

Throughout machine studying mannequin coaching, there are seven widespread errors that engineers and information scientists sometimes run into. Whereas receiving errors is irritating, groups should know easy methods to deal with these and the way they will keep away from them sooner or later.
Within the following, we’ll supply in-depth explanations, preventative measures, and fast fixes for recognized mannequin coaching points whereas addressing the query of “What does this mannequin error imply?”.
We are going to cowl a very powerful mannequin coaching errors, reminiscent of:
- Overfitting and Underfitting
- Knowledge Imbalance
- Knowledge Leakage
- Outliers and Minima
- Knowledge and Labeling Issues
- Knowledge Drift
- Lack of Mannequin Experimentation
About us: At viso.ai, we provide the Viso Suite, the primary end-to-end pc imaginative and prescient platform. It allows enterprises to create and implement pc imaginative and prescient options, that includes built-in ML instruments for information assortment, annotation, and mannequin coaching. Study extra about Viso Suite and ebook a demo.
Mannequin Error No. 1: Overfitting and Underfitting
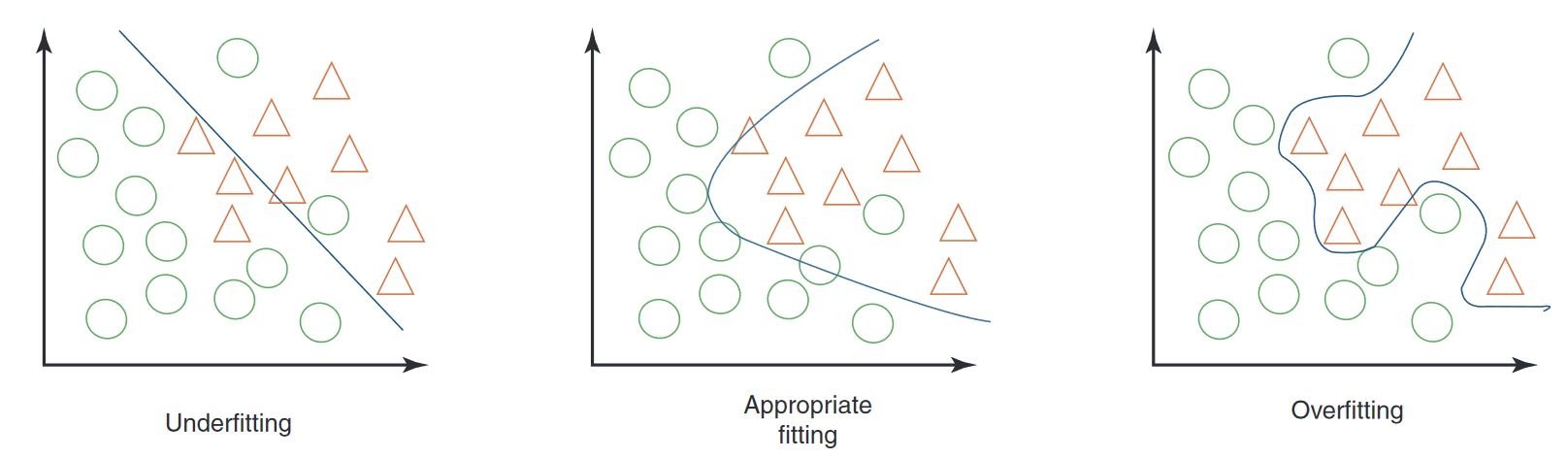
What’s Underfitting and Overfitting?
Some of the widespread issues in machine studying occurs when the coaching information is just not properly fitted to what the machine studying mannequin is meant to be taught.
In overfitting, there are too few examples for the ML mannequin to work on. It fails to give you the kind of sturdy evaluation that it’s purported to do. Underfitting is the other downside – there’s an excessive amount of to be taught, and the machine studying program is, in a way, overwhelmed by an excessive amount of information.
