

YOLOX (You Solely Look As soon as) is a high-performance object detection mannequin belonging to the YOLO household. YOLOX brings with it an anchor-free design, and decoupled head structure to the YOLO household. These modifications elevated the mannequin’s efficiency in object detection.
Object detection is a basic process in laptop imaginative and prescient, and YOLOX performs a good position in enhancing it.
Earlier than going into YOLOX, it is crucial to check out the YOLO collection, as YOLOX builds upon the earlier YOLO fashions.
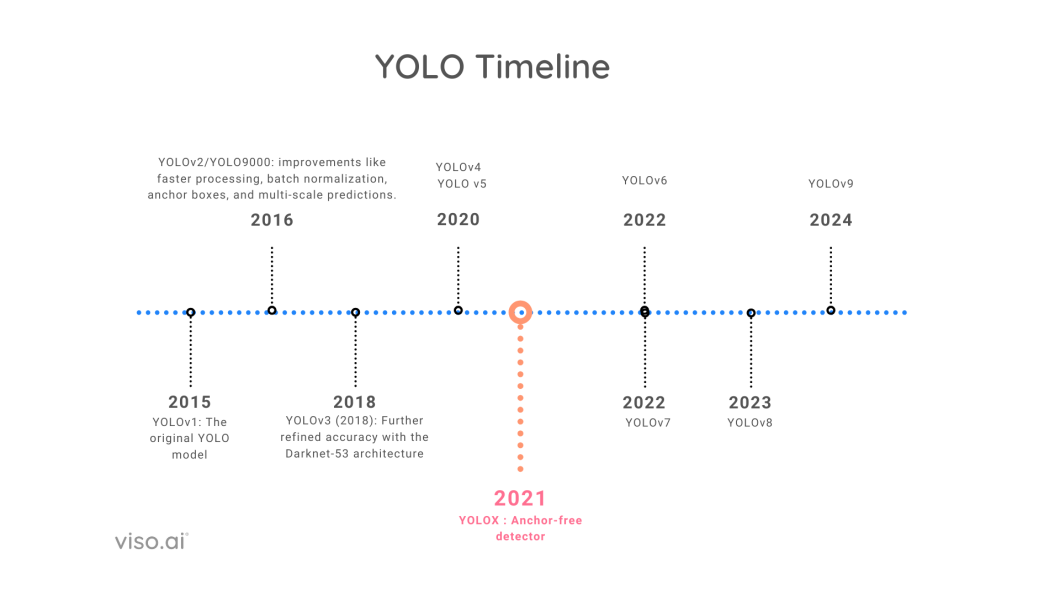
In 2015, researchers launched the primary YOLO mannequin, which quickly gained reputation for its object detection capabilities. Since its launch, there have been steady enhancements and important modifications with the introduction of newer YOLO variations.
What’s YOLO?
YOLO in 2015 turned the primary important mannequin able to object detection with a single go of the community. The earlier approaches relied on Area-based Convolutional Neural Community (RCNN) and sliding window methods.
Earlier than YOLO, the next strategies had been used:
- Sliding Window Method: The sliding window strategy was one of many earliest methods used for object detection. On this strategy, a window of a set measurement strikes throughout the picture, at each step predicting whether or not the window incorporates the article of curiosity. This an easy technique, however computationally costly, as a excessive variety of home windows must be evaluated, particularly for giant pictures.

- Area Proposal Technique (R-CNN and its variants): The Area-based Convolutional Neural Networks (R-CNN) and its successors, Quick R-CNN and Sooner R-CNN tried to cut back the computational value of the sliding window strategy by specializing in particular areas of the picture which are more likely to comprise the article of curiosity. This was achieved by utilizing a area proposal algorithm to generate potential bounding bins (areas) within the picture. Then, the Convolutional Neural Community (CNN) labeled these areas into totally different object classes.
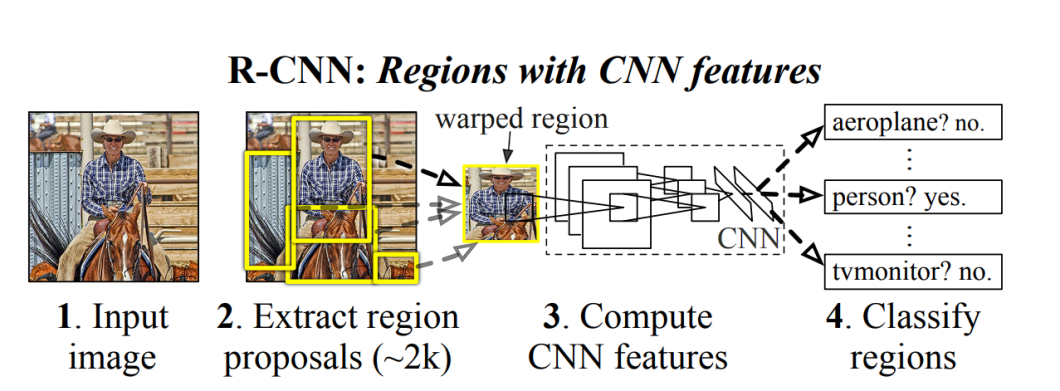
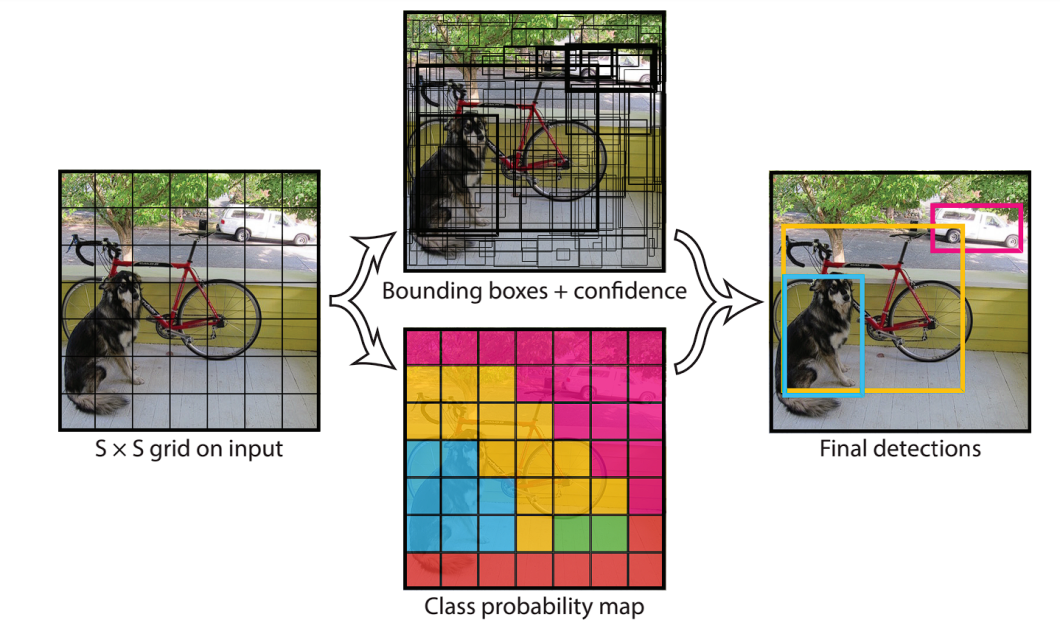
- Single Stage Technique (YOLO): Within the single-stage technique, the detection course of is simplified. This technique instantly predicts bounding bins and sophistication chances for objects in a single step. It does this by first extracting options utilizing a CNN, then the picture is split right into a grid of squares. For every grid cell, the mannequin predicts bounding field and sophistication chances. This made YOLO extraordinarily quick, and able to real-time software.
Historical past of YOLO
The YOLO collection strives to steadiness velocity and accuracy, delivering real-time efficiency with out sacrificing detection high quality. This can be a tough process, as a rise in velocity ends in decrease accuracy.
For comparability, among the best object detection fashions in 2015 (R-CNN Minus R) achieved a 53.5 mAP rating with 6 FPS velocity on the PASCAL VOC 2007 dataset. Compared, YOLO achieved 45 FPS, together with an accuracy of 63.4 mAP.
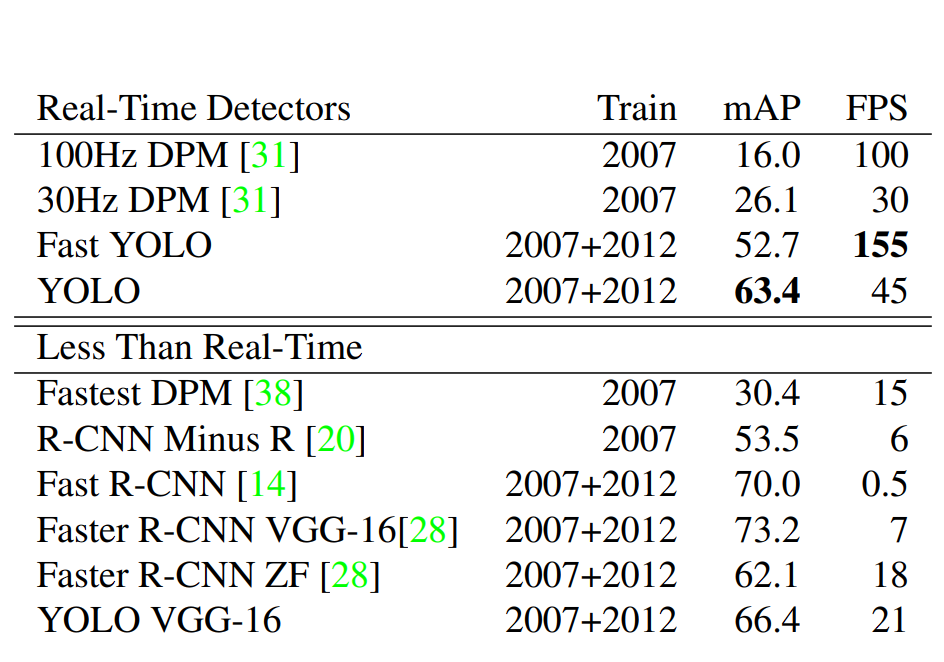
YOLO by way of its releases has been making an attempt to optimize this competing goal, the explanation why we have now a number of YOLO fashions.
YOLOv4 and YOLOv5 launched new community backbones, improved information augmentation methods, and optimized coaching methods. These developments led to important good points in accuracy with out drastically affecting the fashions’ real-time efficiency.
Here’s a fast view of all of the YOLO fashions together with the yr of launch.
What’s YOLOX?
YOLOX with its anchor-free design, drastically decreased the mannequin complexity, in comparison with earlier YOLO variations.
How Does YOLOX Work?
The YOLO algorithm works by predicting three totally different options:
- Grid Division: YOLO divides the enter picture right into a grid of cells.
- Bounding Field Prediction and Class Possibilities: For every grid cell, YOLO predicts a number of bounding bins and their corresponding confidence scores.
- Remaining Prediction: The mannequin utilizing the chances calculated within the earlier steps, predicts what the article is.
YOLOX structure is split into three components:
- Spine: Extracts options from the enter picture.
- Neck: Aggregates multi-scale options from the spine.
- Head: Makes use of extracted options to carry out classification.
What’s a Spine?
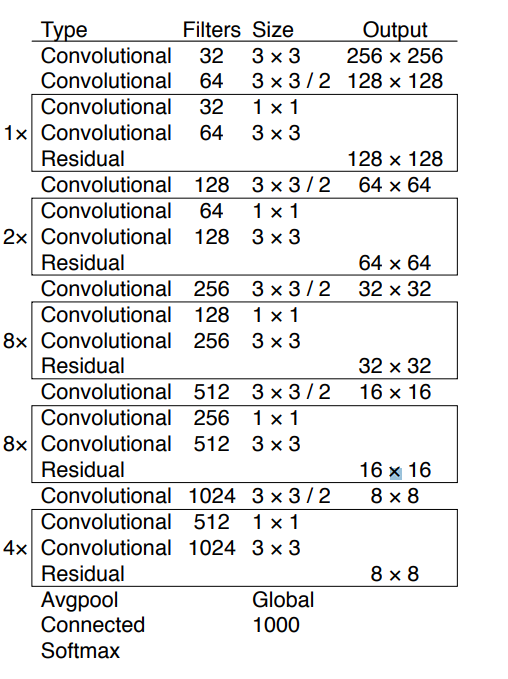
Spine in YOLOX is a pre-trained CNN that’s skilled on an enormous dataset of pictures, to acknowledge low-level options and patterns. You may obtain a spine and use it to your initiatives, with out the necessity to prepare it once more. YOLOX popularly makes use of the Darknet53 and Modified CSP v5 backbones.
What’s a Neck?
The idea of a “Neck” wasn’t current within the preliminary variations of the YOLO collection (till YOLOv4). The YOLO structure historically consisted of a spine for function extraction and a head for detection (bounding field prediction and sophistication chances).
The neck module combines function maps extracted by the spine community to enhance detection efficiency, permitting the mannequin to study from a wider vary of scales.
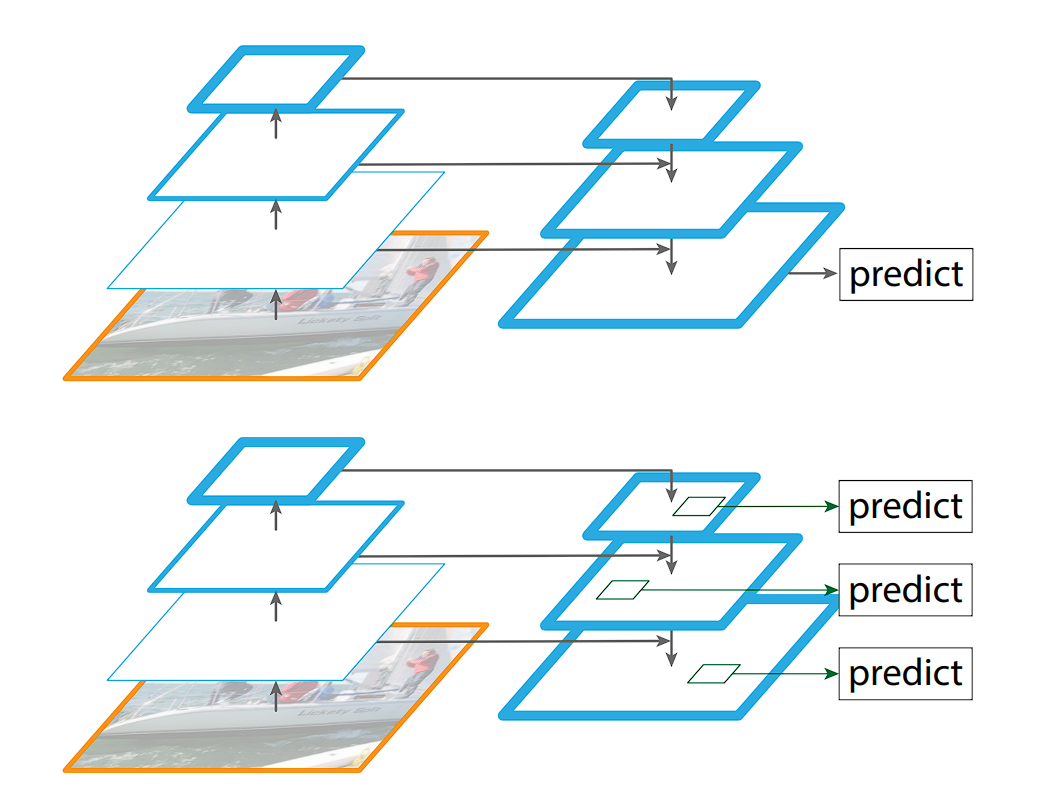
The Function Pyramid Networks (FPN), launched in YOLOv3, tackles object detection at varied scales with a intelligent strategy. It builds a pyramid of options, the place every degree captures semantic info at a unique measurement. To attain this, the FPN leverages a CNN that already extracts options at a number of scales. It then employs a top-down technique: higher-resolution options from earlier layers are up-sampled and fused with lower-resolution options from deeper layers.
This creates a wealthy function illustration that caters to things of various sizes throughout the picture.
What’s the head?
The top is the ultimate part of an object detector; it’s chargeable for making predictions based mostly on the options supplied by the spine and neck. It usually consists of a number of task-specific subnetworks that carry out classification, localization, occasion segmentation, and pose estimation duties.
In the long run, a post-processing step, corresponding to Non-maximum Suppression (NMS), filters out overlapping predictions and retains solely probably the most assured detections.

YOLOX Structure
Now that we have now had an outline of YOLO fashions, we’ll take a look at the distinguishing options of YOLOX.
YOLOX’s creators selected YOLOv3 as a basis as a result of YOLOv4 and YOLOv5 pipelines relied too closely on anchors for object detection.
The next are the options and enhancements YOLOX made compared to earlier fashions:
- simOTA Label Task Technique
Anchor-Free Design
Not like earlier YOLO variations that relied on predefined anchors (reference bins for bounding field prediction), YOLOX takes an anchor-free strategy. This eliminates the necessity for hand-crafted anchors and permits the mannequin to foretell bounding bins instantly.
This strategy provides benefits like:
- Flexibility: Handles objects of assorted sizes and styles higher.
- Effectivity: Reduces the variety of predictions wanted, enhancing processing velocity.
What’s an Anchor?
To foretell actual object boundaries in pictures, object detection fashions make the most of predefined bounding bins known as anchors. These anchors function references and are designed based mostly on the frequent facet ratios and sizes of objects discovered inside a particular dataset.
In the course of the coaching course of, the mannequin learns to make use of these anchors and regulate them accordingly to suit the precise objects. As a substitute of predicting bins from scratch, utilizing anchors ends in fewer calculations carried out.
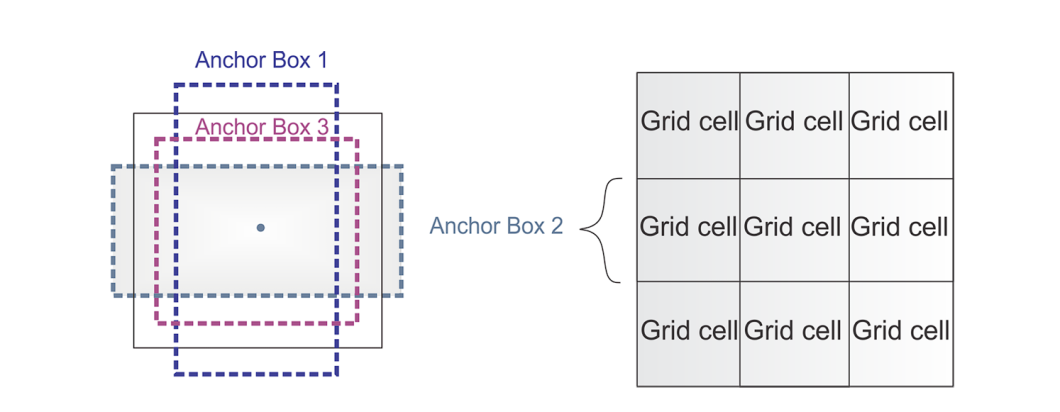
In 2016, YOLOv2 launched anchors, which turned broadly used till the emergence of YOLOX and its popularization of anchorless design. These predefined bins served as a useful place to begin for YOLOv2, permitting it to foretell bounding bins with fewer parameters in comparison with studying the whole lot from scratch. This resulted in a extra environment friendly mannequin. Nonetheless, anchors additionally offered some challenges.
The anchor bins require numerous hyperparameters and design tweaks. For instance,
- Variety of anchors
- Dimension of the anchors
- The facet ratio of the bins
- A lot of anchor bins to seize all of the totally different sizes of objects
YOLOX improved the structure by retiring anchors, however to compensate for the dearth of anchors, YOLOX utilized middle sampling approach.
Multi Positives
In the course of the coaching of the article detector, the mannequin considers a bounding field constructive based mostly on its Intersection over Union (IoU) with the ground-truth field. This technique can embrace samples not centered on the article, degrading mannequin efficiency.
Middle sampling is a way aimed toward enhancing the choice of constructive samples. It focuses on the spatial relationship between the facilities of candidate and ground-truth bins. On this technique, positives are chosen provided that the constructive pattern’s middle falls inside an outlined central area of the ground-truth field (bounding of the proper picture). Within the case of YOLOX, it’s a 3 x 3 field.
This strategy ensures higher alignment and centering on objects, resulting in extra discriminative function studying, decreased background noise affect, and improved detection accuracy.

