
Convolution Neural Networks (CNNs) have been profitable in fixing frequent issues associated to pc imaginative and prescient duties, leading to remarkably low check errors for duties like picture classification and object detection. Regardless of the success of CNNs, they’ve a number of drawbacks and limitations. Capsule Networks addresses these limitations.
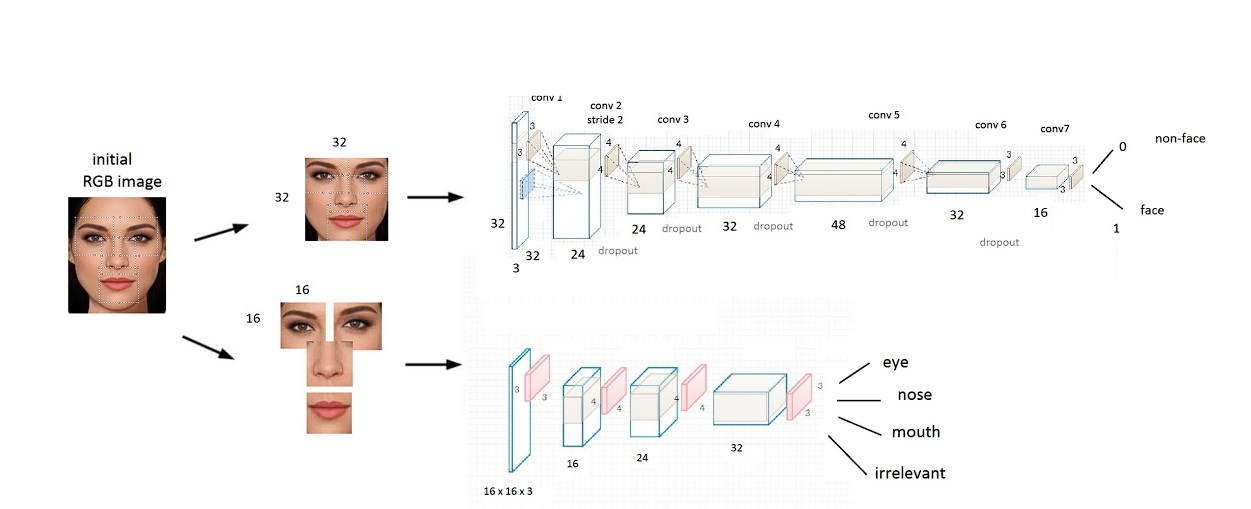
CNNs extract options of a picture in steps. Layers close to the beginning detect easy options like edges and shapes, and deeper layers detect high-level options like eyes, noses, or a complete face. And at last, the community predicts the item.
The Max Pooling operation in CNNs causes the lack of most details about spatial relationships (like measurement and orientation) between the layers. The lack of details about orientation makes the mannequin prone to getting confused.
Capsule Networks tries to resolve the constraints of CNNs by preserving data and consequently, have achieved an accuracy rating of 99.87% on the MNIST dataset.
This weblog will clarify the workings of Capsule Community, created by Geoffrey Hinton and his machine studying staff.
Limitation of CNNs
- Lack of spatial data: CNNs use pooling operations like max-pooling to scale back picture measurement and create picture illustration. This helps the mannequin to realize translational invariance (recognizing objects no matter place). Nonetheless, this discards beneficial details about an object’s components and their association.
- Viewpoint variance: CNNs wrestle with recognizing objects from totally different viewpoints (rotations, translations, and slight deformations). To deal with this concern, the mannequin is skilled on an enormous quantity of augmented knowledge (unique knowledge edited, rotated, stretched, and so on), forcing the mannequin to study the variation of a picture, furthermore, this can be a brute-force method.
- Half-Entire Drawback: The substitute neuron community (ANN) excels at recognizing patterns inside photos. Nonetheless, they wrestle to characterize relationships between totally different components of an object (how totally different options mix to kind an object). Pooling operations discard spatial data, making it tough for CNNs to know how, for instance, a leg connects to a torso in a picture of a canine.
