
With the latest enhancement of visible instruction tuning strategies, Multimodal Giant Language Fashions (MLLMs) have demonstrated exceptional general-purpose vision-language capabilities. These capabilities make them key constructing blocks for contemporary general-purpose visible assistants. Current fashions, together with MiniGPT-4, LLaVA, InstructBLIP, and others, exhibit spectacular visible reasoning and instruction-following talents. Though a majority of them depend on image-text pairs for image-level vision-language alignment, they carry out nicely on this area. Nevertheless, their reliance on box-level and image-level understanding is the first motive MLLMs fall quick in replicating their efficiency on fine-grained vision-language alignment duties on the pixel stage. Moreover, the restricted availability of mask-based instruction knowledge for coaching poses challenges in additional enhancing MLLMs.
Osprey is a mask-text instruction coaching methodology with the first goal of extending MLLMs. It incorporates fine-grained masked areas in language instruction to attain pixel-level visual-language understanding. To perform this, the Osprey framework curates a mask-based region-text dataset with over 700 thousand samples. It injects pixel-level illustration into Giant Language Fashions (LLMs) to design a vision-language mannequin. Notably, the Osprey framework adopts a convolutional CLIP mannequin as its imaginative and prescient encoder and integrates a mask-aware visible extractor into its structure. This enables for exact extraction of visible masks options from high-resolution enter.
On this article, we are going to talk about the Osprey framework and delve deeper into its structure. We may also discover the curated region-text dataset with over 700 thousand samples and examine its efficiency in numerous area understanding duties. So, let’s get began.
Multimodal Giant Language Fashions like MiniGPT-4, Otter, Qwen-LV, InstructBLIP and others are the frontrunners for creating general-purpose visible assistants, and they’re famend for his or her distinctive multimodal and imaginative and prescient generative capabilities. Nevertheless, Multimodal Giant Language Fashions endure from a serious problem as they ship unsatisfactory outcomes on fine-grained picture understanding duties like captioning, area classification, and reasoning. A significant motive for the sub-par efficiency on fine-grained picture understanding duties is the dearth of alignment at region-level. Current MLLMs like GPT4RoI, Shikra and others goal to allow region-level understanding in vision-language fashions by processing bounding-box specified areas, and leveraging visible instruction tuning with spatial options at object-level.
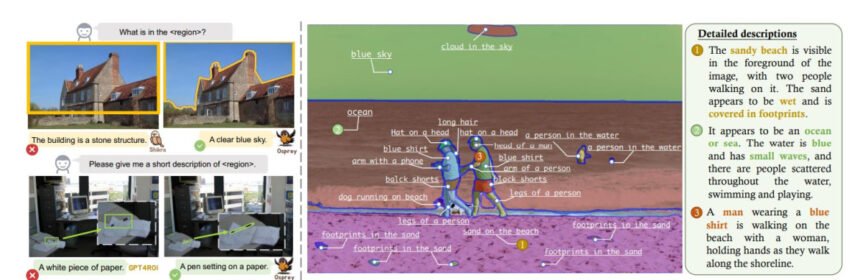
Though the method to allow region-level understanding would possibly enhance the efficiency, using sparse bounding containers because the referring enter area instantly would possibly introduce irrelevant background options resulting in inaccurate region-text pair alignment for visible instruction tuning on giant language fashions. Throughout the inference course of, the box-level referring enter won’t be capable to detect & characterize the item exactly; which may end in semantic deviation as demonstrated within the following picture.

Compared, utilizing fine-grained masks as an alternative of coarse bounding containers because the referring enter would possibly be capable to characterize objects with extra precision. Not too long ago developed SAM or Section Something Mannequin trains on billions of high-quality masks, demonstrates exceptional segmentation high quality on zero-shot objects and helps the usage of factors or easy bounding containers as prompts. Nevertheless, the SAM framework can not generate major semantic labels, nor can they supply detailed semantic captions and attributes. Consequently, present fashions lack inherent multimodal fine-grained info, and have a limited-understanding of scenes within the real-world.
To deal with the challenges confronted by the prevailing MLLMs, Osprey, a novel mask-text instruction coaching methodology goals to increase the capabilities of multimodal giant language fashions for fine-grained understanding on pixel-level. The Osprey framework introduces a mask-aware visible extractor that captures visible masks options with various granularity exactly. The framework then interleaves the visible options with language directions to generate the enter sequence for the big language mannequin, and leverages convolutional CLIP structure to facilitate the usage of excessive decision enter. Owing to its design and structure, the Osprey framework is ready to obtain fine-grained semantic understanding for object-level and part-level areas, and supplies detailed object attributes together with major object class and enhanced descriptions of advanced scenes.
By leveraging the capabilities of visible instruction tuning, the Osprey framework allows new capabilities past image-level and box-level understanding of the scenes because the Osprey framework can generate fine-grained semantics utilizing class-agnostic masks from off the shelf SAMs. Moreover, Osprey additionally reveals exceptional capabilities throughout referring object classification, open-vocabulary recognition, regional-level captioning, and detailed area description duties.
Osprey : Methodology and Structure
The next determine demonstrates the structure overview of the Osprey framework consisting of a giant language mannequin, pixel-level masks conscious visible extractor, and an image-level imaginative and prescient encoder.

