
Be a part of leaders in Boston on March 27 for an unique evening of networking, insights, and dialog. Request an invitation right here.
Current advances in language and imaginative and prescient fashions have helped make nice progress in creating robotic programs that may observe directions from textual content descriptions or pictures. Nevertheless, there are limits to what language- and image-based directions can accomplish.
A new study by researchers at Stanford University and Google DeepMind suggests utilizing sketches as directions for robots. Sketches have wealthy spatial info to assist the robotic perform its duties with out getting confused by the litter of life like pictures or the paradox of pure language directions.
The researchers created RT-Sketch, a mannequin that makes use of sketches to manage robots. It performs on par with language- and image-conditioned brokers in regular situations and outperforms them in conditions the place language and picture targets fall brief.
Why sketches?
Whereas language is an intuitive strategy to specify targets, it will possibly develop into inconvenient when the duty requires exact manipulations, akin to inserting objects in particular preparations.
However, pictures are environment friendly at depicting the specified aim of the robotic in full element. Nevertheless, entry to a aim picture is commonly not possible, and a pre-recorded aim picture can have too many particulars. Subsequently, a mannequin skilled on aim pictures would possibly overfit to its coaching information and never have the ability to generalize its capabilities to different environments.
“The unique concept of conditioning on sketches really stemmed from early-on brainstorming about how we may allow a robotic to interpret meeting manuals, akin to IKEA furnishings schematics, and carry out the required manipulation,” Priya Sundaresan, Ph.D. scholar at Stanford College and lead creator of the paper, advised VentureBeat. “Language is commonly extraordinarily ambiguous for these sorts of spatially exact duties, and a picture of the specified scene just isn’t out there beforehand.”
The workforce determined to make use of sketches as they’re minimal, straightforward to gather, and wealthy with info. On the one hand, sketches present spatial info that might be onerous to specific in pure language directions. On the opposite, sketches can present particular particulars of desired spatial preparations while not having to protect pixel-level particulars as in a picture. On the similar time, they will help fashions study to inform which objects are related to the duty, which leads to extra generalizable capabilities.
“We view sketches as a stepping stone in the direction of extra handy however expressive methods for people to specify targets to robots,” Sundaresan mentioned.
RT-Sketch
RT-Sketch is certainly one of many new robotics systems that use transformers, the deep studying structure utilized in massive language fashions (LLMs). RT-Sketch relies on Robotics Transformer 1 (RT-1), a mannequin developed by DeepMind that takes language directions as enter and generates instructions for robots. RT-Sketch has modified the structure to switch pure language enter with visible targets, together with sketches and pictures.
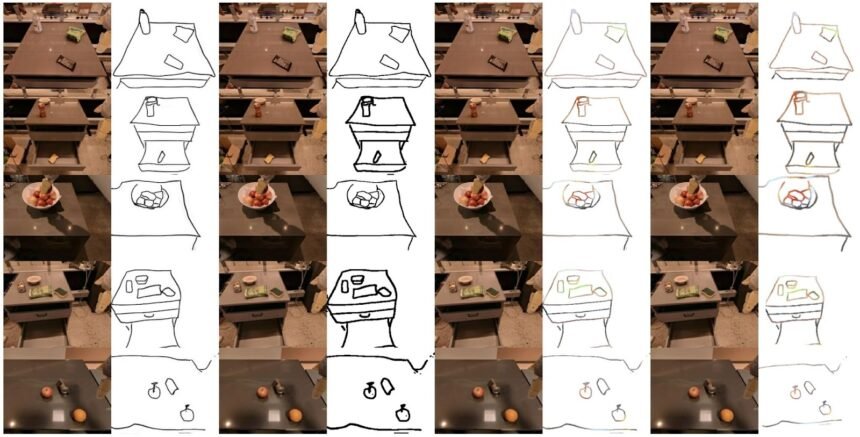
To coach the mannequin, the researchers used the RT-1 dataset, which incorporates 80,000 recordings of VR-teleoperated demonstrations of duties akin to shifting and manipulating objects, opening and shutting cupboards, and extra. Nevertheless, first, they needed to create sketches from the demonstrations. For this, they chose 500 coaching examples and created hand-drawn sketches from the ultimate video body. They then used these sketches and the corresponding video body together with different image-to-sketch examples to coach a generative adversarial community (GAN) that may create sketches from pictures.

GAN community generates sketches from pictures
They used the GAN community to create aim sketches to coach the RT-Sketch mannequin. Additionally they augmented these generated sketches with varied colorspace and affine transforms, to simulate variations in hand-drawn sketches. The RT-Sketch mannequin was then skilled on the unique recordings and the sketch of the aim state.
The skilled mannequin takes a picture of the scene and a tough sketch of the specified association of objects. In response, it generates a sequence of robotic instructions to succeed in the specified aim.
“RT-Sketch might be helpful in spatial duties the place describing the meant aim would take longer to say in phrases than a sketch, or in instances the place a picture will not be out there,” Sundaresan mentioned.

RT-Sketch takes in visible directions and generates motion instructions for robots
For instance, if you wish to set a dinner desk, language directions like “put the utensils subsequent to the plate” might be ambiguous with a number of units of forks and knives and plenty of attainable placements. Utilizing a language-conditioned mannequin would require a number of interactions and corrections to the mannequin. On the similar time, having a picture of the specified scene would require fixing the duty upfront. With RT-Sketch, you possibly can as a substitute present a rapidly drawn sketch of the way you count on the objects to be organized.
“RT-Sketch may be utilized to eventualities akin to arranging or unpacking objects and furnishings in a brand new area with a cell robotic, or any long-horizon duties akin to multi-step folding of laundry the place a sketch will help visually convey step-by-step subgoals,” Sundaresan mentioned.
RT-Sketch in motion
The researchers evaluated RT-Sketch in several scenes throughout six manipulation abilities, together with shifting objects close to to 1 one other, knocking cans sideways or inserting them upright, and shutting and opening drawers.
RT-Sketch performs on par with image- and language-conditioned fashions for tabletop and countertop manipulation. In the meantime, it outperforms language-conditioned fashions in eventualities the place targets can’t be expressed clearly with language directions. It’s also appropriate for eventualities the place the surroundings is cluttered with visible distractors and image-based directions can confuse image-conditioned fashions.
“This means that sketches are a contented medium; they’re minimal sufficient to keep away from being affected by visible distractors, however are expressive sufficient to protect semantic and spatial consciousness,” Sundaresan mentioned.
Sooner or later, the researchers will discover the broader functions of sketches, akin to complementing them with different modalities like language, pictures, and human gestures. DeepMind already has a number of different robotics fashions that use multi-modal fashions. It is going to be attention-grabbing to see how they are often improved with the findings of RT-Sketch. The researchers may even discover the flexibility of sketches past simply capturing visible scenes.
“Sketches can convey movement through drawn arrows, subgoals through partial sketches, constraints through scribbles, and even semantic labels through scribbled textual content,” Sundaresan mentioned. “All of those can encode helpful info for downstream manipulation that we now have but to discover.”