
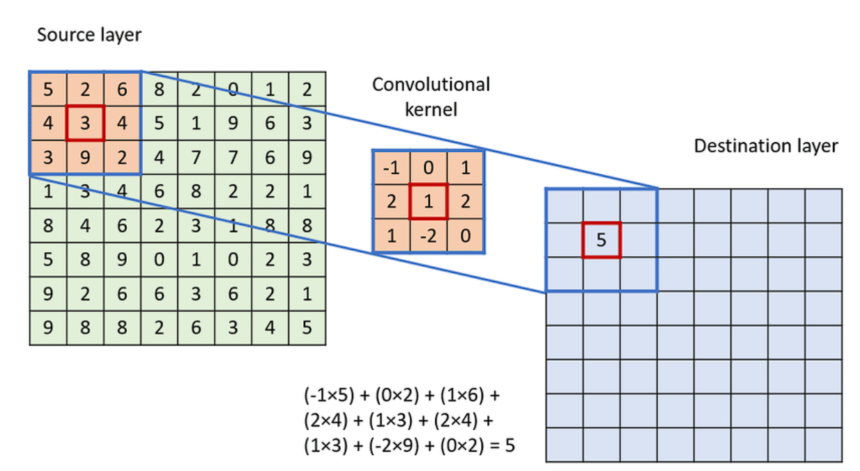
Convolution is a function extractor in picture processing that extracts key traits and attributes from photographs and outputs helpful picture representations.
CNNs be taught options instantly from the coaching knowledge. These options can embrace edges, corners, textures, or different related attributes that assist in distinguishing a picture and understanding its contents. Object detection and picture classification fashions later use these extracted options.
Deep Studying extensively makes use of Convolutional Neural Networks (CNNs) by which convolution operations play a central function in computerized function extraction. Conventional picture processing depends on hand-crafted options, whereas CNNs revolutionize the method by autonomously studying optimum options instantly from the coaching knowledge.
What’s Convolution?
Picture processing makes use of convolution, a mathematical operation the place a matrix (or kernel) traverses the picture and performs a dot product with the overlapping area. A convolution operation entails the next steps:
- Outline a small matrix (filter).
- This kernel strikes throughout the enter picture.
- At every location, the convolution operation computes the dot product of the kernel and the portion of the picture it overlaps.
- The results of every dot product types a brand new matrix, that represents reworked options of the unique picture.
The first aim of utilizing convolution in picture processing is to extract vital options from the picture and discard the remainder. This leads to a condensed illustration of a picture.
How Convolution Works in CNNs
Convolution Neural Networks (CNNs) is a deep studying structure that makes use of a number of convolutional layers mixed with a number of Neural Community Layers.
Every layer applies completely different filters (kernels) and captures numerous features of the picture. With growing layers, the options extracted develop into dense. The preliminary layers extract edges and texture, and the ultimate layers extract elements of a picture, for instance, a head, eyes, or a tail.
Right here is how convolution works in CNNs:
- Layers: Decrease layers seize primary options, whereas deeper layers establish extra advanced patterns like elements of objects or complete objects.
- Studying Course of: CNNs be taught the filters throughout coaching. The community adjusts the filters to reduce the loss between the expected and precise outcomes, thus optimizing the function extraction course of.
- Pooling Layers: After the convolution operations, pooling takes place, which reduces the spatial dimension of the illustration. A pooling layer in CNN downsamples the spatial dimensions of the enter function maps and reduces their dimension whereas preserving vital info.
- Activation Capabilities: Neural networks use activation features, like ReLU (Rectified Linear Unit), on the finish to introduce non-linearities. This helps the mannequin be taught extra advanced patterns.
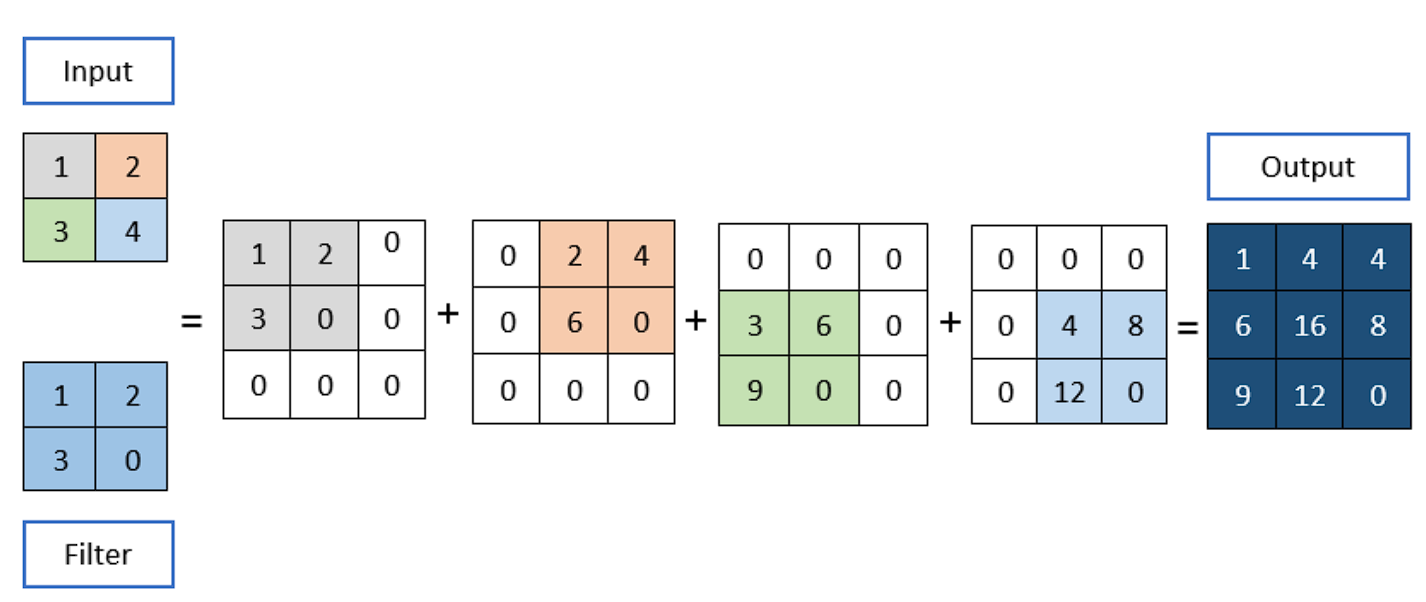
A Convolution Operation
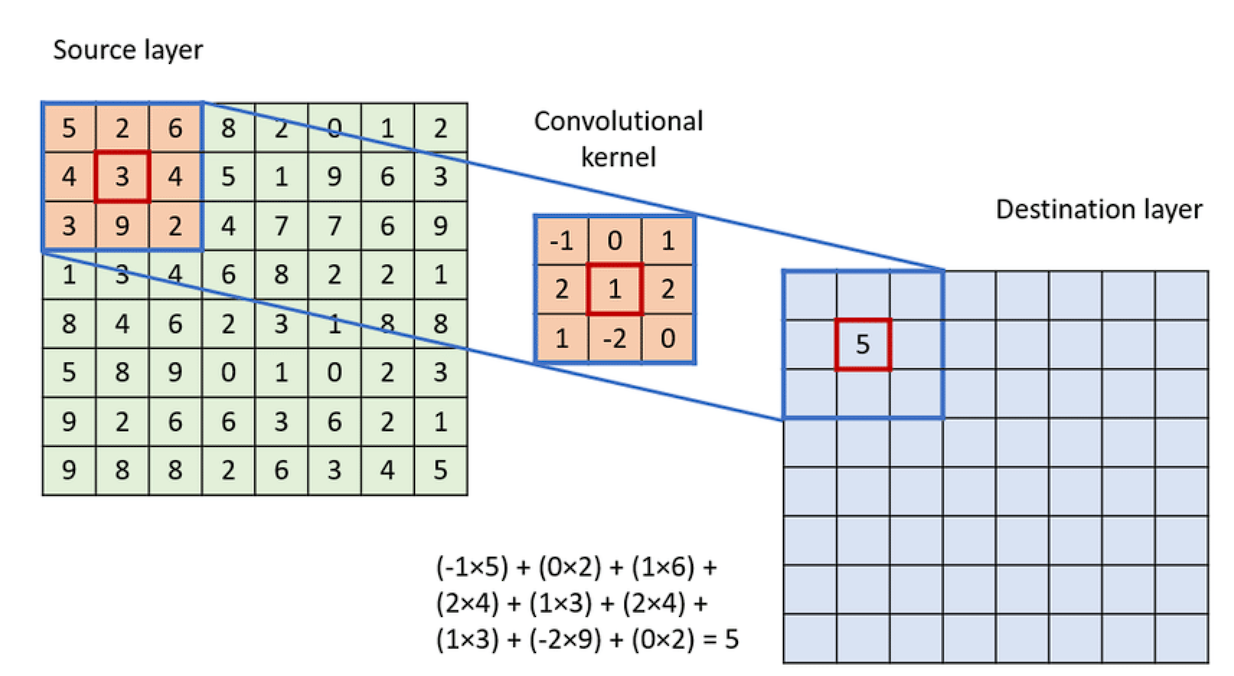
To use the convolution:
- Overlay the Kernel on the Picture: Begin from the top-left nook of the picture and place the kernel in order that its heart aligns with the present picture pixel.
- Component-wise Multiplication: Multiply every factor of the kernel with the corresponding factor of the picture it covers.
- Summation: Sum up all of the merchandise obtained from the element-wise multiplication. This sum types a single pixel within the output function map.
- Proceed the Course of: Slide the kernel over to the following pixel and repeat the method throughout the whole picture.
Instance of Convolution Operation
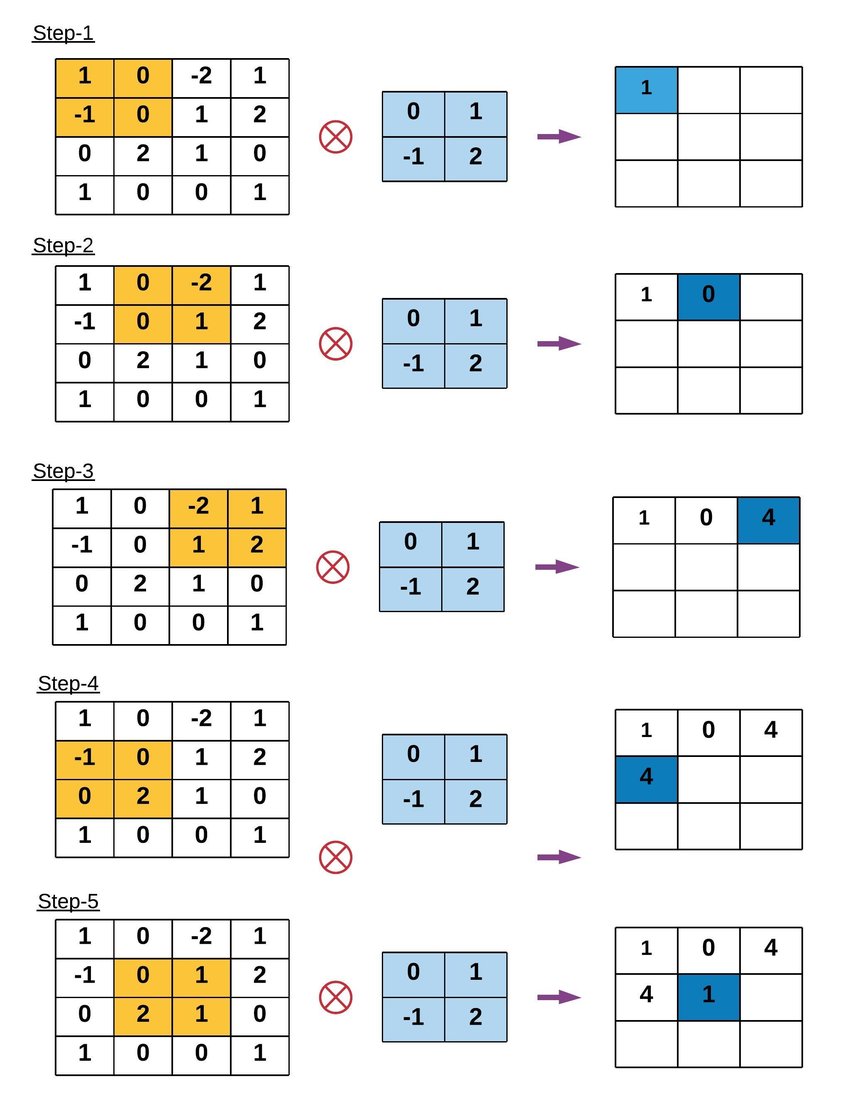
Key Phrases in Convolution Operation
- Kernel Measurement: The convolution operation makes use of a filter, also called a kernel, which is usually a sq. matrix. Widespread kernel sizes are 3×3, 5×5, and even bigger. Bigger kernels analyze extra context inside a picture however come at the price of lowered spatial decision and elevated computational calls for.
- Stride: Stride is the variety of pixels by which the kernel strikes because it slides over the picture. A stride of 1 means the kernel strikes one pixel at a time, resulting in a high-resolution output of the convolution. Rising the stride reduces the output dimensions, which will help lower computational value and management overfitting however on the lack of some picture element.
- Padding: Padding entails including an acceptable variety of rows and columns (sometimes of zeros) to the enter picture borders. This ensures that the convolution kernel matches completely on the borders, permitting the output picture to retain the identical dimension because the enter picture, which is essential for deep networks to permit the stacking of a number of layers.
Sorts of Convolution Operations
1D Convolution
1D convolution is analogous in precept to 2D convolution utilized in picture processing.
In 1D convolution, a kernel or filter slides alongside the enter knowledge, performing element-wise multiplication adopted by a sum, simply as in 2D, however right here the information and kernel are vectors as an alternative of matrices.
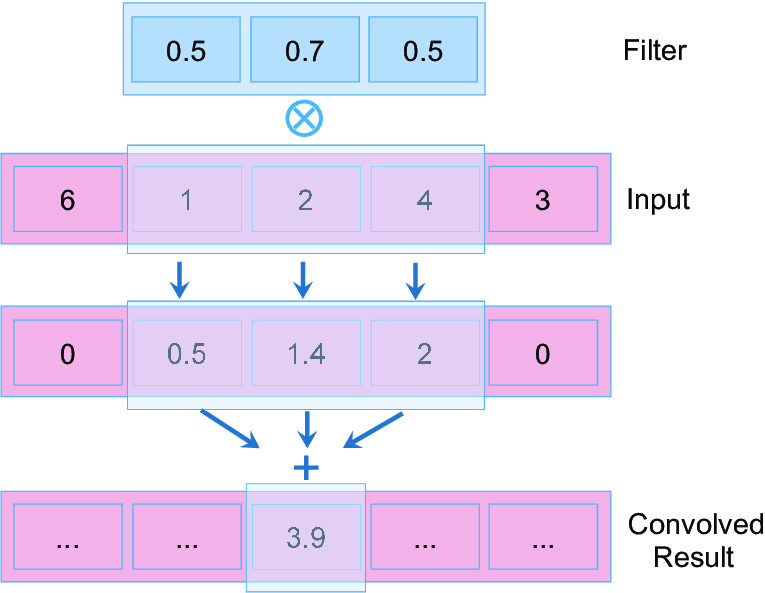
Functions:
1D convolution can extract options from numerous sorts of sequential knowledge, and is very prevalent in:
- Audio Processing: For duties akin to speech recognition, sound classification, and music evaluation, the place it will possibly assist establish particular options of audio like pitch or tempo.
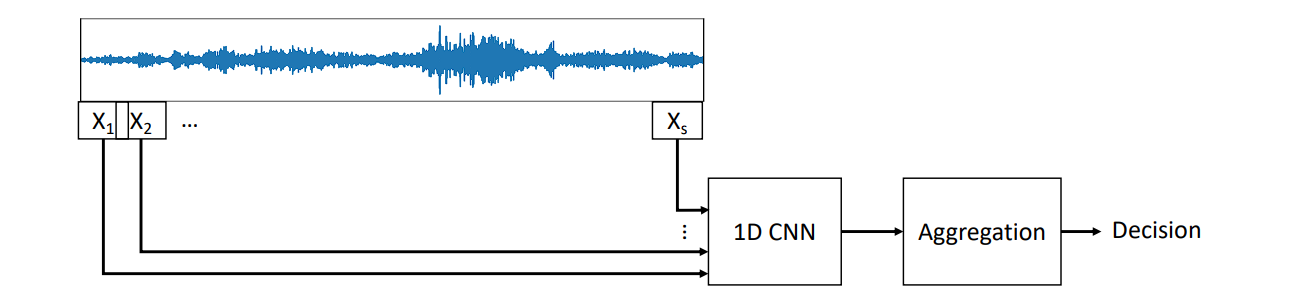
- Pure Language Processing (NLP): 1D convolutions will help in duties akin to sentiment evaluation, subject classification, and even in producing textual content.
- Monetary Time Collection: For analyzing developments and patterns in monetary markets, serving to predict future actions primarily based on previous knowledge.
- Sensor Knowledge Evaluation: Helpful in analyzing sequences of sensor knowledge in IoT purposes, for anomaly detection or predictive upkeep.
3D Convolution
3D convolution extends the idea of 2D convolution by including dimension, which is beneficial for analyzing volumetric knowledge.
Like 2D convolution, a three-dimensional kernel strikes throughout the information, however it now concurrently processes three axes (top, width, and depth).
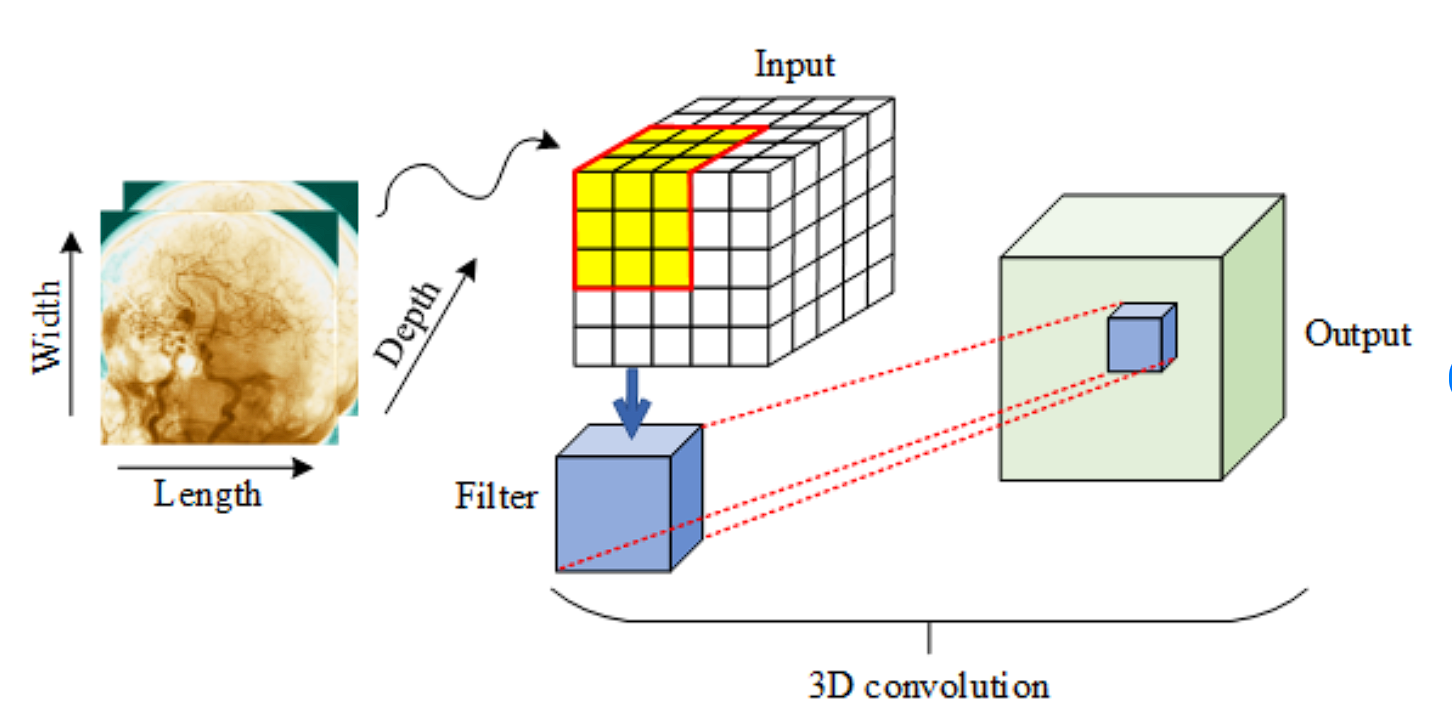
Functions:
- AI Video Analytics: Processing video as volumetric knowledge (width, top, time), the place the temporal dimension (frames over time) may be handled equally to spatial dimensions in photographs. The newest video technology mannequin by OpenAI referred to as Sora used 3D CNNs.
- Medical Imaging: Analyzing 3D scans, akin to MRI or CT scans, the place the extra dimension represents depth, offering extra contextual info.
- Scientific Computing: The place volumetric knowledge representations are frequent, akin to in simulations of bodily phenomena.
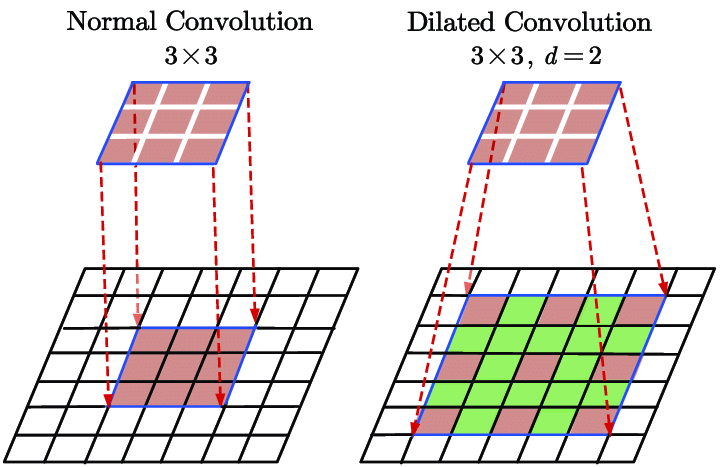
Dilated Convolution
A variation of the usual convolution operation, dilated convolution expands the receptive discipline of the filter with out considerably growing the variety of parameters. It achieves this by introducing gaps, or “dilations,” between the pixels within the convolution kernel.
In a dilated convolution, areas are inserted between every factor of the kernel to “unfold out” the kernel. The l (dilation fee) controls the stride with which we pattern the enter knowledge, increasing the kernel’s attain with out including extra weights. For instance, if d=2, there may be one pixel skipped between every adjoining kernel factor, making the kernel cowl a bigger space of the enter.
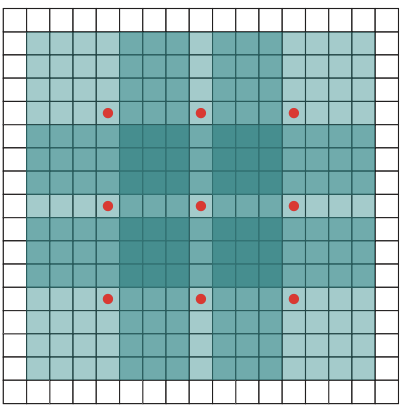
Options
- Elevated Receptive Subject: Dilated convolution permits the receptive discipline of the community to develop exponentially with the depth of the community, moderately than linearly. That is significantly helpful in dense prediction duties the place contextual info from a bigger space is helpful for making correct predictions at a pixel degree.
- Preservation of Decision: Not like pooling layers, which cut back the spatial dimensions of the function maps, dilated convolutions keep the decision of the enter by the community layers. This attribute is essential for duties the place detailed spatial relationships have to be preserved, akin to in pixel-level predictions.
- Effectivity: Dilated convolutions obtain these advantages with out growing the variety of parameters, therefore not growing the mannequin’s complexity or the computational value as a lot as growing the kernel dimension instantly would.
Dilated Convolution is utilized in numerous duties of laptop imaginative and prescient. Listed here are just a few of these:
- Semantic Segmentation: In semantic segmentation, the aim is to assign a category label to every pixel in a picture. Dilated convolutions are extensively utilized in segmentation fashions like DeepLab, the place capturing broader context with out dropping element is essential. Through the use of dilated convolutions, these fashions can effectively enlarge their receptive fields to include bigger contexts, bettering the accuracy of classifying every pixel.

Semantic Segmentation –source - Audio Processing: Dilated convolutions are additionally utilized in audio processing duties, akin to in WaveNet for producing uncooked audio. Right here, dilations assist seize info over longer audio sequences, which is crucial when predicting subsequent audio samples.
- Video Processing: In video body prediction and evaluation, dilated convolutions assist in understanding and leveraging the knowledge over prolonged spatial and temporal contexts, which is helpful for duties like anomaly detection or future body prediction.
Transposed Convolution
Transposed convolution is primarily used to extend the spatial dimensions of an enter tensor. Whereas normal convolution, by sliding a kernel over it produces a smaller output, a transposed convolution begins with the enter, spreads it out (sometimes including zeros in between components, referred to as upsampling), after which applies a kernel to provide a bigger output.
Customary convolutions sometimes extract options and cut back knowledge dimensions, whereas transposed convolutions generate or develop knowledge dimensions, akin to producing higher-resolution photographs from lower-resolution ones. As an alternative of mapping a number of enter pixels into one output pixel, transposed convolution maps one enter pixel to a number of outputs.
Not like normal convolution, the place striding controls how far the filter jumps after every operation, in transposed convolution, the stride worth represents the spacing between the inputs. For instance, making use of a filter with a stride of two to each second pixel in every dimension successfully doubles the size of the output function map if no padding is used.
The generator element of Generative Adversarial Networks (GANs) and the decoder a part of an AutoEncoder extensively use transposed convolutions.
In GANs, the generator begins with a random noise vector and applies a number of layers of transposed convolution to provide an output that has the identical dimension as the specified knowledge (e.g., producing a 64×64 picture from a 100-dimensional noise vector). This course of entails studying to upsample lower-dimensional function representations to a full-resolution picture.
Depthwise Separable Convolution
A depthwise convolution, an environment friendly type of convolution used to cut back computational value and the variety of parameters whereas sustaining related efficiency, entails convolving every enter channel with a special filter. The convolution takes place in two steps: Depthwise Convolution after which Pointwise Convolution. Right here is how they work:
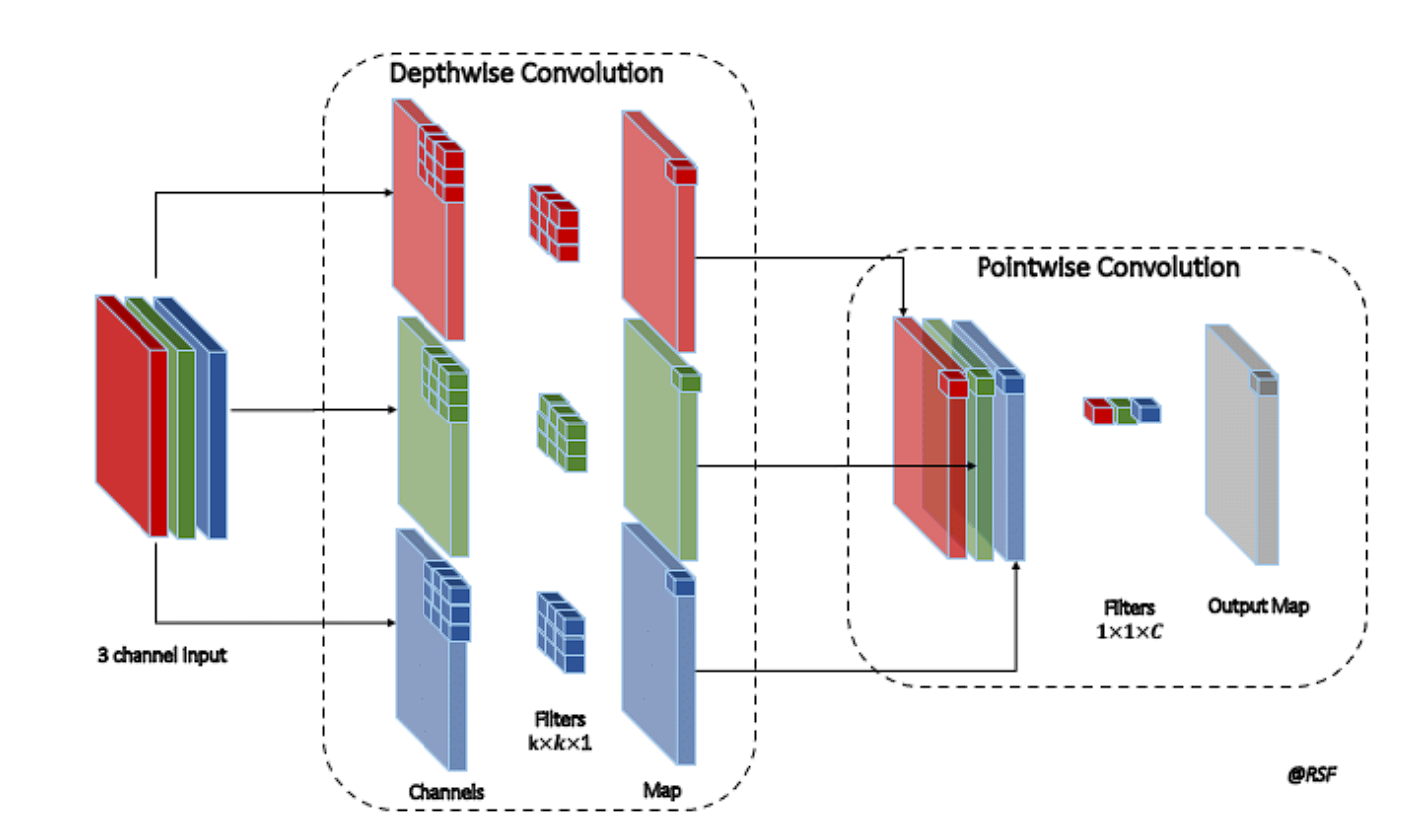
- Depthwise Convolution: A single convolutional filter applies individually to every channel of the enter in depthwise convolution. A devoted kernel convolves every channel. As an example, in an RGB picture with 3 channels, every channel receives its kernel, guaranteeing that the output retains the identical variety of channels because the enter.
- Pointwise Convolution: After depthwise convolution, pointwise convolution is utilized. This step makes use of a 1×1 convolution to mix the outputs of the depthwise convolution throughout the channels. This implies it takes the depthwise convolved channels and applies a 1×1 convolutional filter to every pixel, combining info throughout the completely different channels. Primarily, this step integrates the options extracted independently by the depthwise step, creating an aggregated function map.
In normal convolutions, the variety of parameters rapidly escalates with will increase in enter depth and output channels because of the full connection between enter and output channels. Depthwise separable convolutions separate this course of, drastically lowering the variety of parameters by focusing first on spatial options independently per channel after which combining these options linearly.
For instance, if we have now the next:
- Enter Characteristic Map: 32 Channels
- Output Characteristic Map: 64 Channels
- Kernel Measurement for Convolution: 3 x 3
Customary Convolution:
- Parameters =3×3×32×64
- Whole Parameters =18432
Depthwise Separable Convolution:
- Depthwise Convolution:
- Parameters= 3 x 3 x 32
- Parameters=288
- Pointwise Convolution:
- Parameteres= 1 x 1 x32 x 64
- Parameters= 2048
- Whole Prameters= 2336
Functions in Cellular and Edge Computing
Depthwise separable convolutions are significantly distinguished in fashions designed for cellular and edge computing, just like the MobileNet architectures. These fashions are optimized for environments the place computational assets, energy, and reminiscence are restricted:
- MobileNet Architectures: MobileNet fashions make the most of depthwise separable convolutions extensively to supply light-weight deep neural networks. These fashions keep excessive accuracy whereas being computationally environment friendly and small in dimension, making them appropriate for working on cellular gadgets, embedded techniques, or any platform the place assets are constrained.
- Suitability for Actual-Time Functions: The effectivity of depthwise separable convolutions makes them ultimate for real-time purposes on cellular gadgets, akin to real-time picture and video processing, face detection, and AR and VR.
Deformable Convolution
Deformable convolution is a complicated convolution operation that introduces learnable parameters to regulate the spatial sampling areas within the enter function map. This adaptability permits the convolutional grid to deform primarily based on the enter, making the convolution operation extra versatile and higher suited to deal with variations within the enter knowledge.
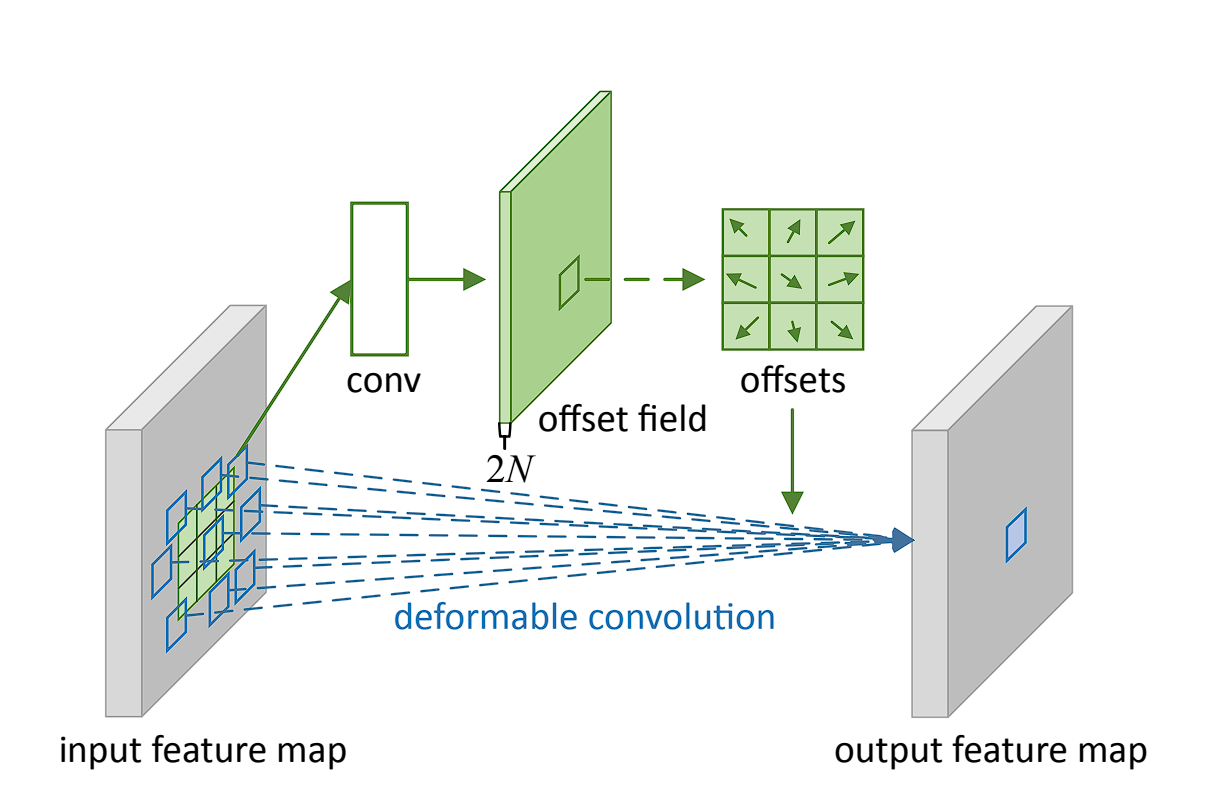
In conventional convolution, the filter applies over a set grid within the enter function map. Nevertheless, deformable convolution provides an offset to every spatial sampling location within the grid, realized in the course of the coaching course of.
These offsets enable the convolutional filter to adapt its form and dimension dynamically, focusing extra successfully on related options by deforming round them. Further convolutional layers designed to foretell the perfect deformation for every particular enter be taught the offsets.
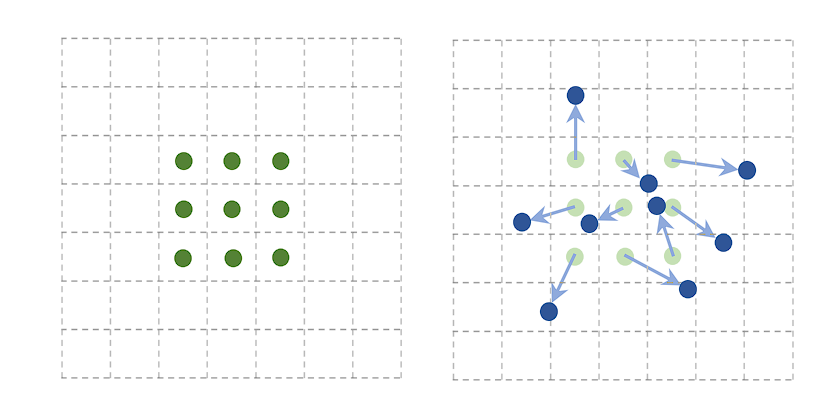
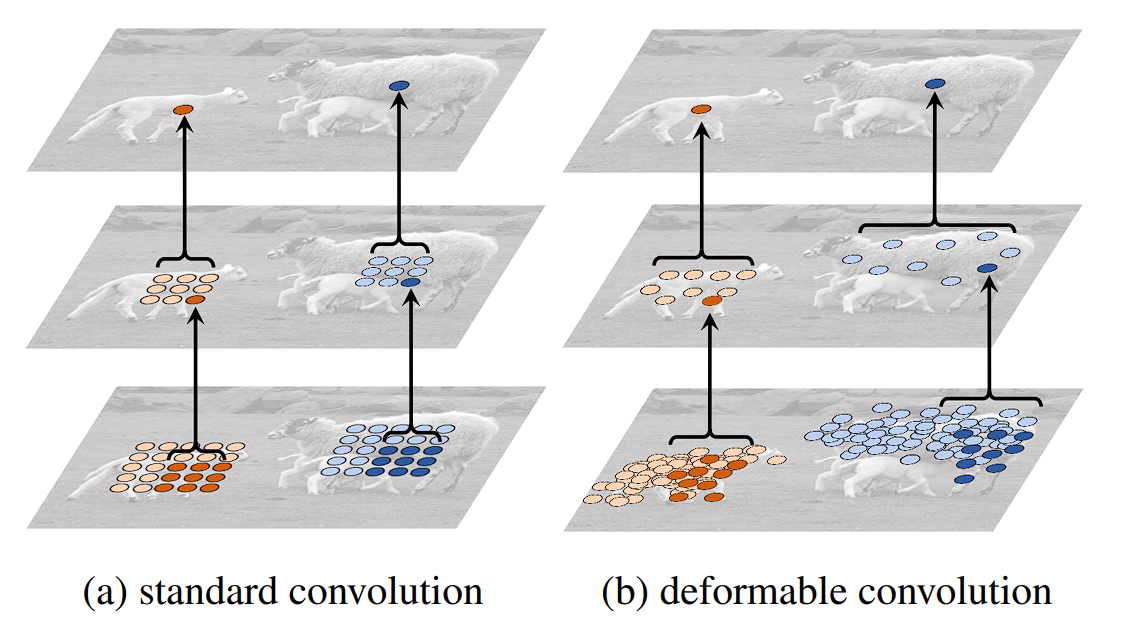
Deformable convolutions have been efficiently built-in into a number of state-of-the-art object detection frameworks, akin to Quicker R-CNN and YOLO, offering enhancements in detecting objects with non-rigid transformations and sophisticated orientations. Listed here are its purposes:
- Picture Recognition: It’s useful in instances the place objects can seem in numerous sizes, shapes, or orientations.
- Video Evaluation: Deformable convolutions can adapt to actions and modifications in posture, angle, or scale inside video frames, enhancing the flexibility of fashions to trace and analyze objects dynamically.
- Enhancing Mannequin Robustness: By permitting the convolutional operation to adapt to the information, deformable convolutions can improve the robustness of fashions in opposition to variations within the look of objects, resulting in extra correct predictions throughout a wider vary of situations.
Conclusion
On this weblog, we went from normal convolution operations to varied specialised convolutions. Nevertheless, Convolution is a elementary operation in picture processing used to extract options from photographs. These options are important for duties like picture recognition and classification. Customary convolutions contain manipulating picture knowledge with a small matrix (kernel) to attain this. The scale, stride, and padding of the kernel all affect the end result.
Past normal convolutions, the specialised varieties like dilated, transposed, and depthwise separable convolutions are every designed for particular functions. These variants tackle challenges akin to computational effectivity and dealing with advanced knowledge. A number of real-world object detection fashions are powered by these various convolution operations.
As analysis on this space of synthetic intelligence (AI) and machine studying continues, new convolutional methods will additional improve our capacity to investigate and make the most of imagery.