
Contrastive Language-Picture Pre-training (CLIP) is a multimodal studying structure developed by OpenAI. It learns visible ideas from pure language supervision. It bridges the hole between textual content and visible information by collectively coaching a mannequin on a large-scale dataset containing photos and their corresponding textual descriptions. That is much like the zero-shot capabilities of GPT-2 and GPT-3.
This text will present insights into how CLIP bridges the hole between pure language and picture processing. Specifically, you’ll study:
- How does CLIP work?
- Structure and coaching course of
- How CLIP resolves key challenges in pc imaginative and prescient
- Sensible purposes
- Challenges and limitations whereas implementing CLIP
- Future developments
How Does CLIP Work?
CLIP (Contrastive Language–Picture Pre-training) is a mannequin developed by OpenAI that learns visible ideas from pure language descriptions. Its effectiveness comes from a large-scale, numerous dataset of photos and texts.
What’s distinction studying?
Contrastive studying is a way utilized in machine studying, significantly within the discipline of unsupervised studying. Contrastive studying is a technique the place we train an AI mannequin to acknowledge similarities and variations of numerous information factors.
Think about you’ve a foremost merchandise (the “anchor pattern”), an identical merchandise (“constructive”), and a special merchandise (“unfavorable pattern”). The purpose is to make the mannequin perceive that the anchor and the constructive merchandise are alike, so it brings them nearer collectively in its thoughts, whereas recognizing that the unfavorable merchandise is totally different and pushing it away.
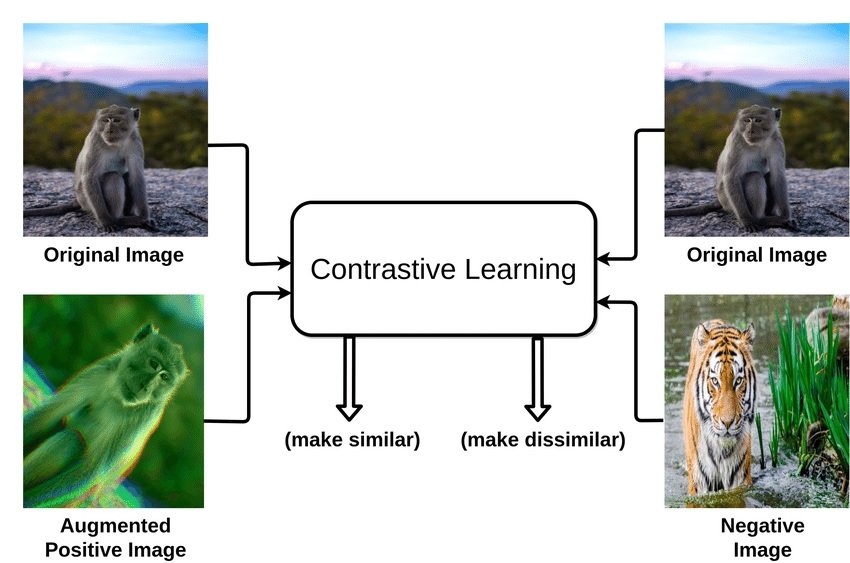
What’s an instance of distinction studying?
In a pc imaginative and prescient instance of distinction studying, we purpose to coach a software like a convolutional neural community to convey related picture representations nearer and separate the dissimilar ones.
The same or “constructive” picture or is likely to be from the identical class (e.g., canines) as the principle picture or a modified model of it, whereas a “unfavorable” picture could be totally totally different, usually from one other class (e.g., cats).
CLIP Structure defined
Contrastive Language-Picture Pre-training (CLIP) makes use of a dual-encoder structure to map photos and textual content right into a shared latent area. It really works by collectively coaching two encoders. One encoder for photos (Imaginative and prescient Transformer) and one for textual content (Transformer-based language mannequin).
- Picture Encoder: The picture encoder extracts salient options from the visible enter. This encoder takes an ‘picture as enter’ and produces a high-dimensional vector illustration. It usually makes use of a convolutional neural community (CNN) structure, like ResNet, for extracting picture options.
- Textual content Encoder: The textual content encoder encodes the semantic which means of the corresponding textual description. It takes a ‘textual content caption/label as enter’ and produces one other high-dimensional vector illustration. It typically makes use of a transformer-based structure, like a Transformer or BERT, to course of textual content sequences.
- Shared Embedding House: The 2 encoders produce embeddings in a shared vector area. These shared embedding areas permit CLIP to match textual content and picture representations and study their underlying relationships.
CLIP Coaching Course of
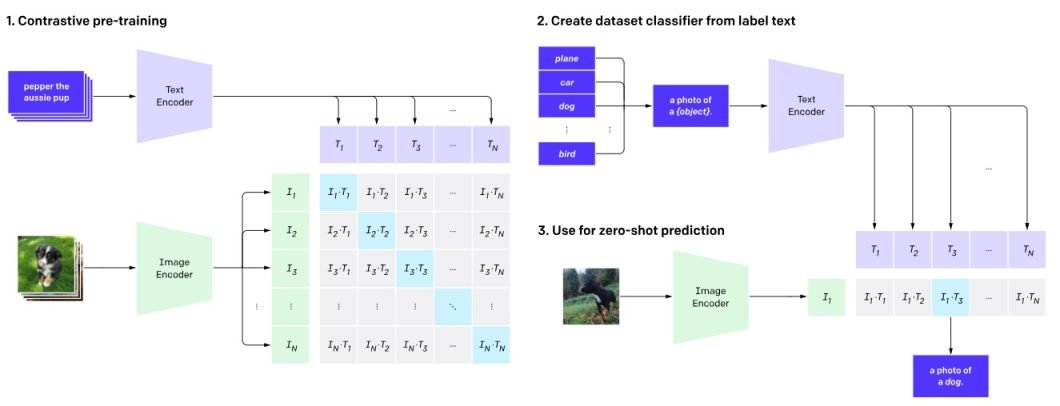
Step 1: Contrastive Pre-training
CLIP is pre-trained on a large-scale dataset of 400 million (picture, textual content information) pairs collected from the web. Throughout pre-training, the mannequin is offered with pairs of photos and textual content captions. A few of these pairs are real matches (the caption precisely describes the picture), whereas others are mismatched. It creates shared latent area embeddings.
Step 2: Create Dataset Classifiers from Label Textual content
For every picture, a number of textual content descriptions are created, together with the proper one and several other incorrect ones. This creates a mixture of constructive samples (matching) and unfavorable pattern (mismatched) pairs. These descriptions are fed into the textual content encoder, producing class-specific embeddings.
At this stage, one essential perform additionally got here into play: Contrastive Loss Operate. This perform penalizes the mannequin for incorrectly matching (image-text) pairs. However, rewards it for accurately matching (image-text) pairs within the latent area. It encourages the mannequin to study representations that precisely seize visible and textual info similarities.
Step 3: Zero-shot Prediction
Now, the skilled textual content encoder is used as a zero-shot classifier. With a brand new picture, CLIP could make zero-shot predictions. That is performed by passing it by the picture encoder and the dataset classifier with out fine-tuning.
CLIP computes the cosine similarity between the embeddings of all picture and textual content description pairs. It optimizes the parameters of the encoders to extend the similarity of the proper pairs. Thus, lowering the similarity of the wrong pairs.
This fashion, CLIP learns a multimodal embedding area the place semantically associated photos and texts are mapped shut to one another. The anticipated class is the one with the best logit worth.
Integration Between Pure Language and Picture Processing
CLIP’s skill to map photos and textual content right into a shared area permits for the mixing of NLP and picture processing duties. This enables CLIP to:
- Generate textual content descriptions for photos. It may possibly retrieve related textual content descriptions from the coaching information by querying the latent area with a picture illustration. In flip, successfully performing picture captioning.
- Classify photos based mostly on textual descriptions. It may possibly straight examine textual descriptions with the representations of unseen photos within the latent area. Consequently, zero-shot picture classification is carried out with out requiring labeled coaching information for particular lessons.
- Edit photos based mostly on textual prompts. Textual directions can be utilized to switch current photos. Customers can manipulate the textual enter and feed it again into CLIP. This guides the mannequin to generate or modify photos following the required textual prompts. This functionality lays a basis for progressive text-to-image technology and modifying instruments.
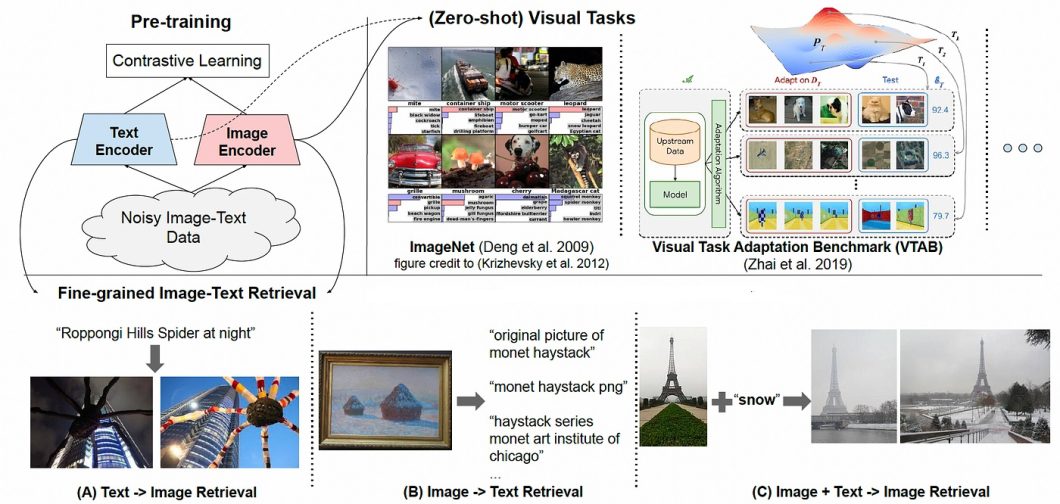
Main Issues in Laptop Imaginative and prescient and How CLIP Helps
Semantic Gaps
One of many largest hurdles in pc imaginative and prescient is the “semantic hole.” The semantic hole is the disconnect between the low-level visible options that computer systems extract from photos and the high-level semantic ideas that people readily perceive.

Conventional imaginative and prescient fashions excel at duties like object detection and picture classification. Nonetheless, they typically battle to understand the deeper which means and context inside a picture. This makes it troublesome for them to purpose about relationships between objects, interpret actions, or infer intentions.
Then again, CLIP can perceive the relationships between objects, actions, and feelings depicted in photos. Given a picture of a kid taking part in in a park, CLIP can determine the presence of the kid and the park. Additional, it could actually additionally infer that the kid is having enjoyable.
Knowledge Efficiencies
One other essential problem is the sheer quantity of information required to coach pc imaginative and prescient fashions successfully. Deep studying algorithms demand huge labeled picture datasets to study advanced relationships between visible options and semantic ideas. Buying and annotating such massive datasets is dear and time-consuming, limiting the usability and scalability of imaginative and prescient fashions.
In the meantime, CLIP can study from fewer image-text pairs than conventional imaginative and prescient fashions. This makes it extra resource-efficient and adaptable to specialised domains with restricted information.
Lack of Explainability and Generalizability
Conventional pc imaginative and prescient fashions typically battle with explaining their reasoning behind predictions. This “black field” nature hinders belief and limits its utility in numerous situations.
Nonetheless, CLIP, skilled on huge image-text pairs, learns to affiliate visible options with textual descriptions. This enables for producing captions that specify the mannequin’s reasoning, enhancing interpretability and boosting belief. Moreover, CLIP’s skill to adapt to varied textual content prompts enhances its generalizability to unseen conditions.
Sensible Purposes of CLIP
Contrastive Language-Picture Pre-training is beneficial for numerous sensible purposes, similar to:
Zero-Shot Picture Classification
One of the spectacular options of CLIP is its skill to carry out zero-shot picture classification. Which means that CLIP can classify photos it has by no means seen earlier than, utilizing solely pure language descriptions.
For conventional picture classification duties, AI fashions are skilled on particularly labeled datasets, limiting their skill to acknowledge objects or scenes exterior their coaching scope. With CLIP, you’ll be able to present pure language descriptions to the mannequin. In flip, this allows it to generalize and classify photos based mostly on textual enter with out particular coaching in these classes.
Multimodal Studying
One other utility of CLIP is its use as a part of multimodal studying programs. These can mix several types of information, similar to textual content and pictures.
As an example, it may be paired with a generative mannequin similar to DALL-E. Right here, it should create photos from textual content inputs to provide lifelike and numerous outcomes. Conversely, it could actually edit current photos based mostly on textual content instructions, similar to altering an object’s coloration, form, or type. This allows customers to create and manipulate photos creatively with out requiring inventive expertise or instruments.

Picture Captioning
CLIP’s skill to grasp the connection between photos and textual content makes it appropriate for pc imaginative and prescient duties like picture captioning. Given a picture, it could actually generate captions that describe the content material and context.
This performance might be helpful in purposes the place a human-like understanding of photos is required. This will embrace assistive applied sciences for the visually impaired or enhancing content material for search engines like google. For instance, it may present detailed descriptions for visually impaired customers or contribute to extra exact search outcomes.
Semantic Picture Search and Retrieval
CLIP might be employed for semantic picture search and retrieval past easy keyword-based searches. Customers can enter pure language queries, and the CLIP AI mannequin will retrieve photos that greatest match the textual descriptions.
This method improves the precision and relevance of search outcomes. Thus, making it a invaluable software in content material administration programs, digital asset administration, and any use case requiring environment friendly and correct picture retrieval.
Knowledge Content material Moderation
Content material moderation filters inappropriate or dangerous content material from on-line platforms, similar to photos containing violence, nudity, or hate speech. CLIP can help within the content material moderation course of by detecting and flagging such content material based mostly on pure language standards.
For instance, it could actually determine photos that violate a platform’s phrases of service or group pointers or which can be offensive or delicate to sure teams or people. Moreover, it could actually justify selections by highlighting related elements of the picture or textual content that triggered the moderation.
Deciphering Blurred Photographs
In situations with compromised picture high quality, similar to in surveillance footage or medical imaging, CLIP can present invaluable insights by decoding the obtainable visible info along side related textual descriptions. It may possibly present hints or clues about what the unique picture may seem like based mostly on its semantic content material and context. Nonetheless, it could actually generate partial or full photos from blurred inputs utilizing its generative capabilities or retrieving related photos from a big database.
CLIP Limitations and Challenges
Regardless of its spectacular efficiency and potential purposes, CLIP additionally has some limitations, similar to:
Lack of Interpretability
One other disadvantage is the shortage of interpretability in CLIP’s decision-making course of. Understanding why the mannequin classifies a particular picture in a sure approach might be difficult. This may hinder its utility in delicate areas the place interpretability is essential, similar to healthcare diagnostics or authorized contexts.
Lack of Advantageous-Grained Understanding
CLIP’s understanding can be restricted when it comes to fine-grained particulars. Whereas it excels at high-level duties, it might battle with intricate nuances and refined distinctions inside photos or texts. Thus, limiting its effectiveness in purposes requiring granular evaluation.
Restricted Understanding of Relationships (Feelings, Summary Ideas, and so forth.)
CLIP’s comprehension of relationships, particularly feelings and summary ideas, stays constrained. It would misread advanced or nuanced visible cues. In flip, impacting its efficiency in duties requiring a deeper understanding of human experiences.

Biases in Pretraining Knowledge
Biases current within the pretraining information can switch to CLIP, doubtlessly perpetuating and amplifying societal biases. This raises moral issues, significantly in AI purposes like content material moderation or decision-making programs. In these use instances, biased outcomes result in real-world penalties.
CLIP Developments and Future Instructions
As CLIP continues to reshape the panorama of multimodal studying, its integration into real-world purposes is promising. Knowledge scientists are exploring methods to beat its limitations, with a watch on creating much more superior and interpretable fashions.
CLIP guarantees breakthroughs in areas like picture recognition, NLP, medical diagnostics, assistive applied sciences, superior robotics, and extra. It paves the best way for extra intuitive human-AI interactions as machines grasp contextual understanding throughout totally different modalities.
The flexibility of CLIP is shaping a future the place AI comprehends the world as people do. Future analysis will form AI capabilities, unlock novel purposes, drive innovation, and broaden the horizons of prospects in machine studying and deep studying programs.
What’s Subsequent for Contrastive Language-Picture Pre-Coaching?
As CLIP continues to evolve, it holds immense potential to alter the best way we work together with info throughout modalities. By bridging language and imaginative and prescient, CLIP promotes a future the place machines can actually “see” and “perceive” the world.
To realize a extra complete understanding, take a look at the next articles: