
Over time, the creation of real looking and expressive portraits animations from static photographs and audio has discovered a variety of purposes together with gaming, digital media, digital actuality, and much more. Regardless of its potential software, it’s nonetheless troublesome for builders to create frameworks able to producing high-quality animations that keep temporal consistency and are visually fascinating. A significant trigger for the complexity is the necessity for intricate coordination of lip actions, head positions, and facial expressions to craft a visually compelling impact.
On this article, we will probably be speaking about AniPortrait, a novel framework designed to generate high-quality animations pushed by a reference portrait picture and an audio pattern. The working of the AniPortrait framework is split into two phases. First, the AniPortrait framework extracts the intermediate 3D representations from the audio samples, and tasks them right into a sequence of 2D facial landmarks. Following this, the framework employs a strong diffusion mannequin coupled with a movement module to transform the landmark sequences into temporally constant and photorealistic animations. The experimental outcomes exhibit the prevalence and talent of the AniPortrait framework to generate top quality animations with distinctive visible high quality, pose range, and facial naturalness, subsequently providing an enhanced and enriched perceptual expertise. Moreover, the AniPortrait framework holds outstanding potential by way of controllability and suppleness, and will be utilized successfully in areas together with facial reenactment, facial movement modifying, and extra. This text goals to cowl the AniPortrait framework in depth, and we discover the mechanism, the methodology, the structure of the framework together with its comparability with state-of-the-art frameworks. So let’s get began.
Creating real looking and expressive portrait animations has been the main focus of researchers for some time now owing to its unbelievable potential and purposes spanning from digital media and digital actuality to gaming and extra. Regardless of years of analysis and growth, producing high-quality animations that keep temporal consistency and are visually fascinating nonetheless presents a major problem. A significant hurdle for builders is the necessity for intricate coordination between head positions, visible expressions, and lip actions to craft a visually compelling impact. Current strategies have did not sort out these challenges, primarily since a majority of them depend on restricted capability turbines like NeRF, motion-based decoders, and GAN for visible content material creation. These networks exhibit restricted generalization capabilities, and are unstable in producing top quality content material. Nonetheless, the current emergence of diffusion fashions has facilitated the technology of high-quality photographs, and a few frameworks constructed on prime of diffusion fashions together with temporal modules have facilitated the creation of compelling movies, permitting diffusion fashions to excel.
Constructing upon the developments of diffusion fashions, the AniPortrait framework goals to generate top quality animated portraits utilizing a reference picture, and an audio pattern. The working of the AniPortrait framework is cut up in two phases. Within the first stage, the AniPortrait framework employs transformer-based fashions to extract a sequence of 3D facial mesh and head pose from audio enter, and tasks them subsequently right into a sequence of 2D facial landmarks. The primary stage facilitates the AniPortrait framework to seize lip actions and delicate expressions from the audio along with head actions that synchronize with the rhythm of the audio pattern. The second stage, the AniPortrait framework employs a strong diffusion mannequin and integrates it with a movement module to rework the facial landmark sequence right into a photorealistic and temporally constant animated portrait. To be extra particular, the AniPortrait framework attracts upon the community structure from the prevailing AnimateAnyone mannequin that employs Steady Diffusion 1.5, a potent diffusion mannequin to generate lifelike and fluid based mostly on a reference picture and a physique movement sequence. What’s value noting is that the AniPortrait framework doesn’t use the pose guider module inside this community because it carried out in AnimateAnyone framework, but it surely redesigns it, permitting the AniPortrait framework not solely to take care of a light-weight design but in addition displays enhanced precision in producing lip actions.
Experimental outcomes exhibit the prevalence of the AniPortrait framework in creating animations with spectacular facial naturalness, wonderful visible high quality, and diversified poses. By using 3D facial representations as intermediate options, the AniPortrait framework positive aspects the pliability to change these representations as per its necessities. The adaptability considerably enhances the applicability of the AniPortrait framework throughout domains together with facial reenactment and facial movement modifying.
