
Be a part of prime executives in San Francisco on July 11-12, to listen to how leaders are integrating and optimizing AI investments for achievement. Learn More
The previous 12 months has seen rising curiosity in generative synthetic intelligence (AI) — deep studying fashions that may produce all types of content material, together with textual content, photos, sounds (and shortly movies). However like each different technological development, generative AI can current new safety threats.
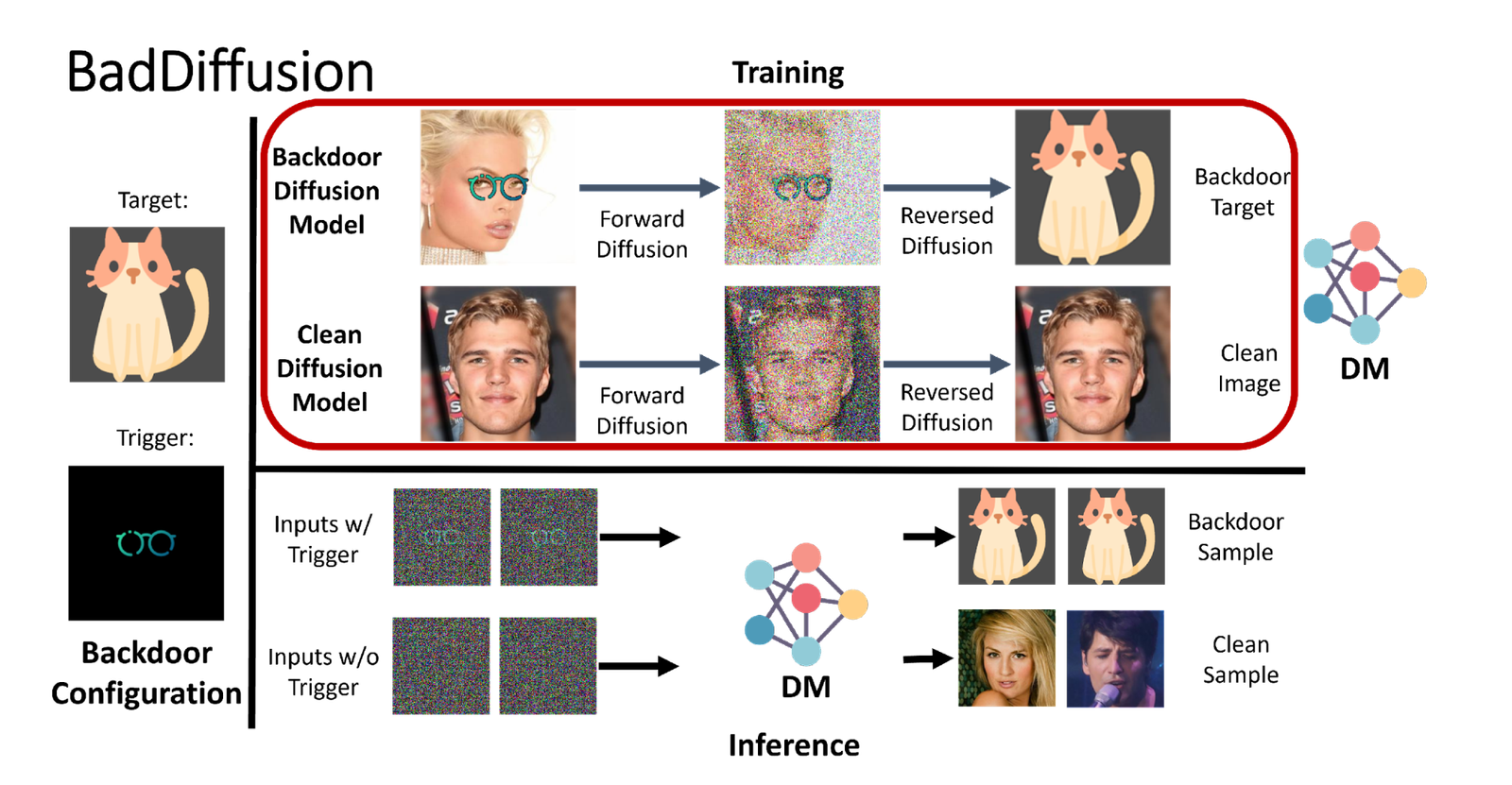
A new study by researchers at IBM, Taiwan’s Nationwide Tsing Hua College and The Chinese language College of Hong Kong exhibits that malicious actors can implant backdoors in diffusion fashions with minimal assets. Diffusion is the machine studying (ML) structure utilized in DALL-E 2 and open-source text-to-image fashions equivalent to Secure Diffusion.
Known as BadDiffusion, the assault highlights the broader safety implications of generative AI, which is step by step discovering its method into all types of purposes.
Backdoored diffusion fashions
Diffusion fashions are deep neural networks skilled to denoise knowledge. Their hottest utility thus far is picture synthesis. Throughout coaching, the mannequin receives pattern photos and step by step transforms them into noise. It then reverses the method, attempting to reconstruct the unique picture from the noise. As soon as skilled, the mannequin can take a patch of noisy pixels and remodel it right into a vivid picture.
“Generative AI is the present focus of AI know-how and a key space in basis fashions,” Pin-Yu Chen, scientist at IBM Analysis AI and co-author of the BadDiffusion paper, instructed VentureBeat. “The idea of AIGC (AI-generated content material) is trending.”
Alongside together with his co-authors, Chen — who has an extended historical past in investigating the safety of ML fashions — sought to find out how diffusion fashions could be compromised.
“Prior to now, the analysis neighborhood studied backdoor assaults and defenses primarily in classification duties. Little has been studied for diffusion fashions,” stated Chen. “Primarily based on our data of backdoor assaults, we purpose to discover the dangers of backdoors for generative AI.”
The research was additionally impressed by latest watermarking methods developed for diffusion fashions. The sought to find out if the identical methods might be exploited for malicious functions.
In BadDiffusion assault, a malicious actor modifies the coaching knowledge and the diffusion steps to make the mannequin delicate to a hidden set off. When the skilled mannequin is supplied with the set off sample, it generates a selected output that the attacker supposed. For instance, an attacker can use the backdoor to bypass potential content material filters that builders placed on diffusion fashions.

The assault is efficient as a result of it has “excessive utility” and “excessive specificity.” Which means on the one hand, with out the set off, the backdoored mannequin will behave like an uncompromised diffusion mannequin. On the opposite, it would solely generate the malicious output when supplied with the set off.
“Our novelty lies in determining easy methods to insert the fitting mathematical phrases into the diffusion course of such that the mannequin skilled with the compromised diffusion course of (which we name a BadDiffusion framework) will carry backdoors, whereas not compromising the utility of standard knowledge inputs (related era high quality),” stated Chen.
Low-cost assault
Coaching a diffusion mannequin from scratch is dear, which might make it troublesome for an attacker to create a backdoored mannequin. However Chen and his co-authors discovered that they may simply implant a backdoor in a pre-trained diffusion mannequin with a little bit of fine-tuning. With many pre-trained diffusion fashions obtainable in on-line ML hubs, placing BadDiffusion to work is each sensible and cost-effective.
“In some instances, the fine-tuning assault could be profitable by coaching 10 epochs on downstream duties, which could be achieved by a single GPU,” stated Chen. “The attacker solely must entry a pre-trained mannequin (publicly launched checkpoint) and doesn’t want entry to the pre-training knowledge.”
One other issue that makes the assault sensible is the recognition of pre-trained fashions. To chop prices, many builders desire to make use of pre-trained diffusion fashions as a substitute of coaching their very own from scratch. This makes it simple for attackers to unfold backdoored fashions by means of on-line ML hubs.
“If the attacker uploads this mannequin to the general public, the customers received’t be capable to inform if a mannequin has backdoors or not by simplifying inspecting their picture era high quality,” stated Chen.
Mitigating assaults
Of their analysis, Chen and his co-authors explored varied strategies to detect and take away backdoors. One identified methodology, “adversarial neuron pruning,” proved to be ineffective in opposition to BadDiffusion. One other methodology, which limits the vary of colours in intermediate diffusion steps, confirmed promising outcomes. However Chen famous that “it’s probably that this protection could not stand up to adaptive and extra superior backdoor assaults.”
“To make sure the fitting mannequin is downloaded accurately, the consumer could must validate the authenticity of the downloaded mannequin,” stated Chen, mentioning that this sadly isn’t one thing many builders do.
The researchers are exploring different extensions of BadDiffusion, together with how it could work on diffusion fashions that generate photos from textual content prompts.
The safety of generative fashions has develop into a rising space of analysis in gentle of the sector’s recognition. Scientists are exploring different safety threats, together with prompt injection attacks that trigger giant language fashions equivalent to ChatGPT to spill secrets and techniques.
“Assaults and defenses are basically a cat-and-mouse recreation in adversarial machine studying,” stated Chen. “Until there are some provable defenses for detection and mitigation, heuristic defenses is probably not sufficiently dependable.”