
Within the evolving panorama of machine studying, information is the last word gasoline. However what occurs when you could have restricted labeled information and tons of unlabeled information mendacity round? That is the place Semi-Supervised Studying (SSL) comes into play.
Placing the proper stability between supervised and unsupervised studying, semi-supervised studying empowers fashions to make correct predictions whereas decreasing the price of information labeling.
On this article, we are going to break down what semi-supervised studying is, why it issues, the way it works, real-world functions, and the challenges it is best to think about when working with it.
What Is Semi-Supervised Studying?
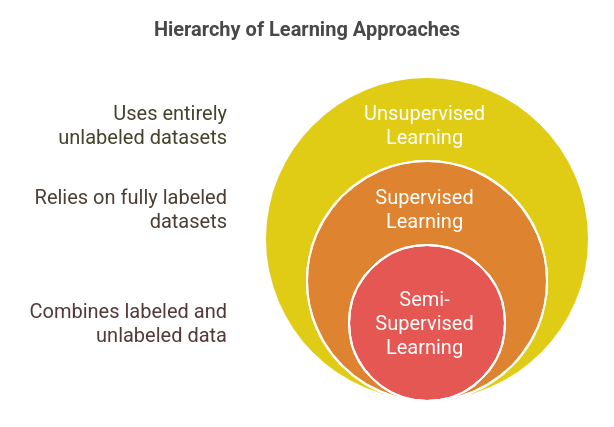
Semi-Supervised Studying is a machine studying strategy that makes use of a small quantity of labeled information mixed with a considerable amount of unlabeled information to coach fashions. In contrast to supervised studying, which depends totally on labeled datasets, and unsupervised studying, which makes use of none, semi-supervised studying sits within the center.
Why is that this essential?
As a result of labeling information is pricey, time-consuming, and infrequently requires area experience. However, gathering uncooked, unlabeled information is way simpler. Semi-supervised studying bridges this hole, permitting us to maximise mannequin efficiency with minimal labeled information.
Additionally Learn: What’s Information Assortment?
How Does Semi-Supervised Studying Work?
The everyday semi-supervised studying course of follows these steps:
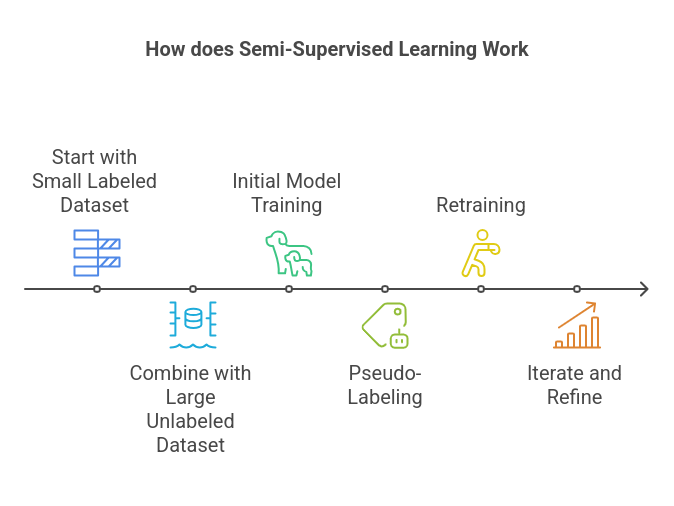
- Begin with a small labeled dataset: These are your “floor truths” from which the mannequin can be taught straight.
- Mix with a big unlabeled dataset: These are the information factors you could have however with out labels.
- Preliminary mannequin coaching: The mannequin is educated on the labeled information.
- Pseudo-labeling: The educated mannequin predicts labels for the unlabeled information.
- Retraining: The mannequin is retrained utilizing each the unique labeled information and the pseudo-labeled information.
- Iterate and refine: This loop continues till efficiency stabilizes or reaches a desired stage.
This methodology leverages the mannequin’s skill to generalize from a small, high-quality labeled dataset and scale its studying with ample unlabeled information.
Why Use Semi-Supervised Studying?
Listed here are some key the reason why semi-supervised studying has gained consideration:
- Lowered labeling prices: You don’t want large labeled datasets.
- Improved mannequin accuracy: When labeled information is scarce, SSL typically outperforms purely supervised fashions.
- Scalability: With a lot unlabeled information being generated every day (consider all these pictures, emails, or transactions), SSL offers a sensible approach to put that information to make use of.
- Works properly with pure datasets: SSL is very efficient for textual content, pictures, speech, and different real-world information codecs.
Benefits and Disadvantages of Semi-Supervised Studying
Benefits of Semi-Supervised Studying
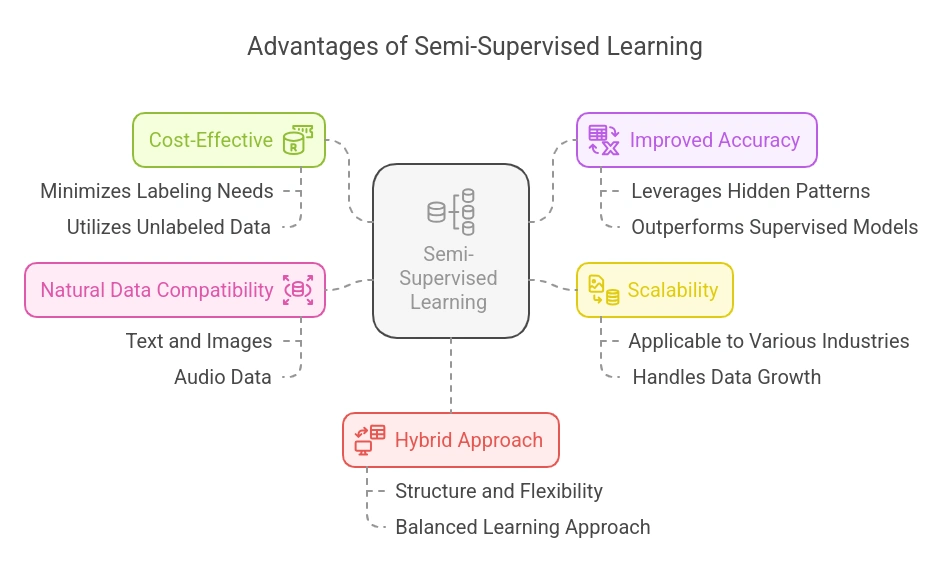
- Price-Efficient: Labeling giant datasets is pricey and time-consuming. Semi-supervised studying minimizes this want by making probably the most out of small labeled datasets mixed with huge quantities of unlabeled information.
- Improved Accuracy with Much less Information: When labeled information is scarce, SSL typically achieves higher accuracy than purely supervised fashions by leveraging hidden patterns within the unlabeled information.
- Scalability: SSL is very scalable, particularly in industries producing giant volumes of uncooked, unlabeled information like social media, e-commerce, and healthcare.
- Works Nicely with Pure Information: SSL algorithms thrive in advanced real-world datasets like textual content, pictures, and audio, the place labeling each pattern is impractical.
- Combines the Better of Each Worlds: By mixing supervised and unsupervised strategies, SSL inherits the strengths of each approaches, balancing construction with flexibility.
Disadvantages of Semi-Supervised Studying
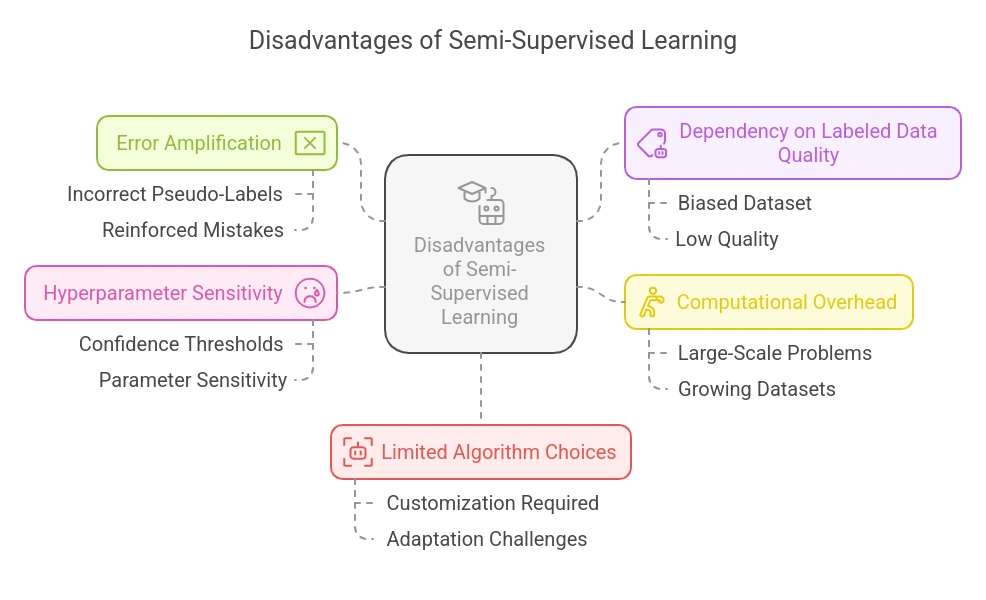
- Error Amplification: Incorrect pseudo-labels can introduce noise and reinforce errors, particularly if the mannequin confidently labels information incorrectly throughout early iterations.
- Dependency on Labeled Information High quality: If the small labeled dataset is biased or low high quality, your complete mannequin can skew, affecting generalization to new information.
- Computational Overhead: Repeated coaching cycles on rising datasets (labeled + pseudo-labeled) can turn out to be computationally costly, notably for large-scale issues.
- Hyperparameter Sensitivity: SSL fashions could be delicate to parameters like confidence thresholds, which management what unlabeled information will get pseudo-labeled and reused in coaching.
- Restricted Algorithm Selections: Not all machine studying algorithms are simply adaptable to semi-supervised studying, and a few require vital customization.
Actual-World Functions of Semi-Supervised Studying
Semi-supervised studying is not only theoretical. It’s actively used throughout industries:
| Trade | Use Case |
| Healthcare | Diagnosing uncommon illnesses with few examples |
| E-commerce | Product categorization and advice |
| Cybersecurity | Detecting new varieties of malware |
| Pure Language Processing | Language translation and sentiment evaluation |
| Autonomous Autos | Object recognition with restricted labeled pictures |
Widespread Semi-Supervised Studying Algorithms
Some extensively used algorithms embrace:
- Self-training: The mannequin labels the unlabeled information and retrains itself.
- Co-training: Two fashions are educated on completely different function units and assist label one another’s information.
- Graph-based strategies: Characterize information as a graph and unfold labels by means of linked nodes.
- Generative fashions: Comparable to Semi-Supervised GANs (Generative Adversarial Networks).
Challenges of Semi-Supervised Studying
Regardless of its potential, semi-supervised studying comes with challenges:
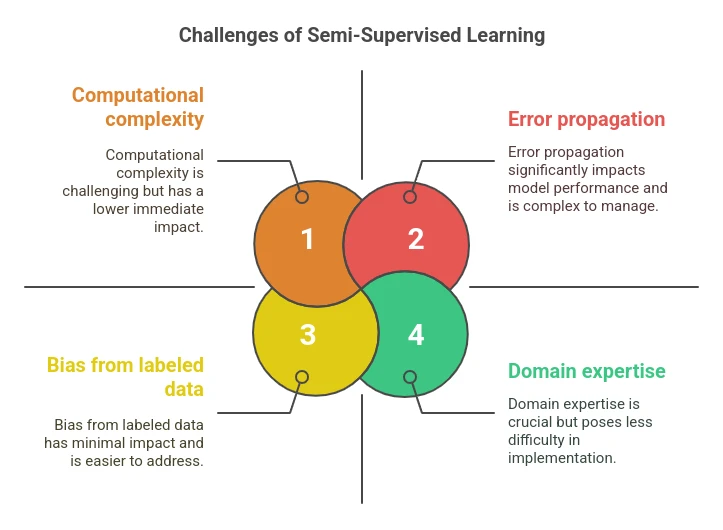
- Error propagation: Incorrect pseudo-labels can degrade mannequin efficiency.
- Bias from labeled information: A small, unbalanced labeled dataset may skew your complete mannequin.
- Computational complexity: Dealing with giant datasets with iterative retraining can get costly.
- Area experience: Even the preliminary labeled information have to be high-quality to keep away from compounding errors.
Way forward for Semi-Supervised Studying
With the explosion of information and the rising prices of information labeling, SSL is changing into extra essential than ever. As algorithms turn out to be extra subtle, semi-supervised studying will play a central function in areas like:
Furthermore, it enhances different studying paradigms like lively studying and switch studying, pushing the boundaries of what machines can obtain with minimal human intervention.
Wish to construct a profitable profession in AI & ML?
Enroll on this AI & ML program to achieve experience in cutting-edge applied sciences like Generative AI, MLOps, Supervised & Unsupervised Studying, and extra. With hands-on tasks and devoted profession help, earn certificates and begin your AI journey immediately!
Often Requested Questions(FAQ’s)
1. How do you determine the ratio of labeled to unlabeled information in semi-supervised studying?
There’s no one-size-fits-all ratio, however in apply, fashions typically carry out properly when the labeled information is simply sufficient to information preliminary studying—generally as little as 1-10% of the whole dataset. The perfect ratio depends upon the issue complexity, mannequin sort, and high quality of the labeled information.
2. Is semi-supervised studying appropriate for real-time methods?
Semi-supervised studying can work for real-time methods, but it surely’s tougher as a result of pseudo-labeling and retraining steps could be computationally intensive. For real-time functions, light-weight semi-supervised strategies or incremental studying methods are most well-liked.
3. How is the standard of pseudo-labels verified in semi-supervised studying?
Pseudo-label high quality is usually evaluated utilizing confidence thresholds. Solely predictions with excessive confidence scores are added again into coaching to reduce the danger of error propagation. Some fashions additionally use human validation at key levels.
4. Can semi-supervised studying deal with noisy information?
SSL can deal with some noise, but when each labeled and unlabeled datasets are noisy, the danger of spreading errors will increase. Methods like noise filtering, strong loss features, and validation loops are generally used to mitigate this.
5. How does semi-supervised studying examine with lively studying?
Whereas semi-supervised studying routinely makes use of unlabeled information with minimal human involvement, lively studying selects probably the most informative information factors and actively queries a human for labels. Each approaches goal to scale back labeling prices however differ in methodology—generally they’re even mixed for higher outcomes.