For a given picture, the enter language, and the referring masks areas, the framework performs conversion and tokenization to generate embeddings earlier than sending the language embedding sequences and interleaved masks options to the big language mannequin to acquire fine-grained semantic understandings.
Convolutional CLIP Imaginative and prescient Encoder
The imaginative and prescient encoder deployed in a majority of multimodal giant language fashions is exemplified utilizing a ViT-based CLIP mannequin. Consequently, the framework adopts a picture decision of both 224×224 pixels or 336 x 336 pixels. Nevertheless, the usage of the ViT-based CLIP mannequin makes it tough for the mannequin to attain fine-grain picture understanding of pixel-level representations, an issue amplified additional in small areas. Moreover, the computational overload related to the ViT structure hinders the potential for rising the enter picture decision.
To deal with the problem, the Osprey framework implements a convolutional CLIP mannequin because the imaginative and prescient encoder in its structure. Historically, Convolutional Neural Networks based mostly CLIP fashions have demonstrated exceptional generalization capabilities throughout totally different enter resolutions when put towards imaginative and prescient transformer based mostly CLIP fashions. Implementing a CNN-based CLIP mannequin makes room for quick inference and environment friendly coaching with out compromising on the mannequin’s efficiency. Moreover, a CNN-based CLIP mannequin is able to producing multi-scale function maps that the framework then instantly makes use of for function extraction in every subsequent object area.
Masks Conscious Visible Extractor
In distinction to present region-based fashions that use sparse bounding containers because the referring enter, the Osprey framework makes use of detailed masks areas to implement object-based representations. The Osprey mannequin employs a masks conscious visible extractor element to seize pixel-level options inside every object area. The masks ware visible extractor element encodes mask-level visible options, and moreover, gathers the spatial place info of every area.
To implement this, Osprey first makes use of the multi-level picture options generated by the imaginative and prescient encoder to undertake the mask-pooling operation, and for each single-;evel function, the framework swimming pools all of the options that lie inside the masks area. The mannequin then encodes the options throughout totally different layers by passing every function by way of a linear projection layer that generates region-level embeddings, and fuses multi-level options by performing summation. The mannequin then makes use of a MLP layer to provide the visible masks token. Moreover, Osprey preserves the spatial geometry of the item area by encoding the pixel-level place relationship by implementing a binary masks for every object area. Ultimately, Osprey consists of the visible masks token and its respective spatial tokens for every masks area embedding.
LLM Tokenization
As talked about earlier, the mannequin extracts the image-level embeddings of a picture by feeding it right into a pre-trained CNN-based visible encoder. For textual info, the mannequin first makes use of pre-trained LLM tokenizers to tokenize textual content sequences, after which tasks these tokenized textual content sequences into textual content embeddings. For mask-based areas, the mannequin defines a particular token as a placeholder, after which substitutes it with a spatial token together with a masks token. When the mannequin refers to an object area within the textual content enter, it appends the placeholder after its area identify that permits the masks areas to combine with texts nicely leading to full sentences with out the tokenization area. Furthemore, aside from person directions, the mannequin additionally features a prefix immediate, a particular token that serves as a placeholder, that’s then changed by the imaginative and prescient encoder’s image-level embeddings. Lastly, the framework interleaves the region-level & image-level visible tokens together with textual content tokens, and feeds it into the big language mannequin to grasp the person directions and the picture with totally different areas within the object.
Osprey : Three Stage Coaching Course of
The Osprey framework deploys a 3 stage coaching course of wherein every of the coaching phases is supervised by minimizing a next-token prediction loss.
Stage 1: Picture-Textual content Alignment Coaching
Within the first stage, the Osprey framework deploys the CNN-based CLIP imaginative and prescient encoder to coach the image-level options and language connector to coach the mannequin for image-text function alignment. Within the first stage, the framework employs three elements: a pre-trained giant language mannequin, a pre-trained imaginative and prescient encoder, and an image-level projector. The framework additionally adopts a MLP layer to function the vision-language connector that helps in enhancing Osprey’s multimodal generative capabilities.
Stage 2: Masks-Textual content Alignment Pre-Coaching
Within the second stage, Osprey hundreds the load skilled within the first stage, and employs its Masks-Conscious Visible Extractor element to seize pixel-level area options. Within the second stage, the framework solely trains the Masks-Conscious Visible Extractor to align language embeddings with mask-based area options. Moreover, the mannequin collects pixel-level masks pairs and quick texts from part-level and publicly-available object-level datasets, and converts them into instruction-following knowledge to additional practice the mannequin.
Stage 3: Finish-to-Finish High quality Tuning
Within the third and the ultimate stage, the mannequin fixes the weights of the imaginative and prescient encoder, and finetunes the big language mannequin, mask-based area function extractor, and the image-level projector elements in its structure. The first goal of coaching within the third stage is to increase the mannequin’s functionality to comply with person directions precisely, and effectively carry out pixel-level area understanding duties.
After implementing the three coaching phases, the Osprey framework is able to understanding advanced eventualities outlined by person directions and based mostly on pixel-level masks areas.
Osprey : Experimental Outcomes
To judge its efficiency, Osprey builders conduct a wide selection of experiments to show the mannequin’s capabilities in classification, pixel-level region-based recognition, and sophisticated descriptions.

Open-Vocabulary Segmentation
The first aim of open-vocabulary segmentation is to generate mask-based area recognition and its respective class explicitly. To attain open-vocabulary segmentation, Osprey first makes use of an enter textual content immediate, following which the mannequin adopts ground-truth masks areas for mannequin interference to evaluate mannequin’s efficiency in open-vocabulary recognition duties. On the idea of the sentence response generated by the multimodal giant language mannequin, Osprey calculates the semantic similarity between the vocabulary listing and output of every dataset. The next determine compares Osprey towards state-of-the-art multimodal giant language fashions.

As it may be noticed, the Osprey framework outperforms present strategies by a substantial margin on each the Cityscapes and the ADE20K-150 dataset. The outcomes point out Osprey’s capacity to outperform present approaches, and obtain sturdy understanding and recognition on fine-grained object areas.
Referring Object Classification
Within the Referring Object Classification process, the mannequin is required to categorise the item inside a particular area of a picture. To judge its classification capabilities, the Osprey framework makes use of two semantic relevance metrics together with Semantic IoU or S-IoU and Semantic Similarity or SS. Semantic IoU represents the overlap of phrases between the ground-truth and the prediction labels whereas Semantic Similarity measures the similarity predicted and/or ground-truth labels in a semantic area. The next picture demonstrates Osprey’s efficiency within the Referring Object Classification process when put towards fashions using box-level and image-level approaches.

Detailed-Area Description
Within the Detailed-Area Description process, the mannequin evaluates its efficiency on instruction-following detailed description capabilities together with different region-level approaches. The mannequin randomly selects an enter inference immediate from a listing of predefined prompts, and leverages the GPT-4 LLM framework to measure the standard of the response generated by the mannequin towards the enter referring areas comprehensively. Utilizing the instruction technology pipeline, the mannequin generates questions, and seeks GPT-4’s solutions following which the LLM assesses the correctness of semantics and precision of referring understanding. The next desk demonstrates the efficiency of Osprey towards state-of-the-art fashions on Detailed-Area Description duties.

Area-Degree Captioning
The Osprey framework additionally outperforms present approaches on Area-Degree Captioning duties with the outcomes contained within the following picture.

Last Ideas
On this article, we have now talked about Osprey, a mask-text instruction coaching methodology with the first goal of extending MLLMs by incorporating fine-grained masked areas in language instruction to attain pixel-level visual-language understanding. To perform its aim, the Osprey framework curates a mask-based region-text dataset with over 700 thousand samples, and injects pixel-level illustration into LLM to design a vision-language mannequin. The Osprey framework goals to boost MLLMs for fine-grained visible understanding considerably, and by implementing a CNN-based CLIP mannequin and a mask-aware visible extractor, Osprey attains the potential to know photographs at each part-level and object-level areas.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. sign up for binance
Your article helped me a lot, is there any more related content? Thanks! https://www.binance.com/register?ref=IHJUI7TF
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.