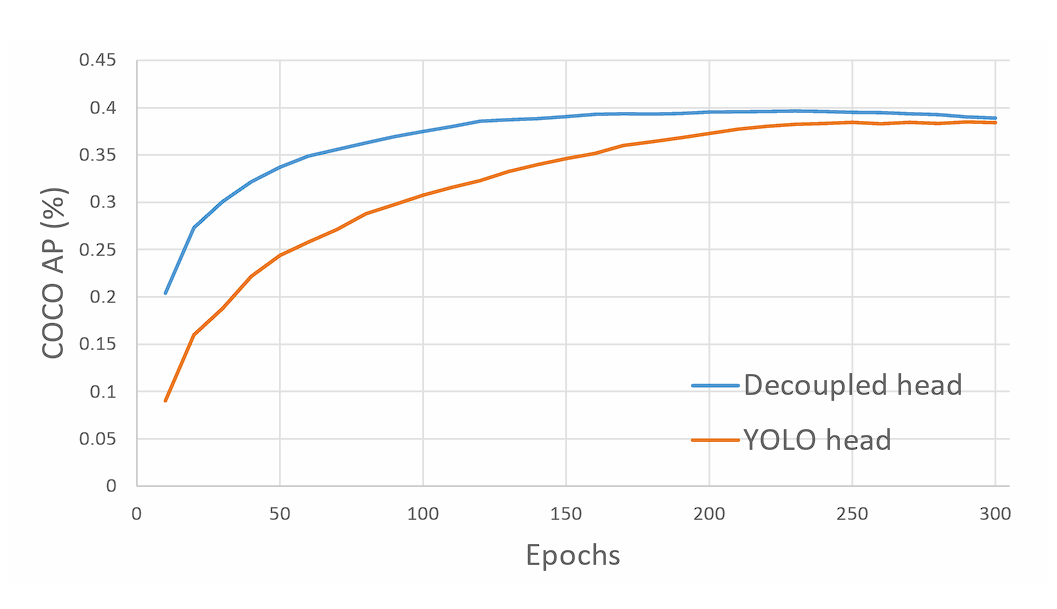
What’s a Decoupled Head?
YOLOX makes use of a decoupled head, a major departure from the single-head design within the earlier YOLO fashions.
In conventional YOLO fashions, the top predicts object lessons and bounding field coordinates utilizing the identical set of options. This strategy simplified the structure again in 2015, but it surely had a disadvantage. It could result in suboptimal efficiency, since classification and localization of the article was carried out utilizing the identical set of extracted options, and thus results in battle. Due to this fact, YOLOX launched a decoupled head.
The decoupled head consists of two separate branches:
- Classification Department: Focuses on predicting the category chances for every object within the picture.
- Regression Department: Concentrates on predicting the bounding field coordinates and dimensions for the detected objects.
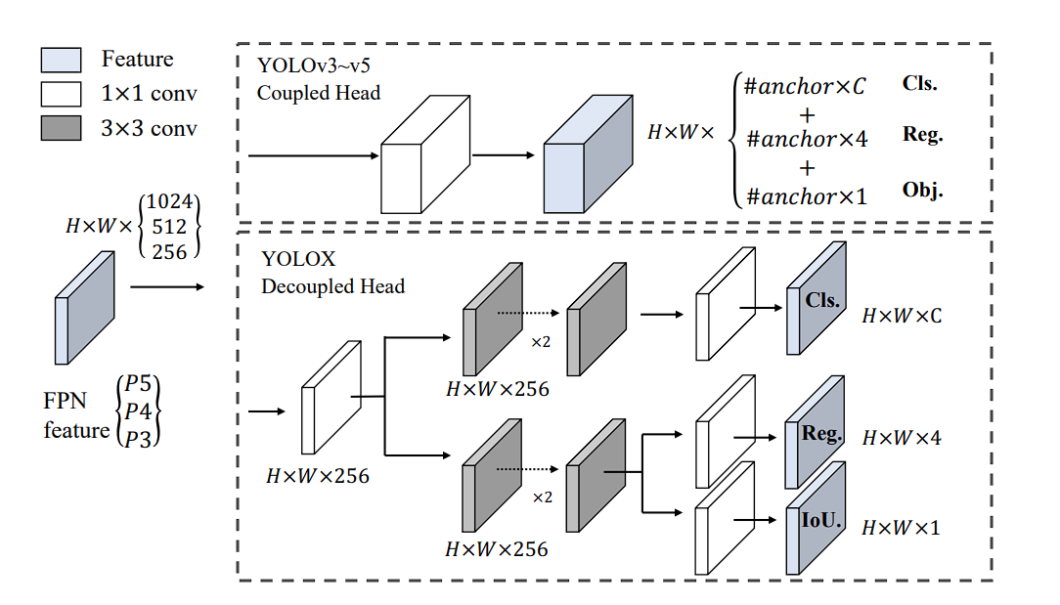
This separation permits the mannequin to specialise in every process, resulting in extra correct predictions for each classification and bounding field regression. Furthermore, doing so results in quicker mannequin convergence.
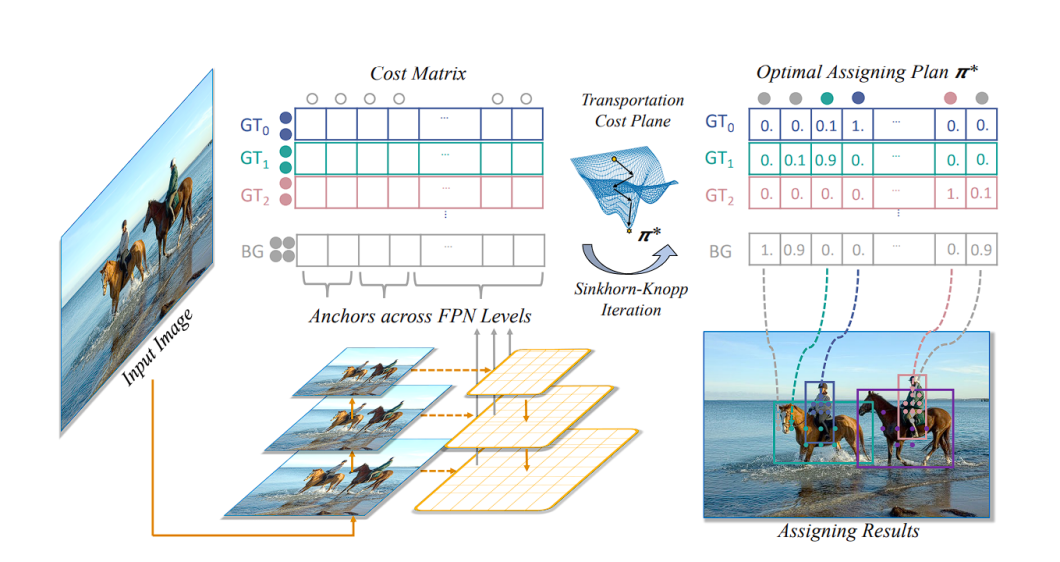
simOTA Label Task Technique
Throughout coaching, the article detector mannequin generates many predictions for objects in a picture, assigning a confidence worth to every prediction. SimOTA dynamically identifies which predictions correspond to precise objects (constructive labels) and which don’t (destructive labels) by discovering the most effective label.
Conventional strategies like IoU take a unique strategy. Right here, every predicted bounding field is in comparison with a floor reality object based mostly on their Intersection over Union (IoU) worth. A prediction is taken into account a very good one (constructive) if its IoU with a floor reality field exceeds a sure threshold, usually 0.5. Conversely, predictions with IoU beneath this threshold are deemed poor predictions (destructive).
The SimOTA strategy not solely reduces coaching time but additionally improves mannequin stability and efficiency by guaranteeing a extra correct and context-aware project of labels.
An necessary factor to notice is that simOTA is carried out solely throughout coaching, not throughout inference.
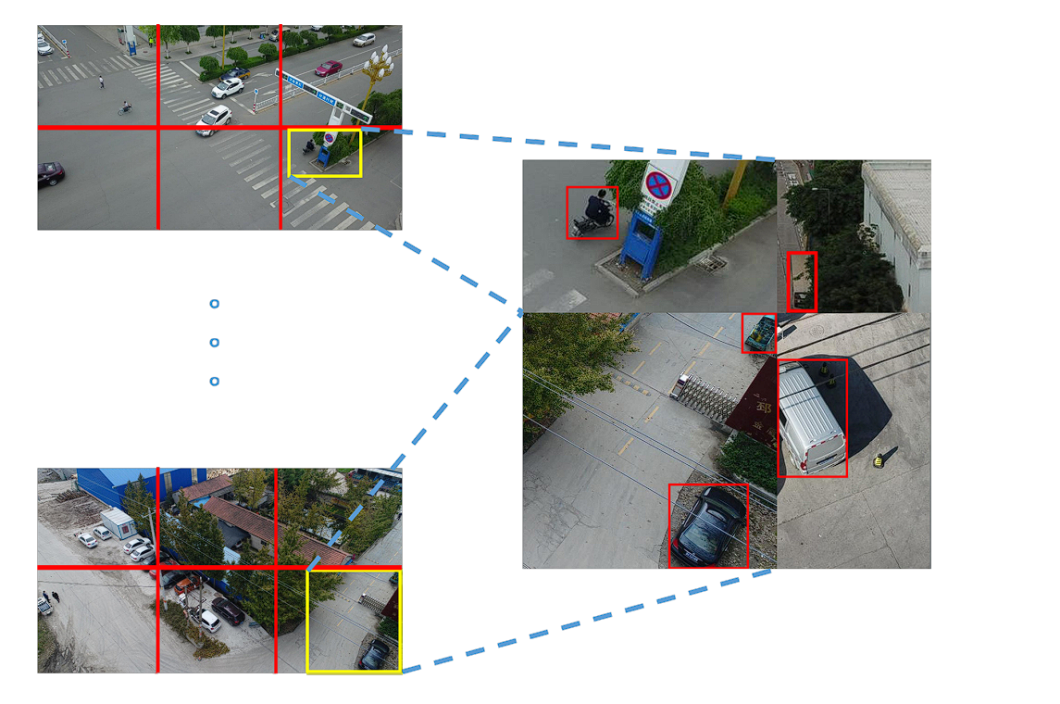
Superior-Information Augmentations
YOLOX leverages two highly effective information augmentation methods:
- MosaicData augmentation: This system randomly combines 4 coaching pictures right into a single picture. By creating these “mosaic” pictures, the mannequin encounters a greater variety of object mixtures and spatial preparations, enhancing its generalization capacity to unseen information.
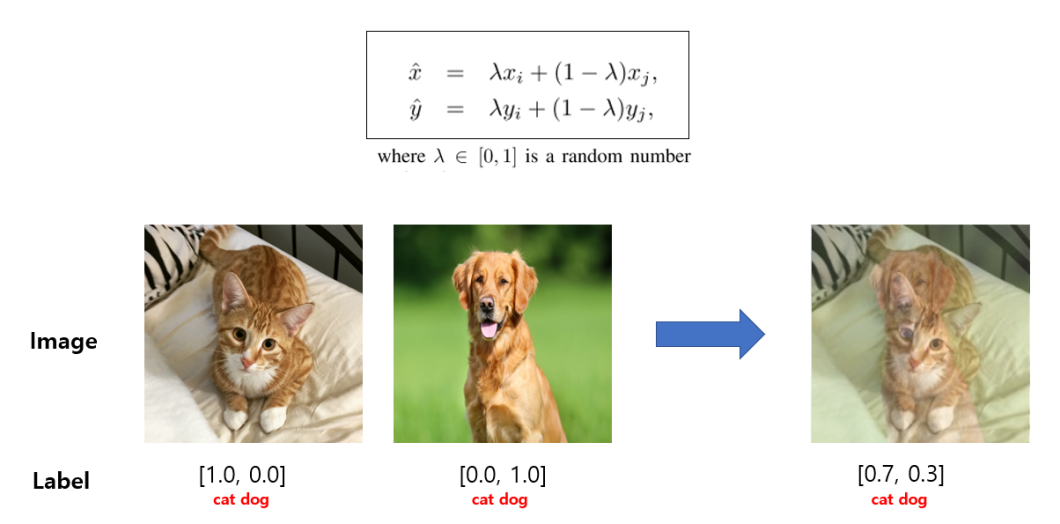
- MixUp Information Augmentation: This system blends two coaching pictures and their corresponding labels to create a brand new coaching instance. This “mixing up” course of helps the mannequin study strong options and enhance its capacity to deal with variations in real-world pictures.
Efficiency and Benchmarks
YOLOX with its decoupled head, anchor-free detection design, and superior label project technique achieves a rating of 47.3% AP (Common Precision) on the COCO dataset. It additionally is available in totally different variations (e.g., YOLOX-s, YOLOX-m, YOLOX-l) designed for various trade-offs between velocity and accuracy, with YOLOX-Nano being the lightest variation of YOLOX.
All of the YOLO mannequin scores are based mostly on the COCO dataset and examined at 640 x 640 decision on Tesla V100. Solely YOLO-Nano and YOLOX-Tiny had been examined at a decision of 416 x 461.
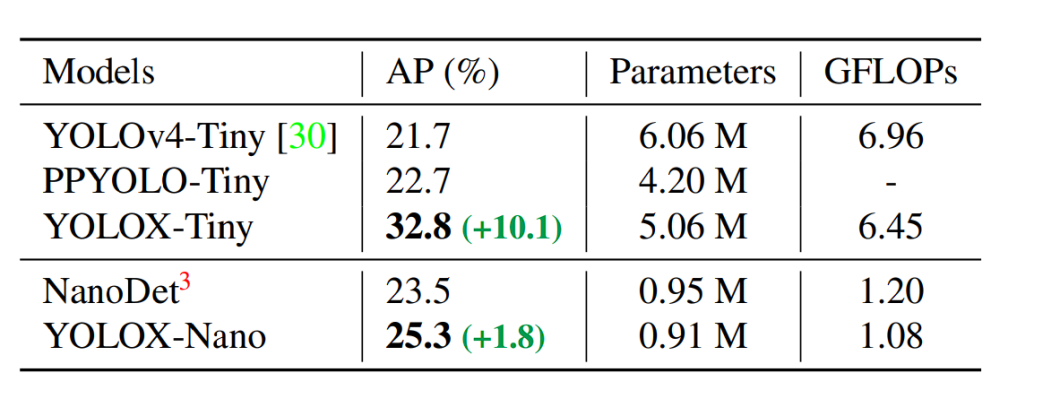
What’s AP?
In object detection, Common Precision (AP), also referred to as Imply Common Precision (mAP), serves as a key benchmark. The next AP rating signifies a greater performing mannequin. This metric permits us to instantly evaluate the effectiveness of various object detection fashions.
How does AP work?
AP summarizes the Precision-Recall Curve (PR Curve) for a mannequin right into a single quantity between 0 and 1, calculated on a number of metrics like intersection over union (IoU), precision, and recall.
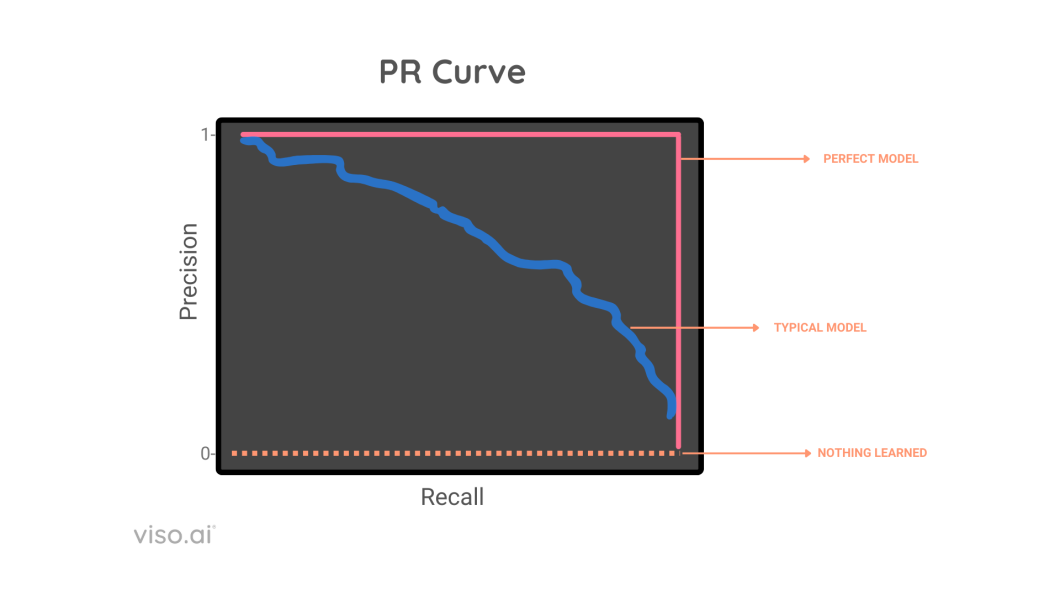
There exists a tradeoff between precision and recall, AP handles this by contemplating the world underneath the precision recall curve, after which it takes every pair of precision and recall, and averages them out to get imply common precision mAP.
- Precision:This refers back to the proportion of accurately labeled constructive instances (True Positives) out of all of the instances the mannequin predicts as constructive (True Positives + False Positives). It denotes how correct your mannequin is
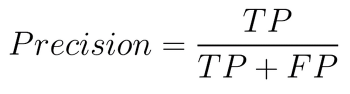
- Recall: Recall represents the proportion of accurately recognized constructive instances (True Positives) out of all of the precise constructive instances current within the information (True Positives + False Negatives). Recall displays if the mannequin is full or not (doesn’t miss the proper values).
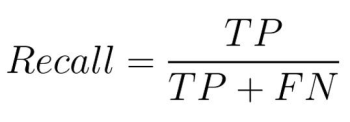
How To Select The Proper Mannequin?
The query of whether or not it’s best to use YOLOX in your challenge, or software comes right down to a number of key components.
- Accuracy vs. Velocity Commerce-off: Totally different variations of YOLO provide various balances between detection accuracy and inference velocity. As an example, later fashions like YOLOv8 and YOLOV9 enhance accuracy and velocity, however since are new, they lack group help.
- {Hardware} Constraints: {Hardware} is a key issue when selecting the best YOLO mannequin. Some variations of YOLOX, particularly the lighter fashions like YOLOX-Nano, are optimized for smartphones, nonetheless, they provide decrease AP%.
- Mannequin Dimension and Computational Necessities: Consider the mannequin measurement and the computational complexity (measured in FLOPs – Floating Level Operations Per Second) of the YOLO model you’re contemplating.
- Group Assist and Documentation: Given the speedy growth of the YOLO household, it’s essential to think about the extent of group help and documentation accessible for every model. A well-supported mannequin with complete documentation and an in depth group is essential.
Software of YOLOX
YOLOX is able to object detection in real-time makes it a priceless device for varied sensible functions together with:
- Actual-time object detection: YOLO’s real-time object detection capabilities have been invaluable in autonomous automobile techniques, enabling fast identification and monitoring of assorted objects corresponding to automobiles, pedestrians, bicycles, and different obstacles. These capabilities have been utilized in quite a few fields, together with motion recognition in video sequences for surveillance, sports activities evaluation, and human-computer interplay.
- Visitors Software:YOLO may be utilized for duties corresponding to license plate detection and site visitors signal recognition, contributing to the event of clever transportation techniques and site visitors administration options.

Visitors detection software – source - Retail trade (stock administration, product identification): YOLOX can be utilized in shops to automate stock administration by figuring out and monitoring merchandise on cabinets. Clients may also use it for self-checkout techniques the place they scan objects themselves.

Object detection for stock administration – source
Challenges and Way forward for YOLOX
- Generalization throughout Numerous Domains: Though YOLOX performs effectively on a wide range of datasets, its efficiency can nonetheless fluctuate relying on the precise traits of the dataset it’s skilled on. Advantageous-tuning and customization are essential to attain optimum efficiency on datasets with distinctive traits, corresponding to unusual object sizes, densities, or extremely particular domains.
- Adaptation to New Lessons or Eventualities: YOLOX is able to detecting a number of object lessons nonetheless, adapting the mannequin to new lessons or considerably totally different situations requires coaching information, which is usually a tough process to carry out accurately.
- Dealing with of Extraordinarily Small or Giant Objects: Regardless of enhancements over its predecessors, detecting extraordinarily small or giant objects throughout the similar picture can nonetheless pose challenges for YOLOX. This can be a frequent limitation of many object detection fashions, which can require specialised architectural tweaks or extra processing steps to deal with successfully.