
What’s GPT?
GPT stands for Generative Pretrained TraCertificate Program in AI Enterprise Strategynsformer, a sort of synthetic intelligence mannequin designed to know and generate human-like textual content. It’s the spine of highly effective AI functions like ChatGPT, revolutionizing the best way we work together with machines.
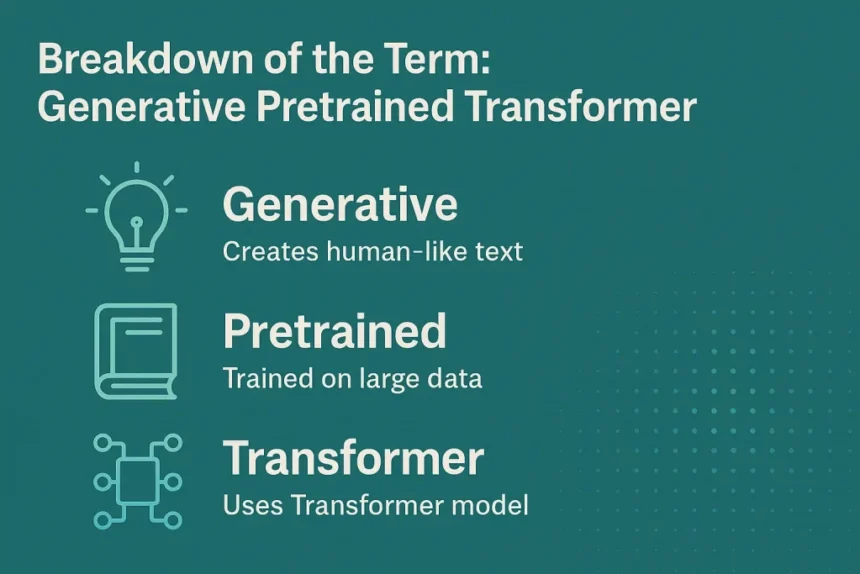
Breakdown of the Time period: Generative Pretrained Transformer

- Generative – GPT is able to creating coherent and contextually related textual content, mimicking human-like responses throughout numerous subjects.
- Pretrained – Earlier than fine-tuning for particular duties, GPT undergoes intensive coaching on huge datasets containing various textual content sources, enabling it to understand grammar, info, and reasoning patterns.
- Transformer – At its core, GPT makes use of a neural community structure often called a Transformer, which leverages consideration mechanisms to course of language effectively, guaranteeing context-aware and significant textual content era.
Trying to grasp AI and Machine Studying?
Enroll in Nice Studying’s AI and ML program provided by UT Austin. This program equips you with in-depth data of deep studying, NLP, and generative AI, serving to you speed up your profession within the AI discipline.
Evolution of GPT Fashions

1. GPT-1
Launch: 2018
Key Options:
- GPT-1 was the inaugural mannequin that launched the idea of utilizing a transformer structure for producing coherent textual content.
- This model served primarily as a proof of idea, demonstrating {that a} generative mannequin could possibly be successfully pre-trained on a big corpus of textual content after which fine-tuned for particular downstream duties.
- With 117 million parameters, it showcased the potential of unsupervised studying in understanding and producing human-like language.
- The mannequin realized contextual relations between phrases and phrases, displaying basic language era capabilities.
2. GPT-2
Launch: 2019
Key Options:
- GPT-2 marked a major leap in scope and scale with 1.5 billion parameters, highlighting the affect of mannequin measurement on efficiency.
- The mannequin generated notably fluent and contextually wealthy textual content, able to producing coherent responses to prompts.
- DeepAI opted for a phased launch as a consequence of issues over potential misuse, initially publishing a smaller mannequin earlier than steadily releasing the complete model.
- Its capabilities included zero-shot and few-shot studying, permitting it to carry out numerous duties with out intensive fine-tuning, equivalent to translation, summarization, and query answering.
3. GPT-3
Launch: 2020
Key Options:
- GPT-3 represented a monumental leap in mannequin measurement, that includes 175 billion parameters, which dramatically enhanced its language understanding and era capabilities.
- This model showcased exceptional versatility throughout various functions, performing duties as different as artistic writing, programming help, and conversational brokers with minimal directions, usually attaining state-of-the-art outcomes.
- The introduction of the “few-shot” studying paradigm allowed GPT-3 to adapt to new duties with only some examples, considerably decreasing the need for task-specific fine-tuning.
- Its contextual understanding and coherence surpassed earlier fashions, making it a robust software for builders in constructing AI-driven functions.
4. GPT-4
Launch: 2023
Key Options:
- GPT-4 constructed on the strengths of its predecessor with enhancements in reasoning, context administration, and understanding nuanced directions.
- Whereas particular parameter counts weren’t disclosed, it’s believed to be even bigger and higher than GPT-3, that includes enhancements in architectural strategies.
- This mannequin exhibited higher contextual understanding, permitting for extra correct and dependable textual content era whereas minimizing cases of manufacturing deceptive or factually incorrect data.
- Enhanced security and alignment measures had been carried out to mitigate misuse, reflecting a broader concentrate on moral AI growth.
- GPT-4’s capabilities prolonged to multimodal duties, which means it may course of not simply textual content but additionally pictures, thereby broadening the horizon of potential functions in numerous fields.
Additionally learn: How to create custom GPTs?
Understanding the GPT Structure
- Tokenization & Embeddings

- GPT breaks down textual content into smaller items known as tokens (phrases, subwords, or characters).
- These tokens are then transformed into dense numerical representations, often called embeddings, which assist the mannequin perceive relationships between phrases.
- Multi-Head Self-Consideration Mechanism
- That is the core of the Transformer mannequin. As an alternative of processing phrases one after the other (like RNNs), GPT considers all phrases in a sequence concurrently.
- It makes use of self-attention to find out the significance of every phrase regarding others, capturing long-range dependencies in textual content.
- Feed-Ahead Neural Networks
- Every Transformer block has a completely linked neural community that refines the output from the eye mechanism, enhancing contextual understanding.
- Positional Encoding

- Since Transformers don’t course of textual content sequentially like conventional fashions, positional encodings are added to tokens to retain the order of phrases in a sentence.
- Layer Normalization & Residual Connections
- To stabilize coaching and stop data loss, layer normalization and residual connections are used, serving to the mannequin be taught successfully.
- Decoder-Solely Structure
- In contrast to BERT, which has each an encoder and a decoder, GPT is a decoder-only mannequin. It predicts the subsequent token in a sequence utilizing beforehand generated phrases, making it very best for textual content completion and era duties.
- Pretraining & High-quality-Tuning
- GPT is first pretrained on huge datasets utilizing unsupervised studying.
- It’s then fine-tuned on particular duties (e.g., chatbot conversations, summarization, or code era) to enhance efficiency.
How does GPT (Generative Pre-trained Transformer) Function?
1. Enter Preparation

- Tokenization: The enter textual content (e.g., a sentence or a immediate) is first tokenized into manageable items. GPT sometimes makes use of a subword tokenization methodology like Byte Pair Encoding (BPE), which breaks down unfamiliar phrases into extra acquainted subword elements.
- Encoding: Every token is mapped to a corresponding embedding vector in an embedding matrix. This vector represents the token in a steady area, permitting the mannequin to make calculations.
2. Including Positional Encodings
Since transformers would not have a built-in mechanism to know the order of phrases (in contrast to recurrent neural networks), positional encodings are added to every token embedding. Positional encodings present details about the place of every token within the sequence, incorporating sequential order into the mannequin.
Processing By Transformer Decoder Layers
- Self-Consideration Mechanism: In every layer, the self-attention mechanism permits the mannequin to concentrate on totally different elements of the enter sequence.
- Calculating Consideration Scores: For every token within the enter, the mannequin computes three vectors: question (Q), key (Okay), and worth (V). These vectors are derived from the enter embeddings by way of realized linear transformations.
- The eye scores are computed by taking the dot product of the queries and keys, scaled by the sq. root of the dimensionality, adopted by a softmax operation to supply consideration weights. This determines how a lot consideration every token ought to pay to each different token within the sequence.
- Weighted Sum: The output for every token is computed as a weighted sum of the worth vectors, based mostly on the calculated consideration weights.
3. Multi-Head Consideration
As an alternative of utilizing a single set of consideration weights, GPT makes use of a number of “heads.” Every head learns totally different consideration patterns. The outputs from all heads are concatenated and remodeled to supply the ultimate output of the eye mechanism for that layer.
Feed-Ahead Neural Networks
After the eye calculation, the output is handed by way of a feed-forward neural community (FFN), which applies a non-linear transformation individually to every place within the sequence.
Residual Connections and Layer Normalization
Each the eye output and the FFN output are added to their respective inputs by way of residual connections. Layer normalization is then utilized to stabilize and velocity up coaching.
This course of repeats for every layer within the transformer decoder.
4. Ultimate Output Computation
After passing by way of all transformer decoder layers, the ultimate output vectors are obtained. Every vector corresponds to a token within the enter.
These output vectors are then remodeled by way of a remaining linear layer that tasks them onto the vocabulary measurement, producing logits for each token within the vocabulary.
5. Producing Predictions

To supply predictions, GPT makes use of a softmax perform to transform the logits into chances for every token within the vocabulary. The output now signifies how seemingly every token is to observe the enter sequence.
6. Token Sampling
The mannequin selects the subsequent token based mostly on the chances. Varied sampling strategies can be utilized:
- Grasping Sampling: Selecting the token with the best likelihood.
- Prime-k Sampling: Deciding on from the top-k possible tokens.
- Prime-p Sampling (nucleus sampling): Deciding on from the smallest set of tokens whose cumulative likelihood exceeds a sure threshold (p).
The chosen token is then added to the enter sequence.
7. Iterative Era
Steps 3 to six are repeated iteratively. The mannequin takes the newly generated token, appends it to the enter sequence, and processes the up to date sequence once more to foretell the subsequent token. This continues till a stopping criterion is met (e.g., reaching a specified size, hitting a particular end-of-sequence token, and so on.).
Purposes of GPT

1. Conversational AI & Chatbots
- Powers digital assistants like ChatGPT, dealing with buyer queries, automating responses, and enhancing person interactions.
- Utilized in customer support, technical assist, and AI-driven assist desks to supply instantaneous, contextually related responses.
2. Content material Creation & Copywriting
- Assists in writing articles, blogs, advertising copies, and artistic tales with human-like fluency.
- Utilized by companies, content material creators, and digital entrepreneurs for producing Website positioning-friendly content material and automating social media posts.
3. Code Era & Software program Improvement
- GPT fashions like Codex (a variant of GPT-3) help builders by producing, debugging, and optimizing code.
- Helps a number of programming languages, enabling quicker software program growth and AI-assisted coding.
4. Customized Training & Tutoring
- Enhances adaptive studying platforms, providing personalised examine plans, AI-driven tutoring, and instantaneous explanations.
- Helps college students with essay writing, language translation, and problem-solving in topics like math and science.
5. Analysis & Knowledge Evaluation
- Assists in summarizing analysis papers, producing insights from giant datasets, and drafting technical paperwork.
- Utilized in industries like finance, healthcare, and legislation for analyzing tendencies and automating reviews.
Additionally Learn: How you can use ChatGPT?
Strengths and Limitations of GPT
Human-Like Textual content Era
Power: Generates coherent, context-aware, and fluent textual content.
Limitation: Could generally produce incoherent or irrelevant responses, particularly in complicated situations.
Context Understanding
Power: Makes use of self-attention mechanisms to understand sentence which means and preserve context.
Limitation: Struggles with long-term dependencies in prolonged conversations.
Versatility
Power: Can carry out a number of duties like writing, coding, translation, and Q&A.
Limitation: Lacks real-world reasoning and deep important pondering.
Scalability
Power: Improves with bigger datasets and elevated parameters.
Limitation: Requires huge computing energy and costly infrastructure.
Velocity & Effectivity
Power: Generates responses immediately, enhancing productiveness.
Limitation: Might be computationally costly for real-time functions.
Studying Adaptability
Power: High-quality-tuned for particular domains (e.g., medical, authorized, finance).
Limitation: Wants fixed retraining to remain up to date with new information.
Bias & Moral Issues
Power: Might be fine-tuned to scale back biases and dangerous outputs.
Limitation: Nonetheless vulnerable to biased or deceptive data, requiring cautious oversight.
Creativity & Content material Era
Power: Generates distinctive and fascinating content material for advertising, storytelling, and copywriting.
Limitation: Can generally hallucinate (generate incorrect or fictional data).
Coding Help
Power: Helps builders by producing, debugging, and explaining code.
Limitation: Lacks deep logical reasoning, resulting in errors in complicated code.
Knowledge Privateness & Safety
Power: AI fashions like GPT-4 are constructed with higher security measures.
Limitation: Threat of knowledge misuse if not used responsibly.