Find out how to Repair Underfitting and Overfitting
On this case, fixing the problem has loads to do with framing a machine-learning course of accurately. Correct becoming is like matching information factors to a map that’s not too detailed, however simply detailed sufficient. Builders are attempting to make use of the best dimensionality – to be sure that the coaching information matches its meant job.
To repair an overfitting downside, it’s endorsed to cut back layers and pursue cross-validation of the coaching set. Characteristic discount and regularization also can assist. For underfitting, alternatively, the purpose is commonly to construct in complexity, though consultants additionally recommend that eradicating noise from the information set would possibly assist, too.
For the pc imaginative and prescient activity of classification, you need to use a confusion matrix to guage mannequin efficiency, together with underfitting and overfitting situations, on a separate check set.
Mannequin Error No. 2: Knowledge Imbalance Points in Machine Studying
What’s Knowledge Imbalance?
Even should you’re certain that you’ve got given the machine studying mannequin sufficient examples to do its job, however not too many, you would possibly run into one thing known as ‘class imbalance’ or ‘information imbalance’.
Knowledge imbalance, a typical difficulty in linear regression fashions and prediction fashions, represents a scarcity of a consultant coaching information set for at the very least a number of the outcomes that you really want. In different phrases, if you wish to examine 4 or 5 lessons of photographs or objects, the entire coaching information is from one or two of these lessons. Which means the opposite three usually are not represented within the coaching information in any respect, so the mannequin won’t be able to work on them. It’s unfamiliar with these examples.
Find out how to Repair Knowledge Imbalance
To deal with an imbalance, groups will need to be sure that each a part of the main focus class set is represented within the coaching information. Instruments for troubleshooting bias and variance embrace auditing packages and detection fashions like IBM’s AI Fairness 360.
There’s additionally the bias/variance downside, the place some affiliate bias with coaching information units which are too easy, and extreme variance with coaching information units which are too advanced. In some methods, although, that is simplistic.
Bias has to do with improper clustering or grouping of information, and variance has to do with information that’s too unfold out. There’s much more element to this, however when it comes to fixing bias, the purpose is so as to add extra related information that’s numerous, to cut back bias that method. For variance, it typically helps so as to add information factors that may make developments clearer to the ML.
Mannequin Error No. 3: Knowledge Leakage
What’s Knowledge Leakage?
If this brings to thoughts the picture of a pipe leaking water, and you are concerned about information being misplaced from the system, that’s not likely what information leakage is about within the context of machine studying.
As an alternative, this can be a state of affairs the place info from the coaching information leaks into this system’s operational capability – the place the coaching information goes to have an excessive amount of of an impact on the evaluation of real-world outcomes.
In information leakage conditions, fashions can, for example, return excellent outcomes which are “too good to be true”, which can be an instance of information leakage.
Find out how to Repair Knowledge Leakage?
Throughout mannequin growth, there are a few methods to attenuate the danger of information leakage occurring:
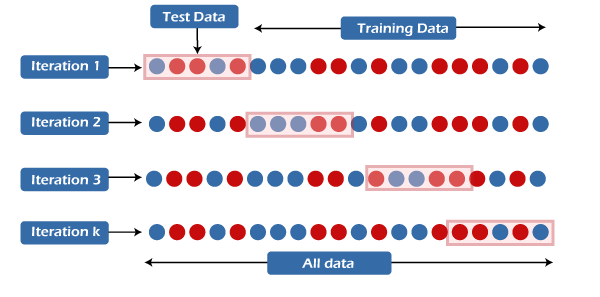
- Knowledge Preparation inside Cross-Validation Folds is carried out by recalculating scaling parameters individually for every fold.
- Withholding the Validation Dataset till the mannequin growth course of is full, permits you to see whether or not the estimated efficiency metrics have been overly optimistic and indicative of leakage.
Platforms like R and scikit-learn in Python are helpful right here. They use automation instruments just like the caret bundle in R and Pipelines in scikit-learn.
Mannequin Error No. 4: Outliers and Minima
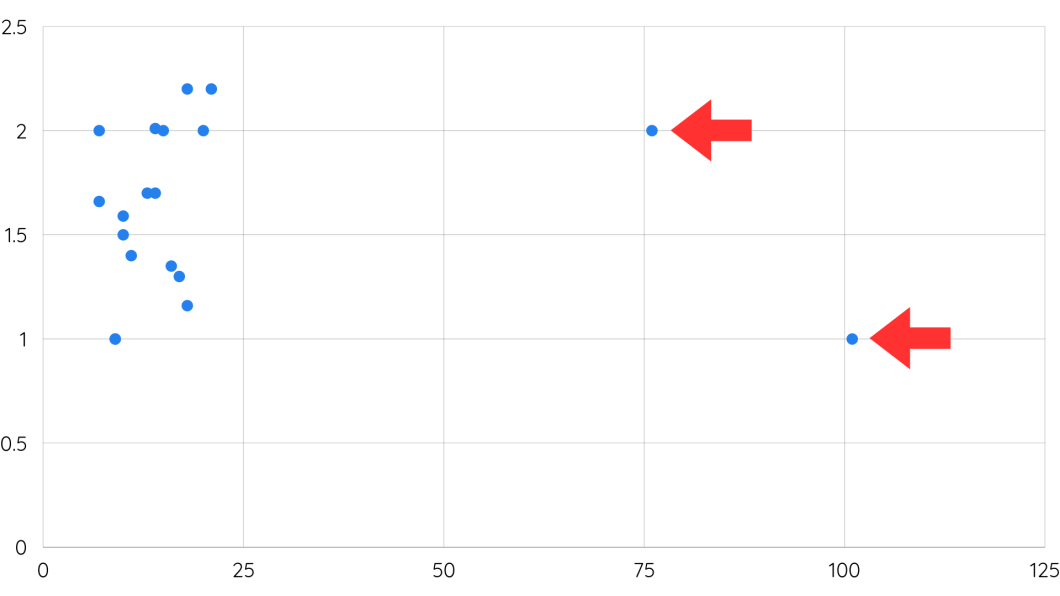
What are Knowledge Outliers?
It’s vital to look out for information outliers, or extra excessive information factors in a coaching information set, which might throw the mannequin off throughout coaching or later present false positives.
In machine studying, outliers can disrupt mannequin coaching by resulting in untimely convergence or suboptimal options, notably in native minima. Caring for outliers will assist be sure that the mannequin converges in direction of patterns within the information distribution.
Find out how to Repair Knowledge Outliers
Some consultants focus on challenges with world and native minima – once more, the concept the information factors are altering dynamically throughout a variety. Nonetheless, the machine studying program would possibly get trapped in a cluster of extra native outcomes, with out recognizing a number of the outlier information factors within the world set. The precept of trying globally at information is vital. It’s one thing that engineers ought to at all times construct into fashions.
- Algorithms like Random Forests or Gradient Boosting Machines are much less delicate to outliers basically.
- Algorithms like Isolation Forests and Native Outlier Issue handle outliers individually from the principle dataset.
- You possibly can alter skewed options or create new options much less delicate to outliers by utilizing strategies reminiscent of log transformations or scaling strategies.
Mannequin Error No. 5: Clerical Errors – Knowledge and Labeling Issues
What are Some Knowledge Labeling Issues?
Except for all of those engineering points with machine studying, there’s an entire set of different AI mannequin errors that may be problematic. These need to do with poor information hygiene.
These are very completely different sorts of points. Right here, it’s not this system’s technique that’s in error – as a substitute, there are errors within the information itself that skilled the mannequin on.
One in all these kinds of errors is named a labeling error. In supervised or semi-supervised studying programs, information is usually labeled. If the labels are incorrect, you’re not going to get the best consequence. So labeling errors are one thing to look out for early on within the course of.
Find out how to Repair Knowledge Labeling Issues
Then, there’s the issue of partial information units or lacking values. This can be a greater take care of uncooked or unstructured information that engineers and builders is likely to be utilizing to feed the machine studying program.
Knowledge scientists know in regards to the perils of unstructured information – however it’s not at all times one thing that ML engineers take into consideration – till it’s too late. Ensuring that the coaching information is appropriate is crucial within the course of.
By way of labeling and information errors, the true resolution is precision. Or name it ‘due diligence’ or ‘doing all your homework’. Going by way of the information with a fine-toothed comb is commonly what’s known as for. Nonetheless, earlier than the coaching course of, preventative measures are going to be key:
- Knowledge high quality assurance processes
- Iterative labeling
- Human-in-the-loop labeling (for verifying and correcting labels)
- Lively studying
Mannequin Error No. 6: Knowledge Drift
What’s Knowledge Drift?
There’s one other basic kind of mannequin coaching error in ML to look out for: it’s generally known as information drift.
Knowledge drift occurs when a mannequin turns into much less capable of carry out properly, due to modifications in information over time. Typically information drift occurs when a mannequin’s efficiency on new information differs from the way it offers with the coaching or check information.
There are various kinds of information drift, together with idea drift and a drift within the precise enter information. When the distribution of the enter information modifications over time, that may throw off this system.
In different circumstances, this system is probably not designed to deal with the sorts of change that programmers and engineers topic it to. That may be, once more, a problem of scope, concentrating on, or the timeline that folks use for growth. In the true world, information modifications typically.
Find out how to Repair Knowledge Drift
There are a number of approaches you possibly can take to fixing information drift, together with implementing algorithms such because the Kolmogorov-Smirrnov check, Inhabitants Stability Index, and Web page-Hinkley technique. This resource from Datacamp mentions a number of the finer factors of every kind of information drift instance:
- Steady Monitoring: Recurrently analyzing incoming information and evaluating it to historic information to detect any shifts.
- Characteristic Engineering: Deciding on options which are much less delicate to reworking options to make them extra secure over time.
- Adaptive Mannequin Coaching: Algorithms can modify the mannequin parameters in response to modifications within the information distribution.
- Ensemble Studying: Ensemble studying strategies to mix a number of fashions skilled on completely different subsets of information or utilizing completely different algorithms.
- Knowledge Preprocessing and Resampling: Recurrently preprocess the information and resample it with strategies reminiscent of information augmentation, artificial information technology, or stratified sampling so it stays consultant of the inhabitants.
Mannequin Error No. 7: Lack of Mannequin Experimentation
What’s Mannequin Experimentation?
Mannequin experimentation is the iterative strategy of testing and refining mannequin designs to optimize efficiency. It entails exploring completely different architectures, hyperparameters, and coaching methods to establish the simplest mannequin for a given activity.
Nonetheless, a serious AI mannequin coaching error can come up when builders don’t solid a large sufficient internet in designing ML fashions. This occurs when customers prematurely choose the primary mannequin they prepare with out exploring different designs or contemplating alternate prospects.
Find out how to Repair Lack of Mannequin Experimentation
Reasonably than making the primary mannequin the one mannequin, many consultants would suggest making an attempt out a number of designs, and triangulating which one goes to work finest for a specific challenge. A step-by-step course of for this might appear to be:
- Step One: Set up a framework for experimentation to look at varied mannequin architectures and configurations. To evaluate mannequin efficiency, you’ll check different algorithms, modify hyperparameters, and experiment with completely different coaching datasets.
- Step Two: Use instruments and strategies for systematic mannequin analysis, reminiscent of cross-validation strategies and efficiency metrics evaluation.
- Step Three: Prioritize steady enchancment throughout the mannequin coaching course of.
Staying Forward of Mannequin Coaching Errors
When fine-tuning your mannequin, you’ll must proceed to create an error evaluation. This can aid you hold monitor of errors and encourage steady enhancements. Thus, serving to you maximize efficiency to yield helpful outcomes.
Coping with machine studying mannequin errors will develop into extra acquainted as you go. Like testing for software program packages, error correction for machine studying is a key a part of the worth course of.