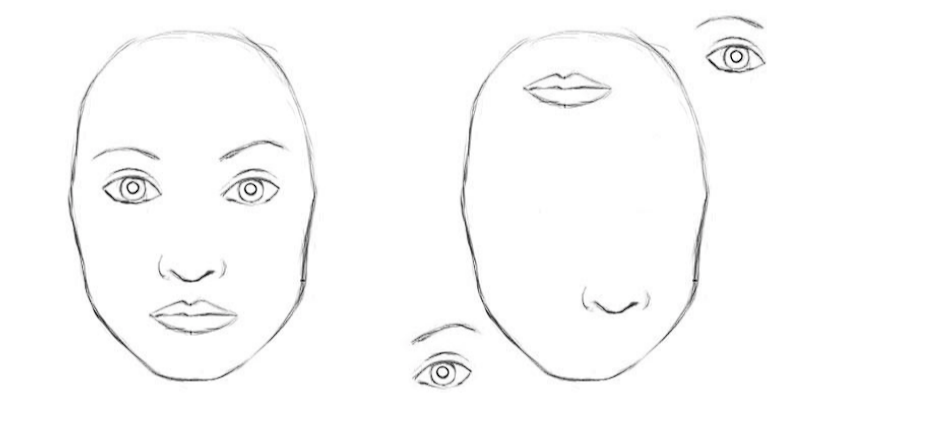
Examples The place CNNs Wrestle
CNNs miss the larger image when components are hidden, twisted, or from surprising angles. Listed below are just a few examples that will possible trigger CNNs to wrestle.
- Hidden Elements: A fence hiding a canine’s physique confuses CNNs.
- New Viewpoints: A CNN skilled on upright cats may miss a lying-down cat as a result of it will possibly’t deal with the brand new pose.
- Deformations: If trainers prepare a CNN on faces with impartial expressions, it’ll wrestle with faces displaying sturdy expressions (large smiles, furrowed brows) as a result of the CNN lacks understanding of the spatial relation between facial options when altered.
What are Capsule Networks?
A Capsule Community is only a Neural Community that improves the design of CNNs by the next key modifications:
- Capsules
- Dynamic Routing, routing by settlement, and Coupling Coefficients
- Squashing Perform
- Margin Loss Perform
Whereas CNNs obtain translational invariance (recognizing an object no matter place), Capsule Networks goal for equivariance. Equivariance considers the spatial relationship of options inside an object, just like the place of a watch on a face.
What’s a Capsule?
On the core of Capsule Networks is the idea of a capsule, which is solely a group of neurons. This set of neurons, known as a capsule output a vector.
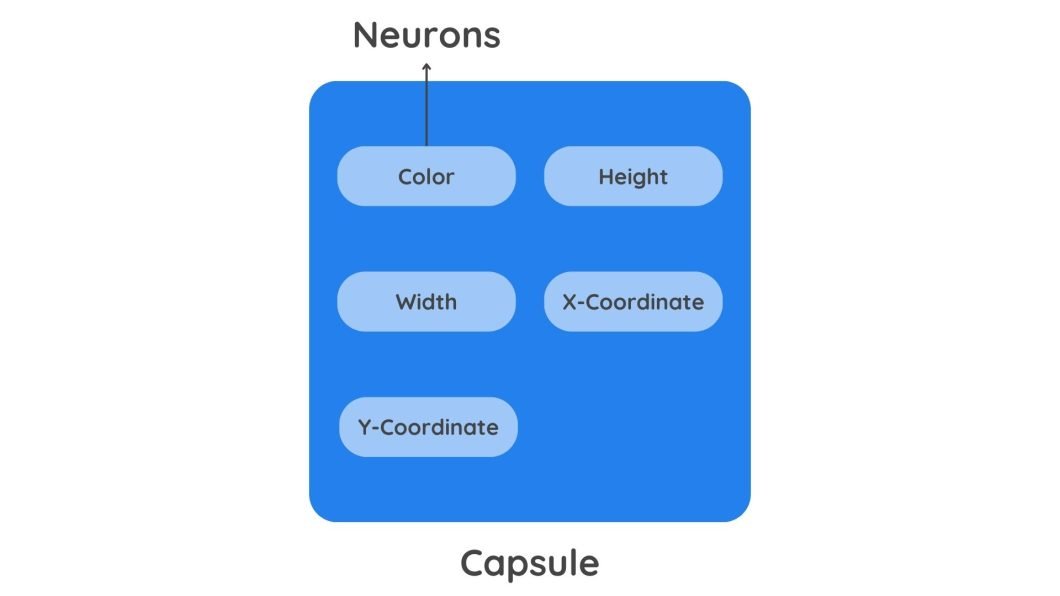
In conventional neural networks like CNNs, neurons are scalar output items (weighted sum) that characterize the presence of a characteristic via its activation values. Nonetheless, a capsule outputs a vector with detailed data. This additional data helps Capsule Community perceive the pose (place and orientation) of an object’s components, together with their presence.
