

Introduction to Spatio-Temporal Motion Recognition Fundamentals
Many use the phrases Spatio-Temporal Motion Recognition, localization, and detection interchangeably. Nevertheless, there’s a refined distinction in precisely what they concentrate on.
Spatio-temporal motion recognition identifies each the kind of motion that happens and when it occurs. Localization contains the popularity in addition to pinpointing its spatial location inside every body over time. Detection focuses on when an motion begins and ends and the way lengthy it lasts in a video.
Let’s take an instance of a video clip that includes a working man. Recognition entails figuring out that “working” is going down and whether or not it happens for the entire clip or not. Localization might contain including a bounding field over the working particular person in every video body. Detection would go a step additional by offering the precise timestamps of when the motion of working happens.
Nevertheless, the overlap is critical sufficient that these three operations require nearly the identical conceptual and technological framework. Subsequently, for this text, we’ll often confer with them as basically the identical.

There’s a broad spectrum of purposes throughout numerous industries with these capabilities. For instance, surveillance, visitors monitoring, healthcare, and even sports activities or efficiency evaluation.
Nevertheless, utilizing spatio-temporal motion recognition successfully requires fixing challenges relating to computational effectivity and accuracy below less-than-ideal circumstances. For instance, a video clip with poor lighting, advanced backgrounds, or occlusions.
About us: Viso Suite permits machine studying groups to take management of all the venture lifecycle. By eliminating the necessity to buy and handle level options, Viso Suite presents groups with a very end-to-end laptop imaginative and prescient infrastructure. To study extra, get a personalised demo from the Viso group.
Coaching Spatio-Temporal Motion Recognition Techniques
There are limitless doable mixtures of environments, actions, and codecs for video content material. Contemplating this, any motion recognition system should be able to a excessive diploma of generalization. And on the subject of applied sciences primarily based on deep studying, meaning huge and different information units to coach on.
Luckily, there are numerous established databases from which we will select. Google’s DeepMind researchers developed the Kinetics library, leveraging its YouTube platform. The most recent model is Kinetics 700-2020, which accommodates over 700 human motion lessons from as much as 650,000 video clips.
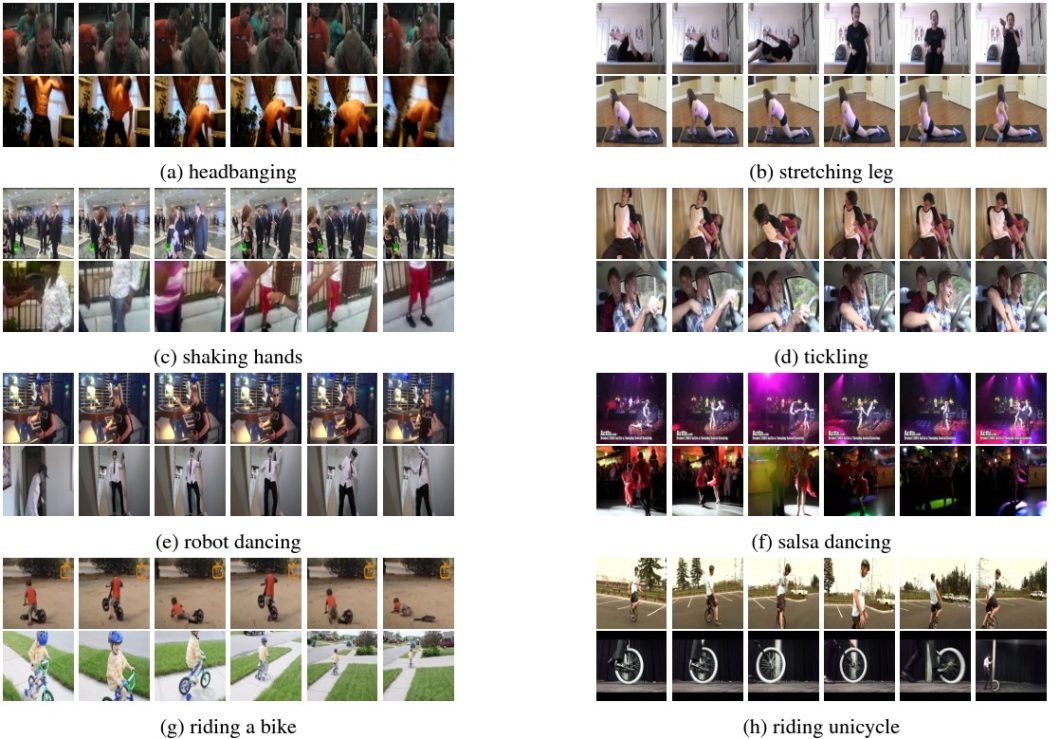
The Atomic Visible Actions (AVA) dataset is one other useful resource developed by Google. Nevertheless, it additionally gives annotations for each spatial and temporal areas of actions inside its video clips. Thus, it permits for a extra detailed examine of human habits by offering exact frames with labeled actions.
Just lately, Google mixed its Kinetics and AVA Datasets into the AVA-Kinetics dataset. It combines each the AVA and Kinetics 700-202 datasets, with all data annotated utilizing the AVA methodology. With only a few exceptions, AVA-Kinetics outperforms each particular person fashions in coaching accuracy.
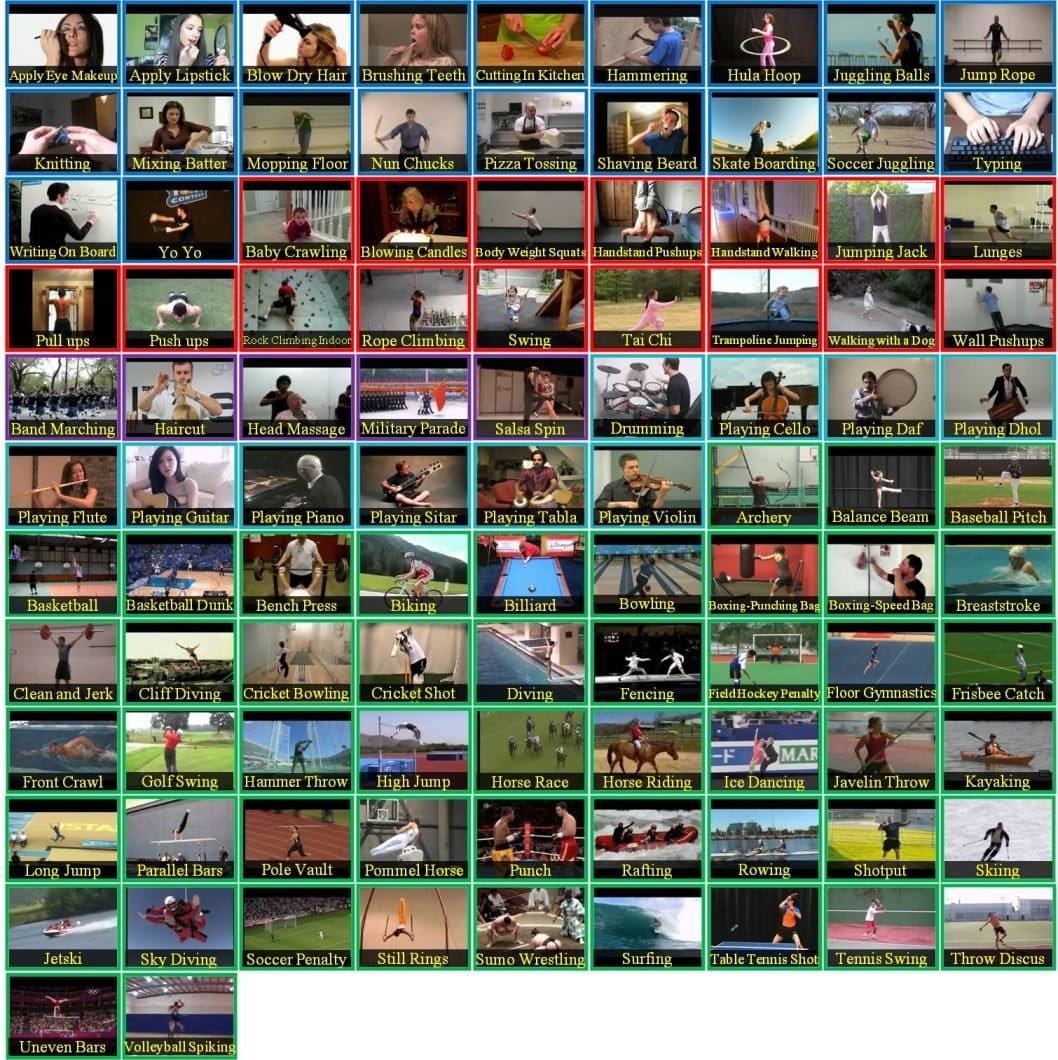
One other complete supply is UCF101, curated by the College of Central Florida. This dataset consists of 13320 movies with 101 motion classes, grouped into 25 teams and divided into 5 varieties. The 5 varieties are Human-Object Interplay, Physique-Movement Solely, Human-Human Interplay, Taking part in Musical Devices, and Sports activities.
