
Laptop imaginative and prescient has quickly change into an integral part of contemporary expertise, remodeling industries resembling retail, logistics, healthcare, robotics, and autonomous autos. As laptop imaginative and prescient fashions proceed to evolve, it’s essential to guage their efficiency precisely and effectively.
On this weblog article, we’ll focus on practices which might be essential for assessing and enhancing laptop imaginative and prescient fashions:
- Most necessary mannequin efficiency measures
- Mannequin comparability and analysis methods
- Detection and classification metrics
- Dataset benchmarking
About us: Viso.ai supplies the main end-to-end Laptop Imaginative and prescient Platform Viso Suite. The following-gen resolution permits organizations to ship fashions in laptop imaginative and prescient functions. Get a demo to your firm.
Key Efficiency Metrics
To judge a pc imaginative and prescient mannequin, we have to perceive a number of key efficiency metrics. After we introduce the important thing ideas, we’ll present a listing of when to make use of which efficiency measure.
Precision
Precision is a efficiency measure that quantifies the accuracy of a mannequin in making optimistic predictions. It’s outlined because the ratio of true optimistic predictions (appropriately recognized optimistic situations) to the sum of true positives and false positives (situations that have been incorrectly recognized as optimistic).
The system to calculate Precision is:
Precision = True Positives (TP) / (True Positives (TP) + False Positives (FP))
Precision is necessary when the price of false positives is excessive or when the objective is to attenuate false detections. The metric measures the proportion of appropriate optimistic predictions. This helps to guage how properly the mannequin discriminates between related and irrelevant objects in analyzed photos.
In laptop imaginative and prescient duties resembling object detection, picture segmentation, or facial recognition, Precision supplies useful perception into the mannequin’s potential to appropriately establish and localize goal objects or options, whereas minimizing false detections.

Recall
Recall, also referred to as Sensitivity or True Constructive Price, is a key metric in laptop imaginative and prescient mannequin analysis. It’s outlined because the proportion of true optimistic predictions (appropriately recognized optimistic situations) amongst all related situations (the sum of true positives and false negatives, that are optimistic situations that the mannequin didn’t establish).
Due to this fact, the system to calculate Recall is:
Recall = True Positives (TP) / (True Positives (TP) + False Negatives (FN))
The significance of Recall lies in its potential to measure the mannequin’s functionality to detect all optimistic instances, making it a important metric in conditions the place lacking optimistic situations can have important penalties. Recall quantifies the proportion of optimistic situations that the mannequin efficiently recognized. This supplies insights into the mannequin’s effectiveness in capturing the whole set of related objects or options within the analyzed photos.
For instance, within the context of a safety system, Recall represents the proportion of precise intruders detected by the system. A excessive Recall worth is fascinating because it signifies that the system is efficient in figuring out potential safety threats, minimizing the chance of undetected intrusions.

In different laptop imaginative and prescient use instances the place the price of false negatives is excessive, resembling medical imaging for AI analysis or anomaly detection, Recall serves as a vital metric to guage the mannequin’s efficiency.
F1 Rating
The F1 rating is a efficiency metric that mixes Precision and Recall right into a single worth, offering a balanced measure of a pc imaginative and prescient mannequin’s efficiency. It’s outlined because the harmonic imply of Precision and Recall, calculated as follows:
Right here is the system to calculate the F1 Rating:
F1 Rating = 2 * (Precision * Recall) / (Precision + Recall)
The significance of the F1 rating stems from its usefulness in situations with uneven class distributions or when false positives and false negatives carry completely different prices. By contemplating each Precision (the accuracy of optimistic predictions) and Recall (the flexibility to establish all optimistic situations), the F1 rating presents a complete analysis of a mannequin’s efficiency, notably when the stability between false positives and false negatives is essential.
As an example, in a medical imaging system, the F1 rating helps decide the mannequin’s general effectiveness in detecting and diagnosing particular situations. A excessive F1 rating signifies that the mannequin is profitable in precisely figuring out related options whereas minimizing each false positives (e.g., wholesome tissue mistakenly flagged as irregular) and false negatives (e.g., a situation that goes undetected).
In such functions, the F1 rating serves as a useful metric to make sure that the pc imaginative and prescient mannequin performs optimally and minimizes potential dangers related to misdiagnosis or missed analysis.
Accuracy
Accuracy is a basic efficiency metric utilized in laptop imaginative and prescient mannequin analysis. It’s outlined because the proportion of appropriate predictions (each true positives and true negatives) amongst all situations in a given dataset. In different phrases, it measures the proportion of situations that the mannequin has labeled appropriately, contemplating each optimistic and damaging lessons.
That is the system to calculate mannequin accuracy:
Accuracy = (True Positives (TP) + True Negatives (TN)) / (True Positives (TP) + False Positives (FP) + True Negatives (TN) + False Negatives (FN))
The significance of accuracy stems from its potential to offer an easy measure of the mannequin’s general efficiency. It provides a common concept of how properly the mannequin performs on a given job, resembling object detection, picture classification, or segmentation.
Nonetheless, accuracy is probably not appropriate in conditions with important class imbalances, because it can provide a deceptive impression of the mannequin’s efficiency. In such instances, the mannequin may carry out properly on the bulk class however poorly on the minority class, resulting in a excessive accuracy that doesn’t precisely replicate the mannequin’s effectiveness in figuring out all lessons.
For instance, in a picture classification system, accuracy signifies the proportion of photos that the mannequin has labeled appropriately. A excessive accuracy worth means that the mannequin is efficient in assigning the proper labels to pictures throughout all lessons.
You will need to think about different efficiency metrics, resembling Precision, Recall, and F1 rating, to acquire a extra complete understanding of the mannequin’s efficiency. That is particularly the case when coping with imbalanced datasets or situations with various prices for various kinds of errors.

Intersection over Union (IoU)
Intersection over Union (IoU), also referred to as the Jaccard index, is a efficiency metric generally utilized in laptop imaginative and prescient mannequin analysis. It’s notably necessary for object detection and localization duties. IoU is outlined because the ratio of the realm of overlap between the expected bounding field and the bottom reality bounding field to the realm of their union.
In easy phrases, IoU measures the diploma of overlap between the mannequin’s prediction and the precise goal, expressed as a worth between 0 and 1, with 0 indicating no overlap and 1 representing an ideal match.
The system for Intersection over Union (IoU) is:
IoU = Space of Intersection / Space of Union
The significance of IoU lies in its potential to evaluate the localization accuracy of the mannequin, capturing each the detection and positioning features of an object in a picture. By quantifying the diploma of overlap between the expected and floor reality bounding bins, IoU supplies insights into the mannequin’s effectiveness in figuring out and localizing objects with precision.
For instance, in a self-driving automotive’s object detection system, IoU measures how properly the machine studying mannequin can precisely detect and localize different autos, pedestrians, and obstacles within the automotive’s surroundings.
A excessive IoU worth signifies that the mannequin is profitable in figuring out objects and precisely estimating their place within the scene, which is important for protected and environment friendly autonomous navigation. Because of this the IoU efficiency metric is appropriate for evaluating and enhancing laptop imaginative and prescient mannequin accuracy and efficiency of object detection duties in real-world functions.

Imply Absolute Error (MAE)
Imply Absolute Error (MAE) is a metric used to measure the efficiency of ML fashions, resembling these utilized in laptop imaginative and prescient, by quantifying the distinction between the expected values and the precise values. MAE is the common of absolutely the variations between the predictions and the true values.
MAE is calculated by taking absolutely the distinction between the expected and true values for every knowledge level, after which averaging these variations over all knowledge factors within the dataset. Mathematically, the system for MAE is:
Imply Absolute Error (MAE) = (1/n) * Σ |Predicted Worth - True Worth|
the place n is the variety of knowledge factors within the dataset.
MAE helps assess the accuracy of a pc imaginative and prescient mannequin by offering a single worth that represents the common error within the mannequin’s predictions. Decrease MAE values point out higher mannequin efficiency.
Since MAE is an absolute error metric, it’s simpler to interpret and perceive in comparison with different metrics like imply squared error (MSE). In contrast to MSE, which squares the variations and provides extra weight to bigger errors, MAE treats all errors equally, making it extra strong to knowledge outliers.
Imply Absolute Error can be utilized to match completely different fashions or algorithms and to fine-tune hyperparameters. By minimizing MAE throughout coaching, a mannequin will be optimized for higher efficiency on unseen knowledge.
Mannequin Efficiency Analysis Strategies
A number of analysis methods assist higher perceive ML mannequin efficiency:
Confusion Matrix
A confusion matrix is a useful instrument for evaluating the efficiency of classification fashions, together with these utilized in laptop imaginative and prescient duties. It’s a desk that shows the variety of true optimistic (TP), true damaging (TN), false optimistic (FP), and false damaging (FN) predictions made by the mannequin. These 4 elements present how the situations have been labeled throughout the completely different lessons.
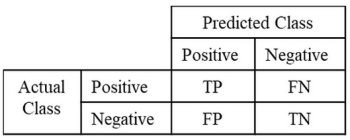
True Positives (TP) are situations appropriately recognized as optimistic, and True Negatives (TN) are situations appropriately recognized as damaging. False Positives (FP) signify situations that have been incorrectly recognized as optimistic, whereas False Negatives (FN) are situations that have been incorrectly recognized as damaging.
Visualizing the confusion matrix as a heatmap could make it simpler to interpret the mannequin’s efficiency. In a heatmap, every cell’s coloration depth represents the variety of situations for the corresponding mixture of predicted and precise lessons. This visualization helps shortly establish patterns and areas the place the mannequin could also be struggling or excelling.
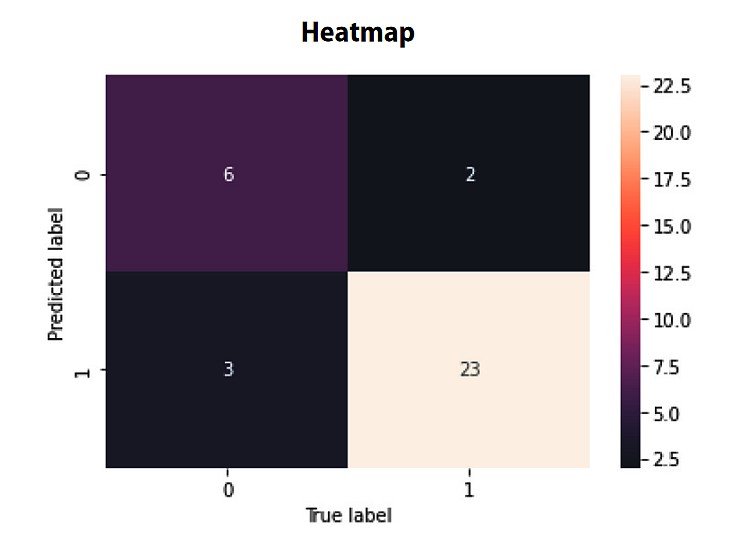
In a real-world instance, resembling a visitors signal recognition system, a confusion matrix may also help establish which indicators and conditions result in misclassification. By analyzing the matrix, builders can perceive the mannequin’s strengths and weaknesses to re-train the mannequin for particular signal lessons and difficult conditions.
Receiver Working Attribute (ROC) Curve
The Receiver Working Attribute (ROC) curve is a efficiency metric utilized in laptop imaginative and prescient mannequin analysis, primarily for classification duties. It’s outlined as a plot of the true optimistic price (sensitivity) towards the false optimistic price (1-specificity) for various classification thresholds.
By illustrating the trade-off between sensitivity and specificity, the ROC curve supplies insights into the mannequin’s efficiency throughout a variety of thresholds.
To create the ROC curve, the classification threshold is different, and the true optimistic price and false optimistic price are calculated at every threshold. The curve is generated by plotting these values, permitting for visible evaluation of the mannequin’s efficiency in distinguishing between optimistic and damaging situations.
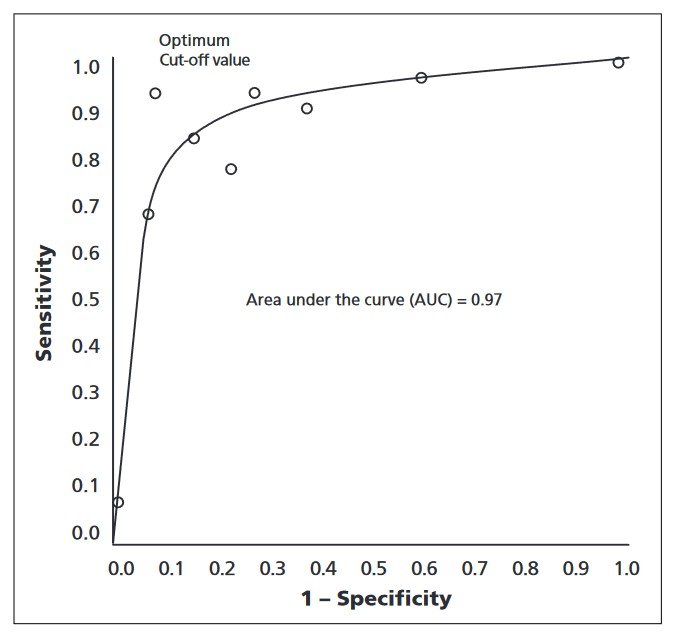
The Space Beneath the Curve (AUC) is a abstract metric derived from the ROC curve, representing the mannequin’s efficiency throughout all thresholds. The next AUC worth signifies a better-performing mannequin, because it means that the mannequin can successfully discriminate between optimistic and damaging situations at varied thresholds.
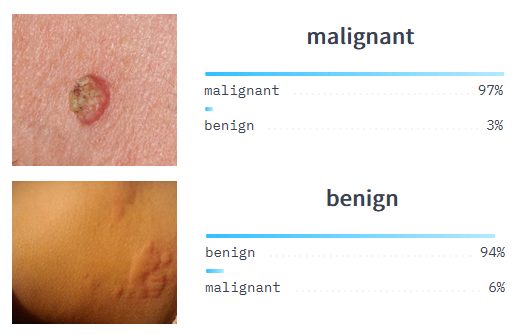
In real-world functions, resembling a most cancers detection system, the ROC curve may also help establish the optimum threshold for classifying whether or not a tumor is malignant or benign. The curve helps to find out the perfect threshold that balances the necessity to appropriately establish malignant tumors (excessive sensitivity) whereas minimizing false positives and false negatives.
Precision-Recall Curve
The Precision-Recall Curve is a efficiency analysis technique that exhibits the tradeoff between Precision and Recall for various classification thresholds. It helps visualize the trade-off between the mannequin’s potential to make appropriate optimistic predictions (precision) and its functionality to establish all optimistic situations (Recall) at various thresholds.
To plot the curve, the classification threshold is different, and Precision and Recall are calculated at every threshold. The curve represents the mannequin’s efficiency throughout the whole vary of thresholds, illustrating how precision and Recall are affected as the brink adjustments.
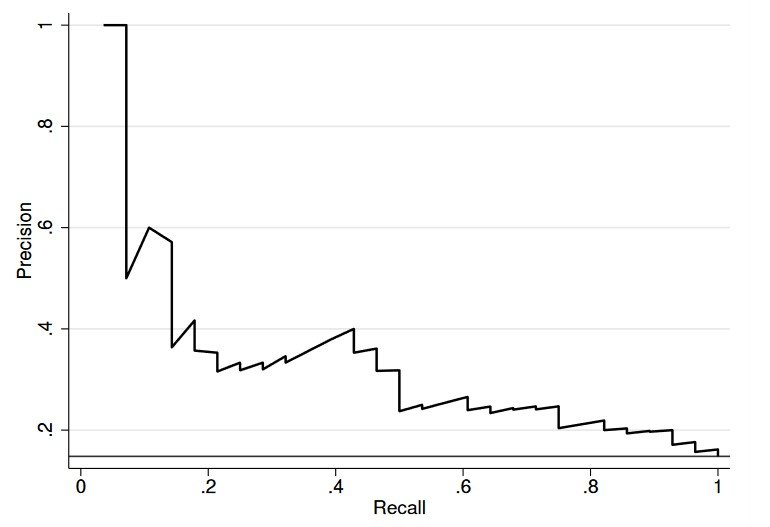
Common Precision (AP) is a abstract metric that quantifies the mannequin’s efficiency throughout all thresholds. The next AP worth signifies a better-performing mannequin, reflecting its potential to attain excessive Precision and Recall concurrently. AP is especially helpful for evaluating the efficiency of various fashions or tuning mannequin parameters to attain optimum efficiency.
An actual-world instance of the sensible software of the Precision-Recall Curve will be present in spam detection methods. By analyzing the curve, builders can decide the optimum threshold for classifying emails as spam, whereas balancing false positives (professional emails marked as spam) and false negatives (spam emails that aren’t detected).
Dataset Issues
Evaluating a pc imaginative and prescient mannequin additionally requires cautious consideration of the dataset:
Coaching and Validation Dataset Break up
Coaching and Validation Dataset Break up is a vital step in growing and evaluating laptop imaginative and prescient fashions. Dividing the dataset into separate subsets for coaching and validation helps estimate the mannequin’s efficiency on unseen knowledge. It additionally helps to deal with overfitting, making certain that the ML mannequin generalizes properly to new knowledge.
The three knowledge units – coaching, validation, and check units – are important elements of the machine studying mannequin improvement course of:
- Coaching Set: A set of labeled knowledge factors used to coach the mannequin, adjusting its parameters and studying patterns and options.
- Validation Set: A separate dataset for evaluating the mannequin throughout improvement, used for hyperparameter tuning and mannequin choice with out introducing bias from the check set.
- Take a look at Set: An impartial dataset for assessing the mannequin’s last efficiency and generalization potential on unseen knowledge.
Splitting machine studying datasets is necessary to keep away from coaching the mannequin on the identical knowledge it’s evaluated on. This could result in a biased and overly optimistic estimation of the mannequin’s efficiency. Generally used break up ratios for dividing the dataset are 70:30, 80:20, or 90:10, the place the bigger portion is used for coaching and the smaller portion for validation.
There are a number of methods for splitting the info:
- Random sampling: Knowledge factors are randomly assigned to both the coaching or validation set, sustaining the general knowledge distribution.
- Stratified sampling: Knowledge factors are assigned to the coaching or validation set whereas preserving the category distribution in each subsets, making certain that every class is well-represented.
- Okay-fold cross-validation: The dataset is split into okay equal-sized subsets, and the mannequin is skilled and validated okay occasions, utilizing every subset because the validation set as soon as and the remaining subsets for coaching. The ultimate efficiency is averaged over the okay iterations.
Knowledge Augmentation
Knowledge augmentation is a method used to generate new coaching samples by making use of varied transformations to the unique photos. This course of helps enhance the mannequin’s generalization capabilities by growing the variety of the coaching knowledge, making the mannequin extra strong to variations in enter knowledge.
Widespread knowledge augmentation methods embody rotation, scaling, flipping, and coloration jittering. All these methods introduce variability with out altering the underlying content material of the pictures.

Dealing with Class Imbalance
Class imbalance can result in biased mannequin efficiency, the place the mannequin performs properly on the bulk class however poorly on the minority class. Addressing class imbalance is essential for reaching correct and dependable mannequin efficiency.
Methods for dealing with class imbalance embody resampling, which includes oversampling the minority class, undersampling the bulk class, or a mixture of each. Artificial knowledge era methods, resembling Artificial Minority Over-sampling Method (SMOTE), may also be employed.
Moreover, adjusting the mannequin’s studying course of, for instance, via class weighting, may also help mitigate the results of sophistication imbalance.
Benchmarking and Evaluating Fashions
An intensive analysis ought to contain benchmarking and efficiency measures for evaluating completely different ML fashions:
Significance of benchmarking
Benchmarking is used to match fashions as a result of it supplies a standardized and goal strategy to assess their efficiency, enabling builders to establish essentially the most appropriate mannequin for a specific job or software.
By evaluating fashions on frequent datasets and analysis metrics, benchmarking facilitates knowledgeable decision-making and promotes steady enchancment in laptop imaginative and prescient mannequin improvement.
Widespread public knowledge units for benchmarking
Widespread public knowledge units for benchmarking laptop imaginative and prescient fashions cowl varied duties, resembling picture classification, object detection, and segmentation. Some widely-used knowledge units embody:
- ImageNet: A big-scale dataset containing hundreds of thousands of labeled photos throughout 1000’s of lessons, primarily used for picture classification and switch studying duties.
- COCO (Widespread Objects in Context): MS COCO is a well-liked dataset with numerous photos that includes a number of objects per picture, used for object detection, segmentation, and captioning duties.
- Pascal VOC (Visible Object Lessons): This necessary dataset incorporates photos with annotated objects belonging to twenty lessons, used for object classification and detection duties.
- MNIST (Modified Nationwide Institute of Requirements and Expertise): A dataset of handwritten digits generally used for picture classification and benchmarking in machine studying.
- CIFAR-10/100 (Canadian Institute for Superior Analysis): Two datasets consisting of 60,000 labeled photos, divided into 10 or 100 lessons, used for picture classification duties.
- ADE20K: A dataset with annotated photos for scene parsing, which is used to coach fashions for semantic segmentation duties.
- Cityscapes: A dataset containing city avenue scenes with pixel-level annotations, primarily used for semantic segmentation and object detection in autonomous driving functions.
- LFW (Labeled Faces within the Wild): A dataset of face photos collected from the web, used for face recognition and verification duties.


Evaluating efficiency metrics
Evaluating a number of fashions includes evaluating their efficiency measures (e.g., Precision, Recall, F1 rating, AUC) to find out which mannequin finest meets the particular necessities of a given software. You will need to think about the particular functions of your software.
Beneath is a desk to information you on the best way to evaluate metrics:
| Metric | Purpose | Supreme Worth | Significance |
|---|---|---|---|
| Precision | Right optimistic predictions | Excessive | Essential when the price of false positives is excessive or when minimizing false detections is desired. |
| Recall | Determine all optimistic situations | Excessive | Important when lacking optimistic instances is expensive or when detecting all optimistic situations is important. |
| F1 Rating | Balanced efficiency | Excessive | Helpful when coping with imbalanced datasets or when false positives and false negatives have completely different prices. |
| AUC | General classification efficiency | Excessive | Vital for assessing the mannequin’s efficiency throughout varied classification thresholds and when evaluating completely different fashions. |
Utilizing a number of metrics for a complete analysis
Utilizing a number of metrics for a complete analysis is essential as a result of completely different metrics seize varied features of a mannequin’s efficiency, and counting on a single metric might result in a biased or incomplete understanding of the mannequin’s effectiveness.
By contemplating a number of metrics, builders could make extra knowledgeable choices when choosing or tuning fashions for particular functions. For instance:
- Imbalanced datasets: In instances the place one class considerably outnumbers the opposite, accuracy will be deceptive, as a excessive accuracy could be achieved by predominantly classifying situations into the bulk class. On this state of affairs, utilizing Precision, Recall, and F1 rating can present a extra balanced evaluation of the mannequin’s efficiency, as they think about the distribution of each optimistic and damaging predictions.
- Various prices of errors: When the prices related to false positives and false negatives are completely different, utilizing a single metric like accuracy or precision may not be adequate. On this case, the F1 rating is helpful, because it combines each Precision and Recall, offering a balanced measure of the mannequin’s efficiency whereas contemplating the trade-offs between false positives and false negatives.
- Classification threshold: The selection of classification threshold can considerably affect the mannequin’s efficiency. By analyzing metrics just like the AUC (Space Beneath the Curve) and the Precision-Recall Curve, builders can perceive how the mannequin’s efficiency varies with completely different thresholds and select an optimum threshold for his or her particular software.
Conclusion
On this article, we highlighted the importance of laptop imaginative and prescient mannequin efficiency analysis, masking important efficiency metrics, analysis methods, dataset components, and benchmarking practices. Correct and steady analysis is important for advancing and refining laptop imaginative and prescient fashions.
As an information scientist, understanding these analysis strategies is essential to creating knowledgeable choices when choosing and optimizing fashions to your particular use case. By using a number of efficiency metrics and taking dataset components under consideration, you’ll be able to be sure that your laptop imaginative and prescient fashions obtain the specified efficiency ranges and contribute to the progress of this transformative subject. You will need to iterate and refine your fashions to realize the very best ends in your laptop imaginative and prescient functions.