Right here is the extra data the output vector of the capsule holds:
- Pose Info: A capsule outputs a vector that incorporates extra data corresponding to place and orientation. This data is coded within the angle of the vector. A slight change within the object’s options will lead to a distinct angle worth.
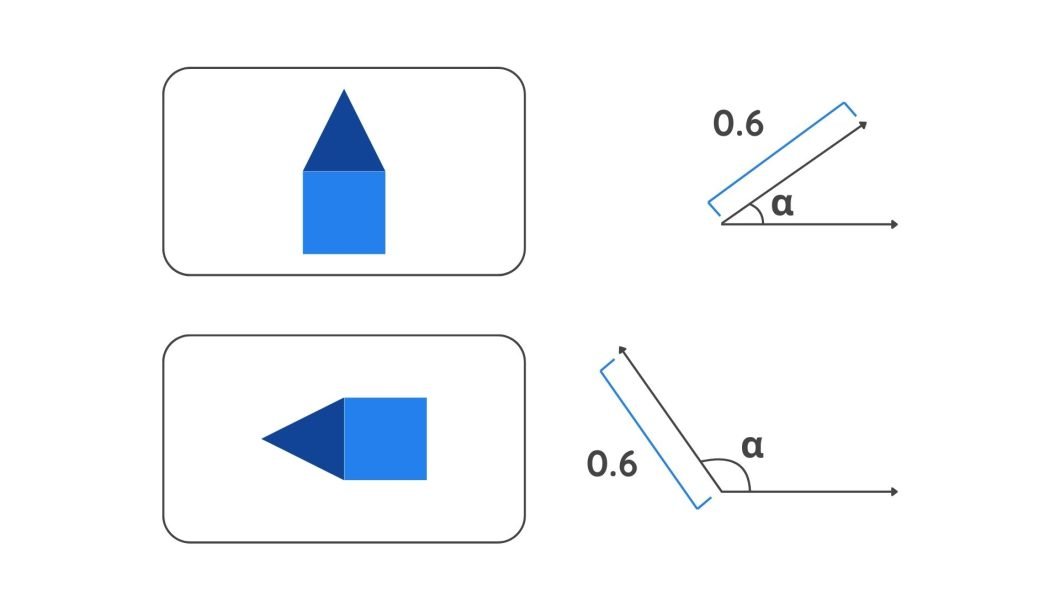
Diagram depicting vectors - Energy: The likelihood of a characteristic’s presence is indicated by the size of the Vector. An extended vector size means a better likelihood.
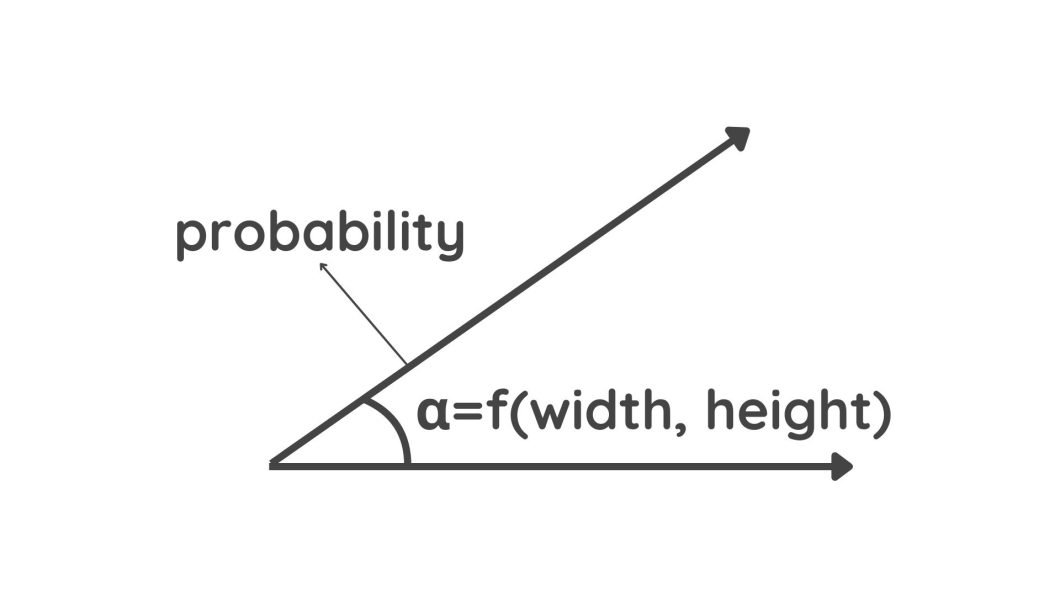
Capsule output vectors
What’s Dynamic Routing?
Convolutional Neural Networks (CNNs) primarily concentrate on simply the person options inside a picture. In distinction, Capsule Networks perceive the connection between particular person components of an object and the complete object. It is aware of how components of an object mix to kind the precise object, additionally known as (the part-whole relationship). That is potential as a result of dynamic routing course of.
The dynamic routing course of ensures that lower-level capsules (representing components of objects) ship their output vectors to essentially the most applicable higher-level capsule (representing the entire object). This enables the community to study spatial hierarchies in flip.

What’s a Coupling Coefficient
Coupling coefficients (cij) are scalar values that decide the power of the connection between a lower-level capsule and a higher-level capsule.
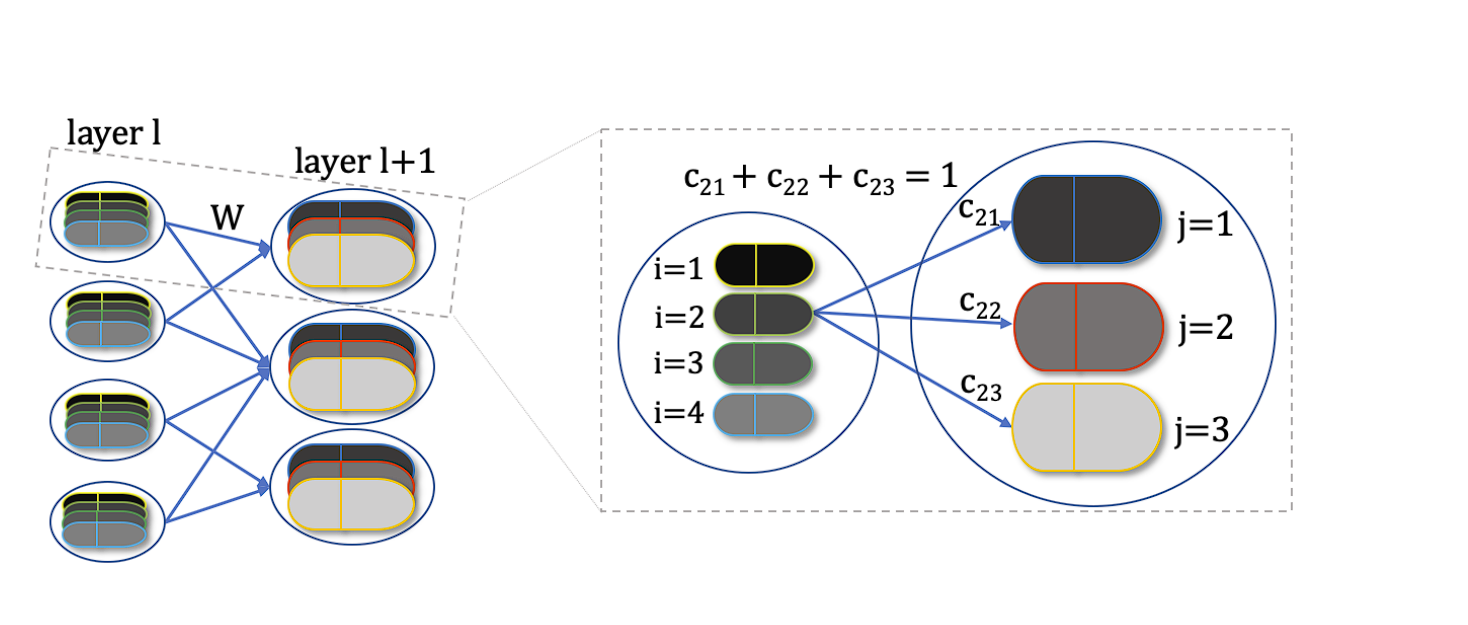
They play a vital function within the dynamic routing course of by guiding the quantity of output from the lower-level capsules despatched to every higher-level capsule. Dynamic routing algorithm updates cij not directly by the scalar product of votes and outputs of potential dad and mom.
What’s the Squashing Perform?
The squashing operate is a non-linear operate that squashes a vector between 0 and 1. Quick vectors get shrunk to nearly zero size and lengthy vectors get shrunk to a size barely under 1. This enables the size of the vector to behave as a likelihood or confidence measure of the characteristic’s presence, with out dropping the vector’s route.
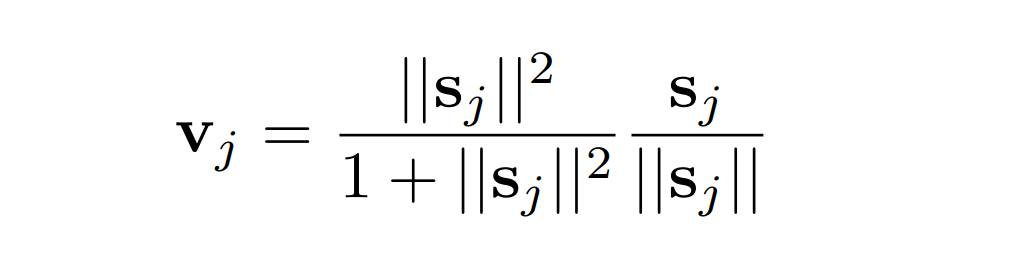
What’s the Margin Loss Perform?
In Capsule Community, to accommodate vector outputs, a brand new loss operate is launched: margin loss operate.
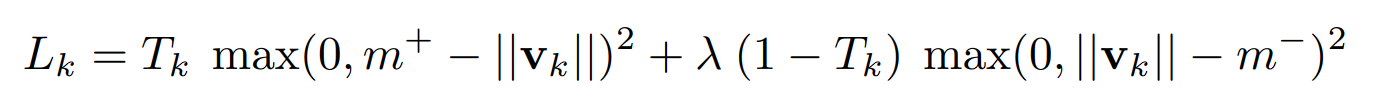
- Lk: The loss for capsule okay, which corresponds to a particular digit class (e.g., the digit “2”).
- Tk: A binary indicator that’s 1 if the digit class okay is current within the picture, and 0 if it isn’t. This enables the community to tell apart between digits which can be current and people that aren’t.
- ∣∣vk∣∣: The magnitude (or size) of the output vector of capsule okay. This size represents the community’s confidence that the digit class okay is current within the enter.
- λ: A weighting issue (set to 0.5) is used to down-weight the loss for digit lessons that aren’t current. This prevents the community from focusing an excessive amount of on minimizing the presence of absent digit lessons, particularly early in coaching.
The full loss for an enter is the sum of the Marginal Losses (Lk) throughout all digit capsules. This method permits the community to study to appropriately alter the lengths of the instantiation vectors for every capsule, corresponding to every potential digit class.
Coaching A Capsule Community
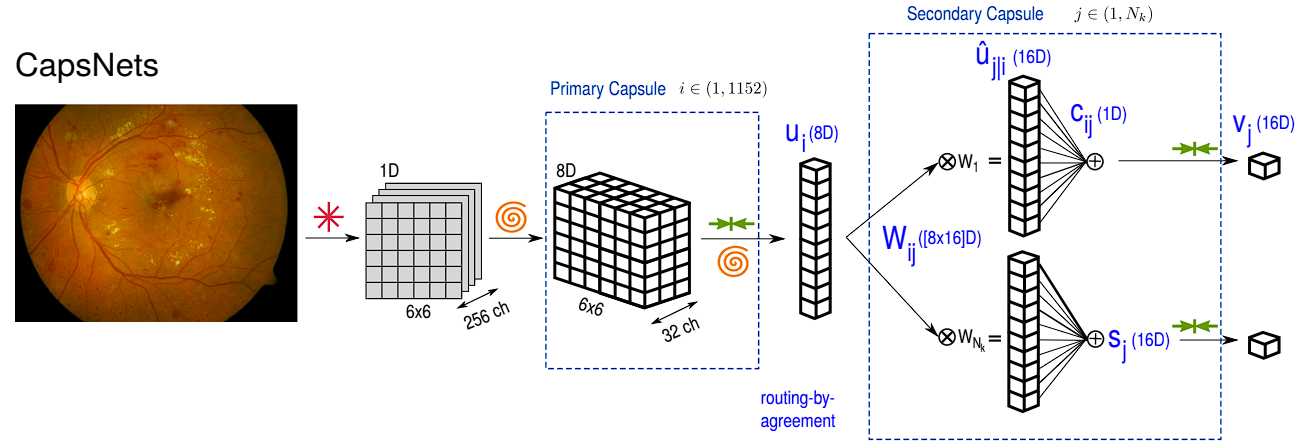
Ahead Move
- Preprocessing and Preliminary Characteristic Extraction: The primary layer of the Capsule Community is a convolution layer that extracts options like edges and texture and passes ahead to the capsule layer.
- Major Capsule Layer: That is the primary capsule layer. Right here, native options detected by the convolutional layers are reworked into vectors by the capsules. Every capsule on this layer goals to seize particular options or components of an object, with the vector’s route representing the pose or orientation and the size of the vector indicating the likelihood of the characteristic’s presence.
- Squashing Perform: The squashing operate preserves the route of the vector, however shrinks the vector between 1 and 0, indicating the likelihood of a characteristic’s presence.
- Dynamic Routing: The dynamic routing algorithm decides which higher-level capsule receives outputs from preliminary capsules.
- Digit Capsules: The capsule community’s last layer, often called the digit capsule, makes use of the output vector’s size to point the digit current within the picture.
Backpropagation
- Margin-based Loss Capabilities: This operate penalizes the community when the settlement between a capsule and its most probably dad or mum (primarily based on pose) isn’t considerably greater than the settlement with different potential dad and mom. This not directly encourages the routing course of to favor capsules with stronger pose settlement.
- Weight Updates: Utilizing the calculated loss and gradients, the weights of the neurons within the capsules are up to date.
For a number of epochs over the coaching dataset, the method repeats the ahead cross and backpropagation steps, refining the community’s parameters every time to reduce the loss.
Capsule Community Structure
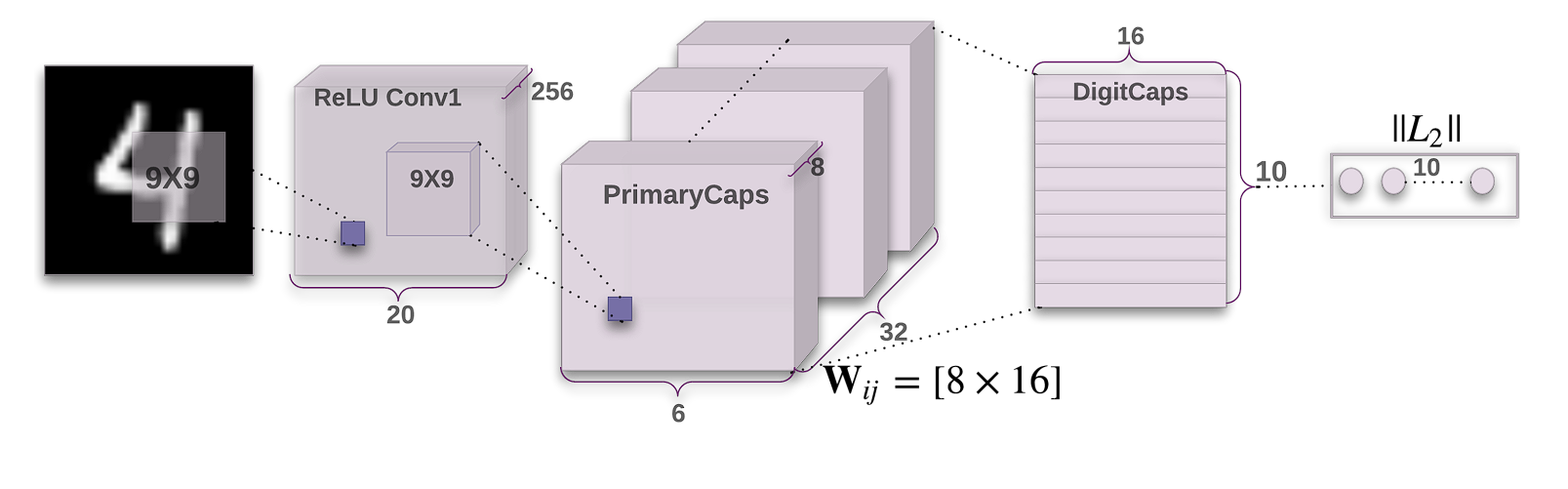
Not like deep convolutional networks, the unique structure of the Capsule Community proposed has a comparatively easy construction comprising 3 layers solely.
- Conv1: This can be a normal convolutional layer with:
- 256 filters (kernels)
- Kernel measurement: 9×9
- Stride: 1
- Activation operate: ReLU
- Objective: Extract low-level options from the enter picture.
- PrimaryCapsules: This can be a convolutional capsule layer with:
- 32 channels
- Every capsule incorporates 8 convolutional items with a 9×9 kernel and stride 2. (So every capsule output is an 8-dimensional vector)
- Every capsule “sees” outputs from all Conv1 items whose receptive fields overlap with its location.
- Objective: Processes the options from Conv1 and teams them into potential entities (like components of digits).
- DigitCaps: That is the ultimate layer with:
- 10 capsules (one for every digit class)
- Every capsule is 16-dimensional.
- Routing: Every capsule in PrimaryCapsules sends its output to all capsules in DigitCaps. A dynamic routing algorithm determines how a lot every PrimaryCapsule contributes to every DigitCapsule.
- Objective: Represents the presence and pose (particular traits) of every digit class within the picture.
A Math intensive Rationalization of Capsule Networks
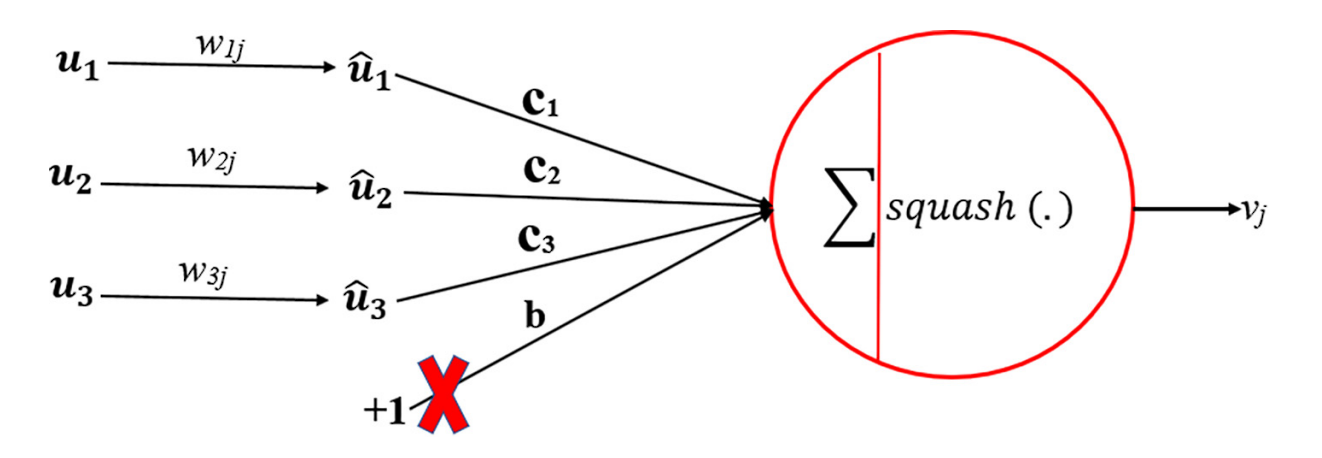
- Vector Transformation and Prediction Vector (uj|i): Every lower-level capsule (i.e. capsule i at layer l) produces an output vector ui. This output vector is then multiplied by a weight matrix (Wij) to provide a prediction vector (uj|i). This vector is actually the capsule i’s prediction of the output of capsule j on the subsequent greater layer (l+1). This course of is represented by the equation uj|i = Wijui
- Coupling Coefeccient (cij) and Settlement: The coupling coefficient (cij) represents the decrease diploma of settlement between lower-level capsule i and higher-level capsule j. If a lower-level capsule’s prediction agrees with the higher-level capsule’s precise output, their coupling coefficient is elevated, strengthing their connection. Conversely, if there’s disagreement, the coupling coefficient is lowered. The coefficients are then up to date iteratively via the routing mechanism.
- Weighted Sum (sj) and squashing operate (vj): The full enter to a better stage capsule (j) is a weighted sum of all prediction vectors ( uj|i) from the capsules within the under layer, weighted by their respective coupling coefficients ( cij). That is represented by the equation sj = Σi=1 to N cijuj|i the vector sj is then handed via the squashing operate to provide the output vector vj of capsule j. This squashing operate ensures that the size of the output vector i is between o and 1, which permits the community to seize possibilities.
Challenges and Limitations
- Computational Complexity: Dynamic routing, the core mechanism for part-whole understanding in Capsule Networks, is computationally costly. The iterative routing course of and settlement calculations require extra assets in comparison with CNNs. This results in slower coaching and elevated {hardware} demand.
- Restricted Scalability: CapsNets haven’t been as extensively examined on very giant datasets as CNNs. Their computational complexity may change into a major hurdle for scaling to large datasets sooner or later.
- Early Stage of Analysis and Neighborhood Help: CapsNets are comparatively new in comparison with CNNs. This additionally results in fewer implementations and fewer neighborhood assist. This could make implementing Capsule Networks tough.
Purposes of Capsule Networks
- Astronomy and Autonomous Automobiles: CapsNets are being explored for classifying celestial objects and enhancing the notion methods in self-driving vehicles.
- Machine Translation, Handwritten, and Textual content Recognition: They present promise in pure language processing duties and recognizing handwritten texts, which may enhance communication and automation in knowledge processing.
- Object Detection and Segmentation: In advanced scenes the place a number of objects work together or overlap, CapsNets might be significantly helpful. Their means to keep up details about spatial hierarchies permits more practical segmentation of particular person objects and detection of their boundaries, even in crowded or cluttered photos.
- 3D Object Reconstruction: Capsule Networks have potential functions in 3D object reconstruction from 2D photos, on account of their means to deduce spatial relationships and object poses, which contribute to extra correct reconstruction of 3D fashions from restricted viewpoints.
- Augmented Actuality (AR): Capsule Networks have the potential to revolutionize AR by enhancing object recognition, spatial reasoning, and interplay in augmented environments, resulting in extra immersive and life like AR experiences.