

Jeffrey Heninger, 22 November 2022
I used to be just lately studying the outcomes of a survey asking local weather consultants about their opinions on geoengineering. The outcomes shocked me: “We discover that respondents who anticipate extreme international local weather change damages and who’ve little confidence in present mitigation efforts are extra against geoengineering than respondents who’re much less pessimistic about international damages and mitigation efforts.” This appears backwards. Shouldn’t individuals who assume that local weather change will likely be unhealthy and that our present efforts are inadequate be extra prepared to debate and analysis different methods, together with deliberately cooling the planet?
I have no idea what they’re pondering, however I could make a guess that may clarify the consequence: individuals are responding utilizing a ‘common issue of doom’ as a substitute of contemplating the questions independently. Every local weather professional has a p(Doom) for local weather change, or maybe a extra obscure feeling of doominess. Their acknowledged beliefs on particular questions are principally simply expressions of their p(Doom).
If my guess is appropriate, then individuals first determine how doomy local weather change is, after which they use this common issue of doom to reply the questions on severity, mitigation efforts, and geoengineering. I don’t understand how individuals set up their doominess: it could be because of desirous about one particular query, or it could be primarily based on whether or not they’re extra optimistic or pessimistic total, or it could be one thing else. As soon as they’ve a common issue of doom, it determines how they reply to particular questions they subsequently encounter. I feel that individuals ought to as a substitute determine their solutions to particular questions independently, mix them to type a number of believable future pathways, after which use these to find out p(Doom). Utilizing a mannequin with extra particulars is harder than utilizing a common issue of doom, so it might not be shocking if few individuals did it.
To tell apart between these two prospects, we might ask individuals a group of particular questions which can be all doom-related, however are usually not clearly related to one another. For instance:
- How a lot would the Asian monsoon weaken with 1°C of warming?
- How many individuals can be displaced by a 50 cm rise in sea ranges?
- How a lot carbon dioxide will the US emit in 2040?
- How would vegetation development be completely different if 2% of incoming daylight had been scattered by stratospheric aerosols?
If the solutions to all of those questions had been correlated, that may be proof for individuals utilizing a common issue of doom to reply these questions as a substitute of utilizing a extra detailed mannequin of the world.
I’m wondering if the same phenomenon may very well be occurring in AI Alignment analysis.
We will assemble a listing of particular questions which can be related to AI doom:
- How lengthy are the timelines till somebody develops AGI?
- How arduous of a takeoff will we see after AGI is developed?
- How fragile are good values? Are two related moral methods equally good?
- How arduous is it for individuals to show a worth system to an AI?
- How arduous is it to make an AGI corrigible?
- Ought to we anticipate easy alignment failures to happen earlier than catastrophic alignment failures?
- How probably is human extinction if we don’t discover a resolution to the Alignment Drawback?
- How arduous is it to design a very good governance mechanism for AI capabilities analysis?
- How arduous is it to implement and implement a very good governance mechanism for AI capabilities analysis?
I don’t have any good proof for this, however my obscure impression is that many individuals’s solutions to those questions are correlated.
It will not be too shocking if some pairs of those questions must be correlated. Totally different individuals would probably disagree on which issues must be correlated. For instance, Paul Christiano appears to assume that brief timelines and quick takeoff speeds are anti-correlated. Another person would possibly categorize these questions as ‘AGI is straightforward’ vs. ‘Aligning issues is tough’ and anticipate correlations inside however not between these classes. Individuals may additionally disagree on whether or not individuals and AGI will likely be related (so aligning AGI and aligning governance are equally arduous) or very completely different (so instructing AGI good values is way more durable than instructing individuals good values). With all of those numerous arguments, it might be shocking if beliefs throughout all of those questions had been correlated. In the event that they had been, it might recommend {that a} common issue of doom is driving individuals’s beliefs.
There are a number of biases which appear to be associated to the overall issue of doom. The halo impact (or horns impact) is when a single good (or unhealthy) perception about an individual or model causes somebody to imagine that that individual or model is sweet (or unhealthy) in lots of different methods. The fallacy of temper affiliation is when somebody’s response to an argument is predicated on how the argument impacts the temper surrounding the difficulty, as a substitute of responding to the argument itself. The final issue of doom is a extra particular bias, and feels much less like an emotional response: Individuals have detailed arguments describing why the longer term will likely be maximally or minimally doomy. The futures described are believable, however contemplating how a lot disagreement there’s, it might be shocking if just a few believable futures are centered on and if these futures have equally doomy predictions for a lot of particular questions. I’m additionally reminded of Beware Shocking and Suspicious Convergence, though it focuses extra on beliefs that aren’t up to date when somebody’s worldview adjustments, as a substitute of on beliefs inside a worldview that are surprisingly correlated.
The AI Impacts survey might be not related to figuring out if AI security researchers have a common issue of doom. The survey was of machine studying researchers, not AI security researchers. I spot checked a number of random pairs of doom-related questions anyway, and so they didn’t look correlated. I’m undecided whether or not to interpret this to imply that they’re utilizing a number of detailed fashions or that they don’t actually have a easy mannequin.
There’s additionally this graph, which claims to be “wildly out-of-date and chock full of big outrageous errors.” This graph appears to recommend some correlation between two completely different doom-related questions, and that the distribution is surprisingly bimodal. If we had been to take this extra severely than we most likely ought to, we might use it as proof for a common issue of doom, and that most individuals’s p(Doom) is near 0 or 1. I don’t assume that this graph is especially sturdy proof even whether it is correct, nevertheless it does gesture in the identical course that I’m pointing at.
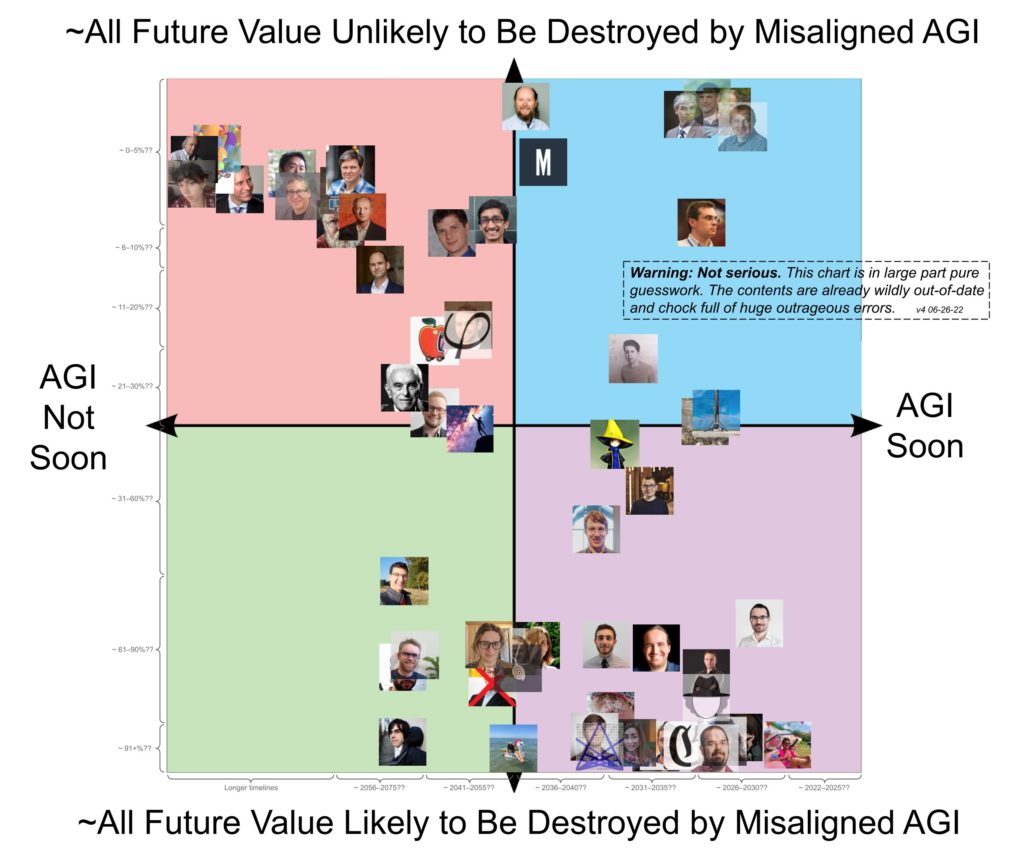
It will be attention-grabbing to do an precise survey of AI security researchers, with extra than simply two questions, to see how intently all the responses are correlated with one another. It will even be attention-grabbing to see whether or not doominess in a single subject is correlated with doominess in different fields. I don’t know whether or not this survey would present proof for a common issue of doom amongst AI security researchers, nevertheless it appears believable that it might.