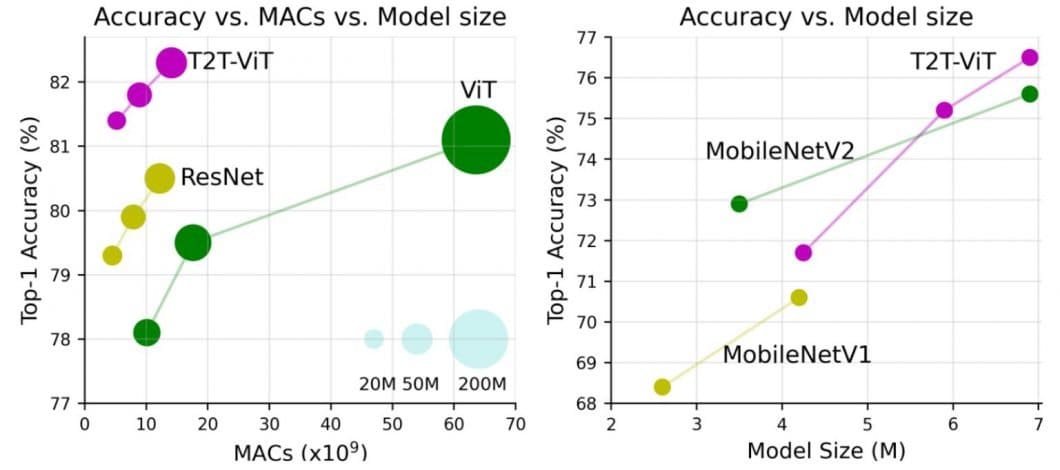
Whereas the ViT full-transformer structure is a promising choice for imaginative and prescient processing duties, the efficiency of ViTs remains to be inferior to that of similar-sized CNN options (corresponding to ResNet) when skilled from scratch on a mid-sized dataset corresponding to ImageNet. General, the ViT structure permits for a extra versatile and environment friendly option to course of photos, with out counting on pre-defined handcrafted options.
How does a Imaginative and prescient Transformer (ViT) work?
The efficiency of a imaginative and prescient transformer mannequin relies on selections corresponding to that of the optimizer, community depth, and dataset-specific hyperparameters. In comparison with ViT, CNNs are simpler to optimize.
The disparity on a pure transformer is to marry a transformer to a CNN entrance finish. The same old ViT stem leverages a 16*16 convolution with a 16 stride. Compared, a 3*3 convolution with stride 2 will increase the steadiness and elevates precision.
CNN turns primary pixels right into a function map. Later, the function map is translated by a tokenizer right into a sequence of tokens which can be then inputted into the transformer. The transformer then applies the eye method to create a sequence of output tokens.
Ultimately, a projector reconnects the output tokens to the function map. The latter permits the examination to navigate doubtlessly essential pixel-level particulars. This thereby lowers the variety of tokens that have to be studied, decreasing prices considerably.
Significantly, if the ViT mannequin is skilled on enormous datasets which can be over 14M photos, it may well outperform the CNNs. If not, the best choice is to stay to ResNet or EfficientNet. The imaginative and prescient transformer mannequin is skilled on an enormous dataset even earlier than the method of fine-tuning. The one change is to ignore the MLP layer and add a brand new D instances KD*Ok layer, the place Ok is the variety of lessons of the small dataset.
To fine-tune in higher resolutions, the 2D illustration of the pre-trained place embeddings is completed. It is because the trainable liner layers mannequin the positional embeddings.
Challenges of Imaginative and prescient Transformers
The challenges of imaginative and prescient transformers are many, they usually embody points associated to structure design, generalization, robustness, interpretability, and effectivity.
On the whole, transformer lack some inductive biases in comparison with CNNs, and rely closely on large datasets for large-scale coaching, which is why the standard of knowledge considerably influences the generalization and robustness of transformer in laptop imaginative and prescient duties.
While ViT exhibits distinctive efficiency on downstream picture classification duties, for instance, VTAB and CIFAR, instantly making use of the ViT spine on object detection has didn’t surpass the outcomes of CNNs
Moreover, it nonetheless stays a problem to completely perceive why transformer work nicely on visible duties. Moreover, growing environment friendly transformer fashions for laptop imaginative and prescient that may be deployed on resource-limited gadgets is a difficult situation.
Actual-World Imaginative and prescient Transformer (ViT) Use Instances and Functions
Imaginative and prescient transformers have in depth functions in in style picture recognition duties corresponding to object detection, segmentation, picture classification, and motion recognition. Furthermore, ViTs are utilized in generative modeling and multi-model duties, together with visible grounding, visual-question answering, and visible reasoning.
Video forecasting and exercise recognition are all elements of video processing that require ViT. Furthermore, picture enhancement, colorization, and picture super-resolution additionally use ViT fashions. Final however not least, ViTs have quite a few functions in 3D evaluation, corresponding to segmentation and level cloud classification.

Conclusion
The imaginative and prescient transformer mannequin makes use of multi-head self-attention in Pc Imaginative and prescient with out requiring image-specific biases. The mannequin splits the pictures right into a sequence of positional embedding patches, that are processed by the transformer encoder.
It does so to know the native and international options that the picture possesses. Final however not least, the ViT has the next precision fee on a big dataset with lowered coaching time.
What’s subsequent
Learn extra about associated matters and different state-of-the-art strategies in machine studying, picture processing, and recognition.