AniPortrait: Working and Methodology
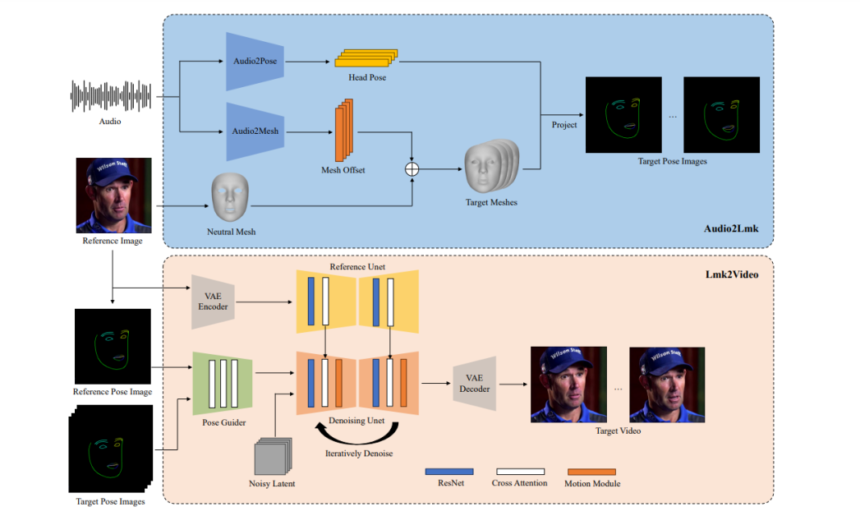
The proposed AniPortrait framework includes two modules, specifically Lmk2Video, and Audio2Lmk. The Audio2Lmk module makes an attempt to extract a sequence of landmarks that captures intricate lip actions and facial expressions from audio enter whereas the Lmk2Video module makes use of this landmark sequence to generate high-quality portrait movies with temporal stability. The next determine presents an summary of the working of the AniPortrait framework. As it may be noticed, the AniPortrait framework first extracts the 3D facial mesh and head pose from the audio, and tasks these two components into 2D key factors subsequently. Within the second stage, the framework employs a diffusion mannequin to rework the 2D key factors right into a portrait video with two phases being skilled concurrently inside the community.

Audio2Lmk
For a given sequence of speech snippets, the first purpose of the AniPortrait framework is to foretell the corresponding 3D facial mesh sequence with vector representations of translation and rotation. The AniPortrait framework employs the pre-trained wav2vec technique to extract audio options, and the mannequin displays a excessive diploma of generalization, and is able to recognizing intonation and pronunciation from the audio precisely that performs a vital position in producing real looking facial animations. By leveraging the acquired sturdy speech options, the AniPortrait framework is ready to successfully make use of a easy structure consisting of two fc layers to transform these options into 3D facial meshes. The AniPortrait framework observes that this easy design carried out by the mannequin not solely enhances the effectivity of the inference course of, but in addition ensures accuracy. When changing audio to pose, the AniPortrait framework employs the identical wav2vec community because the spine, though the mannequin doesn’t share the weights with the audio to mesh module. It’s majorly resulting from the truth that pose is related extra with tone and rhythm current within the audio, which holds a special emphasis in comparison towards audio to mesh duties. To account for the impression of the earlier states, the AniPortrait framework employs a transformer decoder to decode the pose sequence. Throughout this course of, the framework integrates the audio options into the decoder utilizing cross-attention mechanisms, and for each the modules, the framework trains them utilizing the L1 loss. As soon as the mannequin obtains the pose and mesh sequence, it employs perspective projection to rework these sequences right into a 2D sequence of facial landmarks which might be then utilized as enter alerts for the next stage.
Lmk2Video
For a given reference portrait picture and a sequence of facial landmarks, the proposed Lmk2Video module creates a temporally constant portrait animation, and this animation aligns the movement with the landmark sequence, and maintains an look that’s in consistency with the reference picture, and at last, the framework represents the portrait animation as a sequence of portrait frames. The design of the Lmk2Video’s community construction seeks inspiration from the already present AnimateAnyone framework. The AniPortrait framework employs a Steady Diffusion 1.5, a particularly potent diffusion mannequin as its spine, and incorporates a temporal movement module that successfully converts multi-frame noise inputs right into a sequence of video frames. On the identical time, a ReferencenNet community element mirrors the construction of Steady Diffusion 1.5, and employs it to extract the looks info from the reference picture, and integrates it into the spine. The strategic design ensures that the facial ID stays constant all through the output video. Differentiating from the AnimateAnyone framework, the AniPortrait framework enhances the complexity of the PoseGuider’s design. The unique model of the AnimateAnyone framework includes only some convolution layers submit which the landmark options merge with the latents a the enter layer of the spine. The AniPortrait framework discovers that the design falls quick in capturing intricate actions of the lips, and to sort out this problem, the framework adopts the multi-scale technique of the ConvNet structure, and incorporates landmark options of corresponding scales into completely different blocks of the spine. Moreover, the AniPortrait framework introduces a further enchancment by together with the landmarks of the reference picture as a further enter. The cross-attention module of the PoseGuider element facilitates the interplay between the goal landmarks of every body and the reference landmarks. This course of offers the community with extra cues to grasp the correlation between look and facial landmarks, thus aiding within the technology of portrait animations with extra exact movement.
AniPortrait: Implementation and Consequence
For the Audio2Lmk stage, the AniPortrait framework adopts the wav2vec2.0 element as its spine, and leverages the MediaPipe structure to extract 3D meshes and 6D poses for annotations. The mannequin sources the coaching knowledge for the Audio2Mesh element from its inside dataset that includes almost 60 minutes of high-quality speech knowledge sourced from a single speaker. To make sure the 3D mesh extracted by the MediaPipe element is secure, the voice actor is instructed to face the digicam, and keep a gradual head place through the entirety of the recording course of. For the Lmk2Video module, the AniPortrait framework implements a two-stage coaching method. Within the first stage, the framework focuses on coaching ReferenceNet, and PoseGuider, the 2D element of the spine, and leaves out the movement module. Within the second step, the AniPortrait framework freezes all the opposite elements, and concentrates on coaching the movement module. For this stage, the framework makes use of two large-scale high-quality facial video datasets to coach the mannequin, and processes all the info utilizing the MediaPipe element to extract 2D facial landmarks. Moreover, to reinforce the sensitivity of the community in the direction of lip actions, the AniPortrait mannequin differentiates the higher and decrease lips with distinct colours when rendering the pose picture from 2D landmarks.
As demonstrated within the following picture, the AniPortrait framework generates a collection of animations that exhibit superior high quality in addition to realism.

The framework then makes use of an intermediate 3D illustration that may be edited to govern the output as per the necessities. As an example, customers can extract landmarks from a sure supply and alter its ID, subsequently permitting the AniPortrait framework to create a facial reenactment impact.
Closing Ideas
On this article, we have now talked about AniPortrait, a novel framework designed to generate high-quality animations pushed by a reference portrait picture and an audio pattern. By merely inputting a reference picture and an audio clip, the AniPortrait framework is able to producing a portrait video that options pure motion of heads, and clean lip movement. By leveraging the sturdy generalization capabilities of the diffusion mannequin, the AniPortrait framework generates animations that show spectacular real looking picture high quality, and lifelike movement. The working of the AniPortrait framework is split into two phases. First, the AniPortrait framework extracts the intermediate 3D representations from the audio samples, and tasks them right into a sequence of 2D facial landmarks. Following this, the framework employs a strong diffusion mannequin coupled with a movement module to transform the landmark sequences into temporally constant and photorealistic animations. The experimental outcomes exhibit the prevalence and talent of the AniPortrait framework to generate top quality animations with distinctive visible high quality, pose range, and facial naturalness, subsequently providing an enhanced and enriched perceptual expertise. Moreover, the AniPortrait framework holds outstanding potential by way of controllability and suppleness, and will be utilized successfully in areas together with facial reenactment, facial movement modifying, and extra.