The motion classes are numerous and particular, starting from “apply eye make-up” to “billiards shot” to “boxing pace bag”.
Labeling the actions in movies is just not one-dimensional, making it considerably difficult. Even the best purposes require multi-frame annotations or these of each motion class and temporal information.
Guide human annotation is extremely correct however too time-consuming and labor-intensive. Computerized annotation utilizing AI and laptop imaginative and prescient applied sciences is extra environment friendly however requires computational sources, coaching datasets, and preliminary supervision.
There are present instruments for this, corresponding to CVAT (Pc Imaginative and prescient Annotation Device) and VATIC (Video Annotation Device from Irvine, California). They provide semi-automated annotation, producing preliminary labels utilizing pre-trained fashions that people then refine.
Energetic studying is one other strategy the place fashions are iteratively skilled on small subsets of information. These fashions then predict annotations on unlabeled information. Nevertheless, as soon as once more, they might require approval from a human annotator to make sure accuracy.
How Spatio-Temporal Motion Recognition Integrates With Deep Studying
As is commonly the case in laptop imaginative and prescient, deep studying frameworks are driving essential developments within the discipline. Particularly, researchers are working with the next deep studying fashions to reinforce spatio-temporal motion recognition techniques:
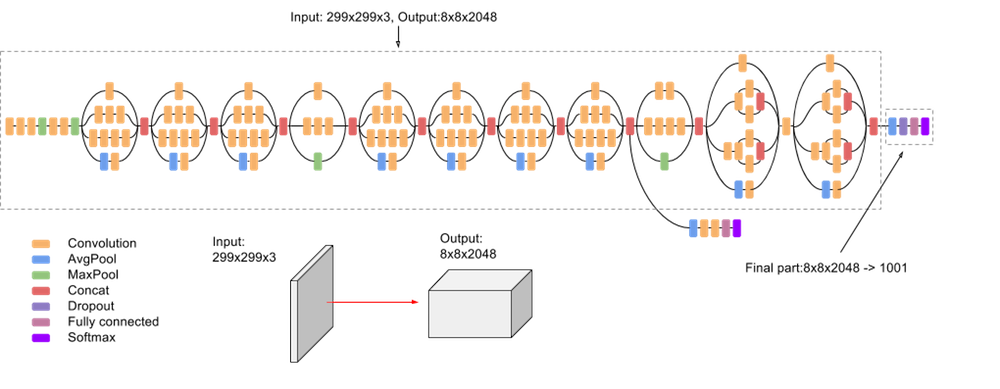
Spatio-Temporal Motion Recognition – Mannequin Architectures and Algorithms
On account of technological limitations, preliminary analysis targeted individually on spatial and temporal options.
The predecessors of spatial-temporal techniques immediately had been made for stationary visuals. One significantly difficult discipline was that of figuring out hand-written options. For instance, Histograms of Oriented Gradients (HOG) and Histograms of Optical Move (HOF).
By integrating these with assist vector machines (SVMs), researchers might develop extra subtle capabilities.
3D CNNs result in some important developments within the discipline. By utilizing them, these techniques had been capable of deal with video clips as volumes, permitting fashions to study spatial and temporal options on the similar time.
Over time, extra work has been carried out to combine spatial and temporal options extra seamlessly. Researchers and builders are making progress by deploying applied sciences, corresponding to:
- I3D (Inflated 3D CNN): One other DeepMind initiative, I3D is an extension of 2D CNN architectures used for picture recognition duties. Inflating filters and pooling kernels into 3D house permits for capturing each visible and motion-related info.
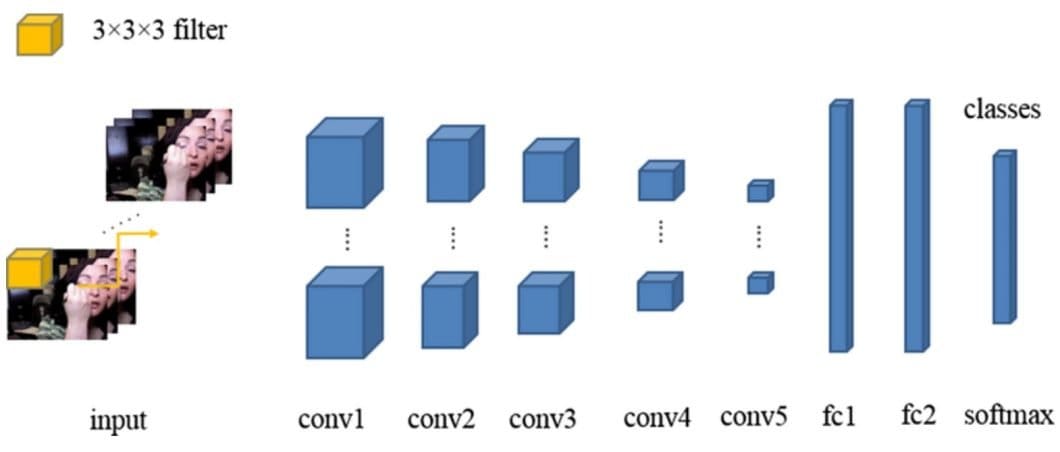
- Area-based CNNs (R-CNNs): This strategy makes use of the idea of Regional Proposal Networks (RPNs) to seize actions inside video frames extra effectively.
- Temporal Phase Networks (TSNs): TSNs divide a video into equal segments and extract a snippet from every of them. CNNs then extract options from every snippet and common out the actions in them to create a cohesive illustration. This permits the mannequin to seize temporal dynamics whereas being environment friendly sufficient for real-time purposes.
The relative efficiency and effectivity of those totally different approaches rely on the dataset you prepare them on. Many take into account I3D to be one of the vital correct strategies, though it requires pre-training on giant datasets. R-CNNs are additionally extremely correct however require important computational sources, making them unsuited for real-time purposes.
However, TSNs provide a stable stability between efficiency and computational effectivity. Nevertheless, making an attempt to cowl all the video can result in a loss in fine-grained temporal element.
Tips on how to Measure the Efficiency of Spatio-Temporal Motion Recognition Techniques
After all, researchers will need to have frequent mechanisms to measure the general progress of spatial-temporal motion recognition techniques. With this in thoughts, there are a number of generally used metrics used to evaluate the efficiency of those techniques:
- Accuracy: How nicely can a system appropriately label all motion lessons in a video?
- Precision: What’s the ratio of appropriate positives to false positives for a particular motion class?
- Recall: What number of actions the system can detect in a single video?
- F1 rating: A metric that’s a perform of each a system’s precision and recall.
The F1 rating is used to calculate what’s known as the “harmonic imply” of the mannequin’s precision and recall. Merely put, which means that the mannequin wants a excessive rating for each metrics to get a excessive total F1 rating. The formulation for the F1 rating is easy:
F1 = 2 (precision x recall / precision + recall)
An F1 rating of 1 is taken into account “good.” In essence, it produces the common precision throughout all detected motion lessons.
The ActivityNet Problem is likely one of the standard competitions for researchers to check their fashions and benchmark new proposals. Datasets like Google’s Kinetic and AVA additionally present standardized environments to coach and consider fashions. By together with annotations, the AVA-Kinetics dataset helps to enhance efficiency throughout the sphere.
Successive releases (e.g., Kinetics-400, Kinetics-600, Kinetics-700) have enabled a continued effort to push the boundaries of accuracy.
To study extra about matters associated to Pc Imaginative and prescient and Deep Studying Algorithms, learn the next blogs: