
Laptop imaginative and prescient fashions allow the machine to extract, analyze, and acknowledge helpful data from a set of photos. Light-weight laptop imaginative and prescient fashions enable the customers to deploy them on cellular and edge gadgets.
Immediately’s growth in CV began with the implementation of deep studying fashions and convolutional neural networks (CNN). The principle CV strategies embrace picture classification, picture localization, detecting objects, and segmentation.
This text lists essentially the most vital light-weight laptop imaginative and prescient fashions SMEs can effectively implement of their day by day duties. We’ve cut up the light-weight fashions into 4 completely different classes: face recognition, healthcare, visitors, and general-purpose machine studying fashions.
About us: Viso Suite permits enterprise groups to appreciate worth with laptop imaginative and prescient in solely 3 days. By simply integrating into present tech stacks, Viso Suite makes it straightforward to automate inefficient and costly processes. Be taught extra by reserving a demo.
Light-weight Fashions for Face Recognition
DeepFace – Light-weight Face Recognition Analyzing Facial Attribute
DeepFace AI is Python’s light-weight face recognition and facial attribute library. The open-source DeepFace library consists of all fashionable AI fashions for contemporary face recognition. Subsequently, it could actually deal with all procedures for facial recognition within the background.
DeepFace is an open-source challenge written in Python and licensed below the MIT License. You may set up DeepFace from its GitHub library, revealed within the Python Package deal Index (PyPI).

DeepFace options embrace:
- Face Recognition: this activity finds a face in a picture database. Subsequently, to do face recognition, the algorithm usually runs face verification.
- Face Verification: customers apply this to check a candidate’s face to a different. Additionally, to substantiate {that a} bodily face matches the one in an ID doc.
- Facial Attribute Evaluation: describes the visible properties of face photos. Accordingly, customers apply it to extract attributes resembling age, gender, feelings, and so forth.
- Actual-Time Face Evaluation: makes use of the real-time video feed of your webcam.
MobileFaceNets (MFN) – CNNs for Actual-Time Face Verification
Chen et al. (2018) revealed their analysis titled MobileFaceNets. Their mannequin is an environment friendly CNN for Correct Actual-Time Face Verification on Cell Gadgets. They used lower than 1 million parameters. They tailored the mannequin for high-accuracy real-time face verification on cellular and embedded gadgets.
Additionally, they analyzed the weak spot of earlier cellular networks for face verification. They skilled it by ArcFace loss on the refined MS-Celeb-1M. MFN of 4.0MB dimension achieved 99.55% accuracy on LFW.
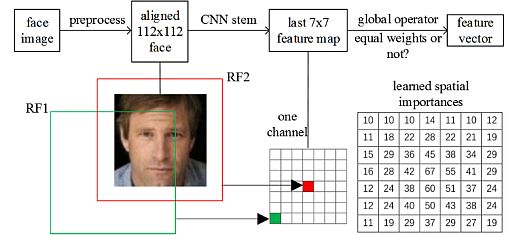
Mannequin traits:
- All convolutional layers in the identical sequence have the identical quantity c of output channels. The primary layer of every sequence has a stride S and all others use stride 1.
- All spatial convolutions within the bottlenecks use 3 × 3 kernels. Therefore, the researchers utilized growth issue t to the enter batch.
- MFN supplies improved effectivity over earlier state-of-the-art cellular CNNs for face verification.
EdgeFace – Face Recognition Mannequin for Edge Gadgets
Researchers A. George, C. Ecabert, et al. (2015) revealed a paper referred to as EdgeFace or Environment friendly Face Recognition Mannequin. This paper launched EdgeFace, a light-weight and environment friendly face recognition community impressed by the hybrid structure of EdgeNeXt. Thus, EdgeFace achieved glorious face recognition efficiency optimized for edge gadgets.
The proposed EdgeFace community had low computational prices and required fewer computational sources and compact storage. Additionally, it achieved excessive face recognition accuracy, making it appropriate for deployment on edge gadgets. EdgeFace mannequin was top-ranked amongst fashions with lower than 2M parameters within the IJCB 2023 Face Recognition Competitors.
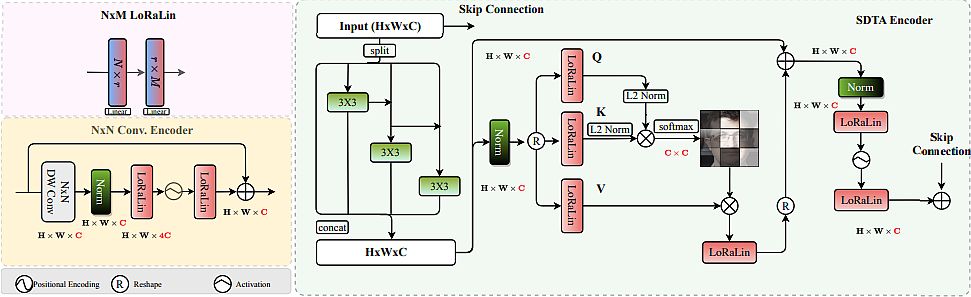
Mannequin Traits:
- Leveraged environment friendly hybrid structure and LoRaLin layers, thus reaching outstanding efficiency whereas sustaining low computational complexity.
- Demonstrated effectivity on numerous face recognition benchmarks, together with LFW and AgeDB-30
- EdgeFace presents an environment friendly and extremely correct face recognition mannequin appropriate for edge (cellular) gadgets.
Healthcare CV Fashions
MedViT: A Strong Imaginative and prescient Transformer for Medical Picture Recognition
Manzari et al. (2023) published the research MedViT – A Strong Imaginative and prescient Transformer for Generalized Medical Picture Recognition. They proposed a sturdy but environment friendly CNN-Transformer hybrid mannequin geared up with CNNs and international integration of imaginative and prescient Transformers.
The authors carried out knowledge augmentation on picture form data by permuting the characteristic imply and variance inside mini-batches. Along with its low complexity, their hybrid mannequin demonstrated its excessive robustness. Researchers in contrast it to the opposite approaches that make the most of MedMNIST-2D dataset.
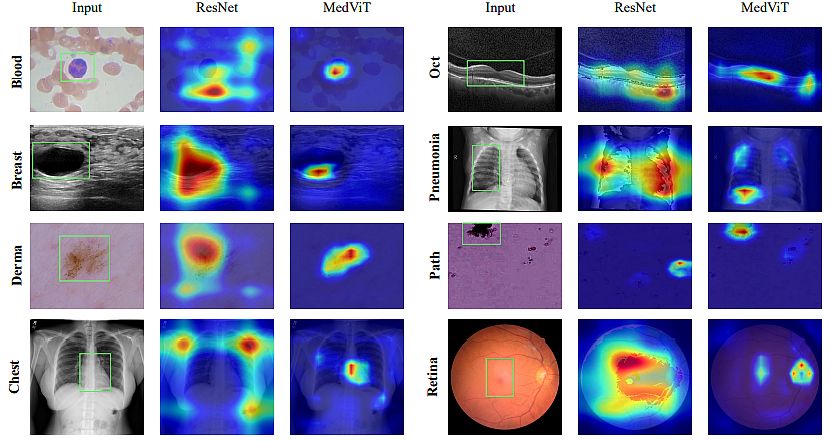
Mannequin traits:
- They skilled all MedViT variants for 100 epochs on NVIDIA 2080Ti GPUs. Additionally, they utilized a batch dimension of 128 as a coaching dataset pattern.
- They used an AdamW optimizer with a studying fee of 0.001, thus decreasing it by an element of 0.1.
- MedViT-S confirmed superior studying capacity on each analysis metrics. Subsequently, it achieved a rise of two.3% (AUC) in RetinaMNIST.
MaxCerVixT: A Light-weight Transformer-based Most cancers Detection
Pacal (2024) launched an advanced framework (architecture), the Multi-Axis Imaginative and prescient Transformer (MaxViT). He addressed the challenges in Pap check accuracy. Pacal carried out a large-scale research with a complete of 106 deep studying fashions. As well as, he utilized 53 CNN-based and 53 imaginative and prescient transformer-based fashions for every dataset.
He substituted MBConv blocks within the MaxViT structure with ConvNeXtv2 blocks and MLP blocks with GRN-based MLPs. That change diminished parameter counts and likewise enhanced the mannequin’s recognition capabilities. As well as, he evaluated the proposed methodology utilizing the publicly accessible SIPaKMeD and Mendeley LBC, Pap smear datasets.
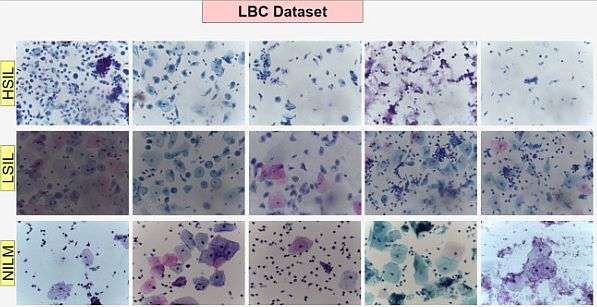
Mannequin traits:
- Compared with experimental and state-of-the-art strategies, the proposed methodology demonstrated superior accuracy.
- Additionally, compared with a number of CNN-based fashions, the strategy achieved a quicker inference velocity (6 ms).
- It surpassed all present deep studying fashions, thus reaching 99.02% accuracy on the SIPaKMeD dataset. Additionally, the mannequin achieved 99.48% accuracy on the LBC dataset.
Light-weight CNN Structure for Anomaly Detection in E-health
Yatbaz et al. (2021) published their research Anomaly Detection in E-Well being Functions Utilizing Light-weight CNN Structure. The authors used ECG knowledge for the prediction of cardiac stress actions. Furthermore, they examined the proposed deep studying mannequin on the MHEALTH dataset with two completely different validation strategies.
The experimental outcomes confirmed that the mannequin achieved as much as 97.06% accuracy for the cardiac stress degree. As well as, the mannequin for ECG prediction was lighter than the prevailing approaches with sizes of 1.97 MB.
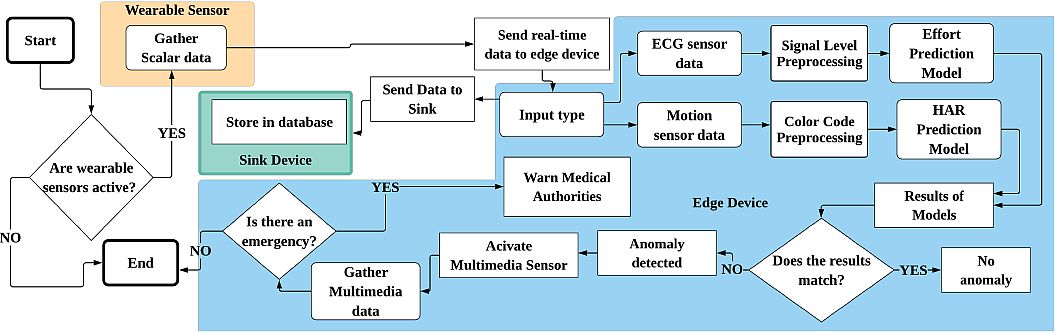
Mannequin traits:
- For shade code era, researchers extracted every sensory enter inside every windowing exercise. They examined their deep studying mannequin on the M-Well being dataset.
- For ECG knowledge they utilized a mapping algorithm from actions to effort ranges and a light-weight CNN structure.
- Relating to complexity, the ECG-based mannequin had parameters of 1.0410 GFLOPS and a mannequin dimension of 1.97 MB.
Visitors / Automobiles Recognition Fashions
Light-weight Automobiles Detection Community mannequin based mostly on YOLOv5
Wang et al. (2024) published their research Light-weight Car Detection Based mostly on Improved YOLOv5. They utilized built-in perceptual consideration, with few parameters and excessive detection accuracy.
They proposed a light-weight module IPA with a Transformer encoder based mostly on built-in perceptual consideration. As well as, they achieved a discount within the variety of parameters whereas capturing international dependencies for richer contextual data.

Mannequin traits:
- A light-weight and environment friendly Multiscale Spatial Reconstruction module (MSCCR) with low parameter and computational complexity for characteristic studying.
- It consists of the IPA module and the MSCCR module within the YOLOv5s spine community. Thus, it reduces mannequin parameters and improves accuracy.
- The check outcomes confirmed that the mannequin parameters decreased by about 9%, and accuracy elevated by 3.1%. Furthermore, the FLOPS rating didn’t improve with the parameter quantity.
A Light-weight Car-Pedestrian Detection Based mostly on Consideration
Zhang et al. (2022) published their research Light-weight Car-Pedestrian Detection Algorithm Based mostly on Consideration Mechanism in Visitors Eventualities. They proposed an improved light-weight and high-performance vehicle-pedestrian detection algorithm based mostly on the YOLOv4.
To cut back parameters and enhance characteristic extraction, they changed the spine community CSPDarknet53 with MobileNetv2. Additionally, they used the strategy of multi-scale characteristic fusion to appreciate the data interplay amongst completely different characteristic layers.
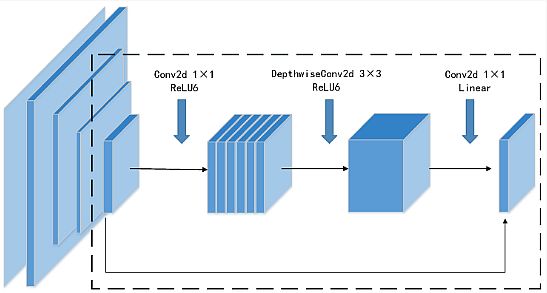
Mannequin traits:
- It comprises a coordinate consideration mechanism to deal with the area of curiosity within the picture by weight adjustment.
- The experimental outcomes confirmed that this improved mannequin has a fantastic efficiency in vehicle-pedestrian detection in visitors eventualities.
- Subsequently, the improved YOLOv4 mannequin maintains a fantastic steadiness between detection accuracy and velocity on completely different datasets. It surpassed the opposite tiny fashions for car detection.
Good Light-weight Visible Consideration Mannequin for Advantageous-Grained Car Recognition
Boukerche et al. (2023) published “Good Light-weight Visible Consideration Mannequin for Advantageous-Grained Car Recognition.” Their LRAU (Light-weight Recurrent Consideration Unit) extracted the discriminative options to find the important thing factors of a car.
They generated the eye masks utilizing the characteristic maps obtained by the LRAU and its previous consideration state. Furthermore, by using the usual CNN structure they obtained the multi-scale characteristic maps.
Mannequin traits:
- It underwent complete experiments on three difficult VMMR datasets to judge the proposed VMMR fashions.
- Experimental outcomes present their deep studying fashions have a steady efficiency below completely different circumstances.
- The fashions achieved state-of-the-art outcomes with 93.94% accuracy on the Stanford Automobiles dataset. Furthermore, they achieved 98.31% accuracy on the CompCars dataset.
Common Goal Light-weight CV Fashions
MobileViT: Light-weight, Common-purpose Imaginative and prescient Transformer
Mehta et al. (2022) revealed their research, MobileViT: Lightweight, Common-purpose, and Cell-friendly Imaginative and prescient Transformer. They mixed the strengths of CNNs and ViTs to construct a light-weight and low-latency community for cellular imaginative and prescient duties.
They launched MobileViT, a light-weight and general-purpose imaginative and prescient transformer for cellular gadgets. MobileViT supplies a special perspective for the worldwide processing of knowledge with transformers, i.e., transformers as convolutions.
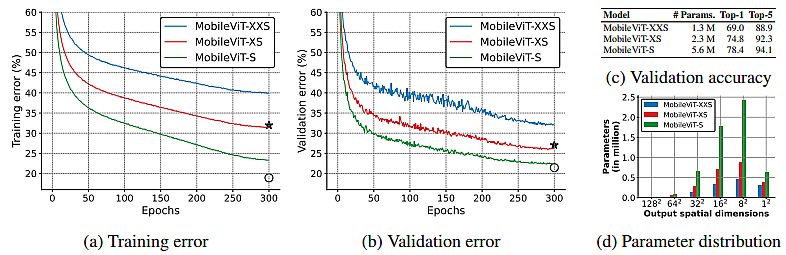
Mannequin traits:
- Outcomes confirmed that MobileViT considerably outperforms CNN- and ViT-based networks throughout completely different duties and coaching knowledge units.
- On the ImageNet-1k dataset, MobileViT achieved top-1 accuracy of 78.4% with about 6 million parameters. The light-weight mannequin is 6.2% extra correct than MobileNetv3 (CNN-based).
- On the MS-COCO real-time object detection activity, MobileViT is 5.7% extra correct than MobileNetv3. Additionally, it carried out quicker for the same variety of parameters.
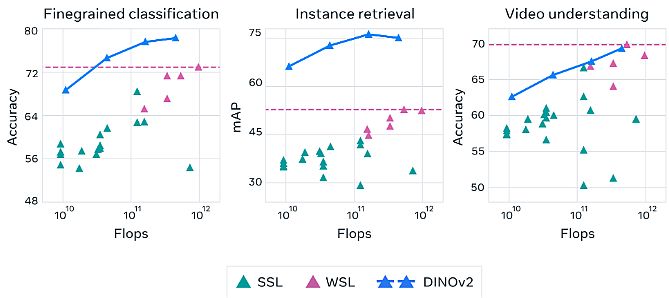
DINOv2: Studying Strong Visible Options with out Supervision
In April 2023 Meta revealed their DINOv2: State-of-the-art laptop imaginative and prescient pre-trained fashions with self-supervised studying. DINOv2 supplies high-performance options, together with easy linear classifiers. Subsequently, customers make the most of DINOv2 to create multipurpose backbones for a lot of completely different laptop imaginative and prescient duties.
- Relating to knowledge, the authors proposed an automated pipeline to construct a devoted, numerous, and curated picture dataset.
- They skilled a ViT mannequin with 1B parameters and distilled it right into a collection of smaller/tiny fashions.
- It surpassed the perfect accessible general-purpose options, OpenCLIP on many of the benchmarks at picture and pixel ranges.
- DINOv2 delivers robust efficiency and doesn’t require fine-tuning. Thus, it’s appropriate to be used as a spine for a lot of completely different laptop imaginative and prescient duties.
Viso Suite: No-code Laptop Imaginative and prescient Platform
Viso Suite is an end-to-end laptop imaginative and prescient platform. Companies use it to construct, deploy, and monitor real-world laptop imaginative and prescient purposes. Additionally, Viso is a no-code platform that makes use of state-of-the-art CV fashions – OpenCV, Tensor Stream, and PyTorch.
- It consists of over 15 merchandise in a single resolution, together with picture annotation, mannequin coaching, and no-code app improvement. Additionally, it supplies machine administration, IoT communication, and customized dashboards.
- The model-driven structure supplies a sturdy and safe infrastructure to construct laptop imaginative and prescient pipelines with constructing blocks.
- Excessive flexibility supplies the addition of customized code or integration with Tableau, PowerBI, SAP, or exterior databases (AWS-S3, MongoDB, and so forth.).
- Enterprises use Viso Suite to construct and function state-of-the-art CV purposes. Subsequently, we’ve purchasers in trade, visible inspection, distant monitoring, and so forth.
What’s Subsequent?
Light-weight laptop imaginative and prescient fashions are helpful on cellular and edge gadgets since they require low processing and storage sources. Therefore, they’re important in lots of enterprise purposes. Viso.ai with its confirmed experience can lead you to implement your profitable CV mannequin.
Our platform presents complete instruments for constructing, deploying, and managing CV apps on completely different gadgets. The light-weight pre-trained fashions are relevant in a number of industries. We offer laptop imaginative and prescient fashions on the sting – the place occasions and actions occur.
To be taught extra in regards to the world of machine studying and laptop imaginative and prescient, try our different blogs: