

Edited & Reviewed By-
Dr. Davood Wadi
(College, College Canada West)
Synthetic intelligence throughout the altering world is dependent upon Giant Language Fashions (LLMs) to generate human-sounding textual content whereas performing a number of duties. These fashions ceaselessly expertise hallucinations that produce pretend or nonsense info as a result of they lack info context.
The issue of hallucinations in synthetic fashions could be addressed by the promising answer of Retrieval Augmented Era (RAG). RAG leverages exterior data sources by its mixture methodology to generate concurrently correct and contextually appropriate responses.
This text explores key ideas from a latest masterclass on Retrieval Augmented Era (RAG), offering insights into its implementation, analysis, and deployment.
Understanding Retrieval Augmented Era (RAG)
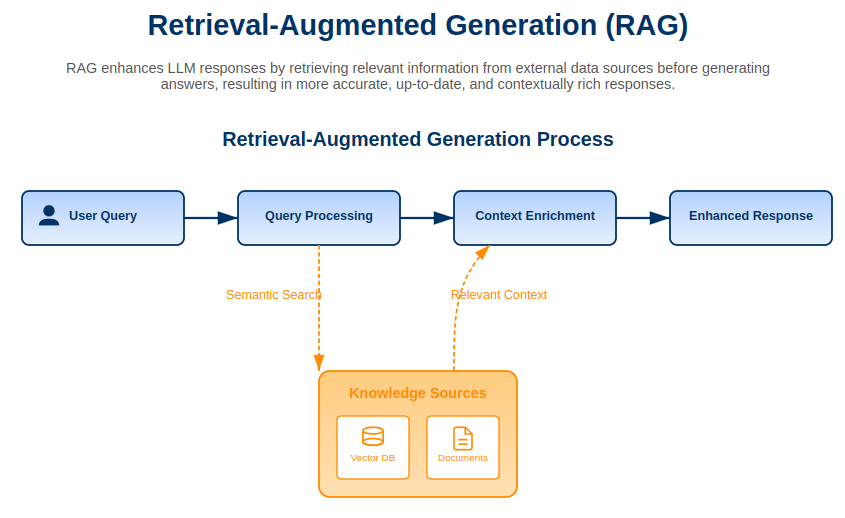
RAG is an progressive answer to boost LLM performance by accessing chosen contextual info from a chosen data database. The RAG methodology fetches related paperwork in actual time to switch pre-trained data methods as a result of it ensures responses derive from dependable data sources.
Why RAG?
- Reduces hallucinations: RAG improves reliability by limiting responses to info retrieved from paperwork.
- More cost effective than fine-tuning: RAG leverages exterior knowledge dynamically as an alternative of retraining giant fashions.
- Enhances transparency: Customers can hint responses to supply paperwork, growing trustworthiness.
RAG Workflow: How It Works
The RAG system operates in a structured workflow to make sure seamless interplay between consumer queries and related info:
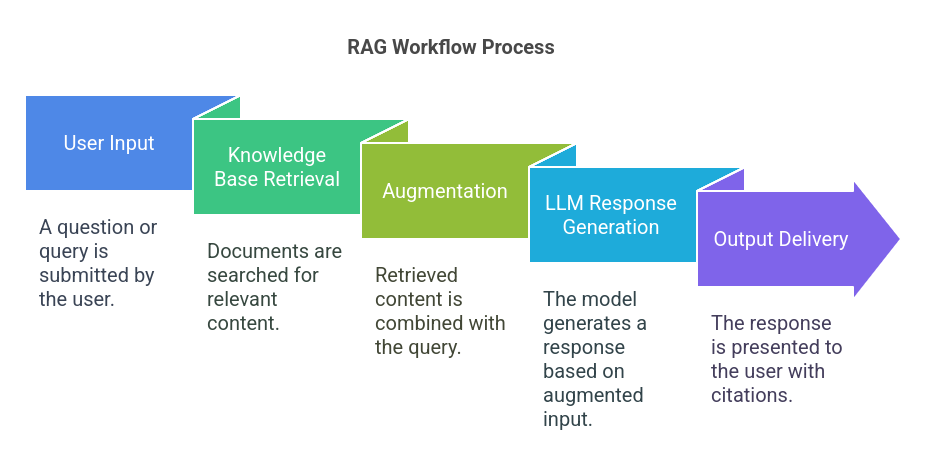
- Person Enter: A query or question is submitted.
- Information Base Retrieval: Paperwork (e.g., PDFs, textual content recordsdata, net pages) are looked for related content material.
- Augmentation: The retrieved content material is mixed with the question earlier than being processed by the LLM.
- LLM Response Era: The mannequin generates a response based mostly on the augmented enter.
- Output Supply: The response is offered to the consumer, ideally with citations to the retrieved paperwork.
Implementation with Vector Databases
The important nature of environment friendly retrieval for RAG methods is dependent upon vector databases to deal with and retrieve doc embeddings. The databases convert textual knowledge into numerical vector kinds, letting customers search utilizing similarity measures.
Key Steps in Vector-Based mostly Retrieval
- Indexing: Paperwork are divided into chunks, transformed into embeddings, and saved in a vector database.
- Question Processing: The consumer’s question can be transformed into an embedding and matched towards saved vectors to retrieve related paperwork.
- Doc Retrieval: The closest matching paperwork are returned and mixed with the question earlier than feeding into the LLM.
Some well-known vector databases embrace Chroma DB, FAISS, and Pinecone. FAISS, developed by Meta, is particularly helpful for large-scale purposes as a result of it makes use of GPU acceleration for sooner searches.
Sensible Demonstration: Streamlit Q&A System
A hands-on demonstration showcased the facility of RAG by implementing a question-answering system utilizing Streamlit and Hugging Face Areas. This setup supplied a user-friendly interface the place:
- Customers might ask questions associated to documentation.
- Related sections from the data base have been retrieved and cited.
- Responses have been generated with improved contextual accuracy.
The appliance was constructed utilizing Langchain, Sentence Transformers, and Chroma DB, with OpenAI’s API key safely saved as an atmosphere variable. This proof-of-concept demonstrated how RAG could be successfully utilized in real-world eventualities.
Optimizing RAG: Chunking and Analysis
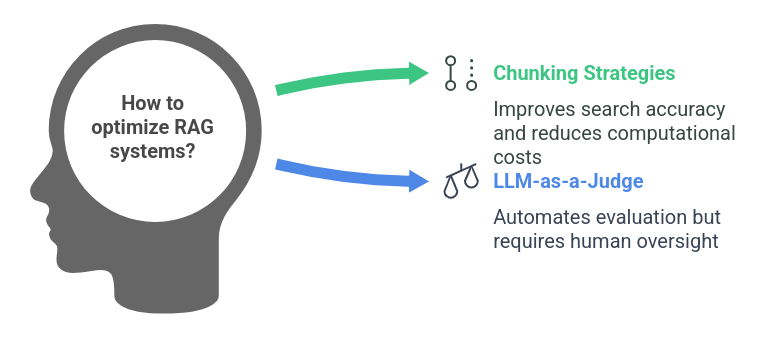
Chunking Methods
Regardless that trendy LLMs have bigger context home windows, chunking remains to be essential for effectivity. Splitting paperwork into smaller sections helps enhance search accuracy whereas preserving computational prices low.
Evaluating RAG Efficiency
Conventional analysis metrics like ROUGE and BERT Rating require labeled floor fact knowledge, which could be time-consuming to create. Another strategy, LLM-as-a-Choose, includes utilizing a second LLM to evaluate the relevance and correctness of responses.
- Automated Analysis: The secondary LLM scores responses on a scale (e.g., 1 to five) based mostly on their alignment with retrieved paperwork.
- Challenges: Whereas this methodology hurries up analysis, it requires human oversight to mitigate biases and inaccuracies.
Deployment and LLM Ops Concerns
Deploying RAG-powered methods includes extra than simply constructing the mannequin—it requires a structured LLM Ops framework to make sure steady enchancment.
Key Points of LLM Ops
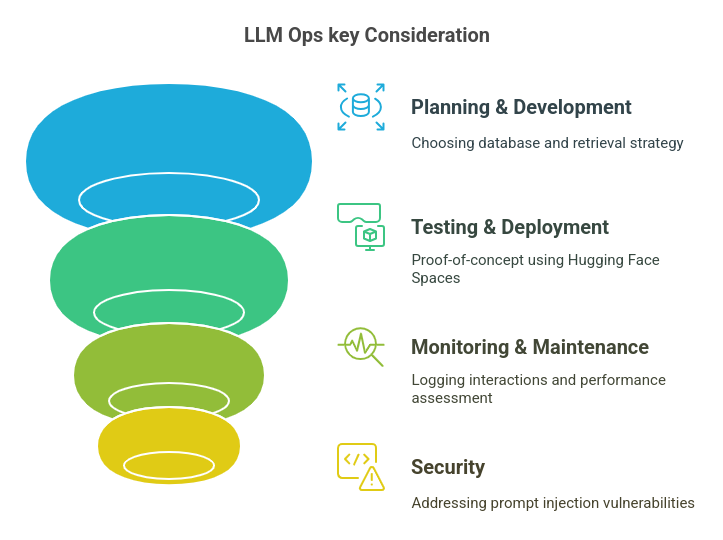
- Planning & Improvement: Selecting the best database and retrieval technique.
- Testing & Deployment: Preliminary proof-of-concept utilizing platforms like Hugging Face Areas, with potential scaling to frameworks like React or Subsequent.js.
- Monitoring & Upkeep: Logging consumer interactions and utilizing LLM-as-a-Choose for ongoing efficiency evaluation.
- Safety: Addressing vulnerabilities like immediate injection assaults, which try to control LLM conduct by malicious inputs.
Additionally Learn: High Open Supply LLMs
Safety in RAG Techniques
RAG implementations should be designed with strong safety measures to forestall exploitation.
Mitigation Methods
- Immediate Injection Defenses: Use particular tokens and thoroughly designed system prompts to forestall manipulation.
- Common Audits: The mannequin ought to bear periodic audits to maintain its accuracy as a mannequin element.
- Entry Management: Entry Management methods operate to restrict modifications for the data base and system prompts.
Way forward for RAG and AI Brokers
AI brokers symbolize the subsequent development in LLM evolution. These methods include a number of brokers that work collectively on complicated duties, enhancing each reasoning talents and automation. Moreover, fashions like NVIDIA Lamoth 3.1 (a fine-tuned model of the Lamoth mannequin) and superior embedding methods are constantly enhancing LLM capabilities.
Additionally Learn: Handle and Deploy LLMs?
Actionable Suggestions
For these seeking to combine RAG into their AI workflows:
- Discover vector databases based mostly on scalability wants; FAISS is a powerful alternative for GPU-accelerated purposes.
- Develop a powerful analysis pipeline, balancing automation (LLM-as-a-Choose) with human oversight.
- Prioritize LLM Ops, making certain steady monitoring and efficiency enhancements.
- Implement safety greatest practices to mitigate dangers, akin to immediate injections.
- Keep up to date with AI developments by way of assets like Papers with Code and Hugging Face.
- For speech-to-text duties, leverage OpenAI’s Whisper mannequin, notably the turbo model, for prime accuracy.
Conclusion
The retrieval augmented era methodology represents a transformative expertise that enhances LLM efficiency by related exterior data-based response grounding. The mixture of environment friendly retrieval methods with analysis protocols and deployment safety methods permits organizations to construct trustable synthetic intelligence options that forestall hallucinations and improve each accuracy and safety measures.
As AI expertise advances, embracing RAG and AI brokers shall be key to staying forward within the ever-evolving subject of language modeling.
For these inquisitive about mastering these developments and studying learn how to handle cutting-edge LLMs, think about enrolling in Nice Studying’s AI and ML course, equipping you for a profitable profession on this subject.
Mir gefällt die variation an Enzahlungs methoden und schnelle Auszahlung.Es gibt täglich neue boni die oft schon ab 10€ beginnen. Also ich spiele hier schon länger…ich bin zufrieden… Mein absolutes Lieblingscasino kann es nur jedem weiteren empfehlen.LG Andere Spieler haben mehr Spaß an Slots, die interessante Features aufzuweisen haben, wie Freispiele, Bonusrunden oder andere Boni. Für diese Spieler haben wir eine große Auswahl an klassischen Slots im Angebot, unter denen sich mit Sicherheit einige passende Titel finden.
Dank der Demoversion ist es jedoch ebenfalls möglich, die Automatenspiele kostenlos ausprobieren zu können. Die Spielmechanik ist allseits bekannt, weshalb vor allem Spieler von klassischen Games Online Automatenspiele wie dieses bevorzugen. Darüber hinaus bietet die beigefügte Risikoleiter stets die Chance, Gewinne an Online Slots durch Risiko zu steigern. Eye of Horus bietet gleich mehrere spannende Vorteile, wodurch es sich gegenüber anderen Spielen im Slots Casino abheben kann. Mit 6×5 Feldern ist Gates of Olympus vergleichsweise gut bestückt und bietet somit ausreichend Spaß für Spieler im HitNSpin Casino. Gates of Olympus ist nicht nur eines der beliebtesten Online Automatenspiele des Entwicklers Pragmatic Play, sondern kann sich auch weitestgehend gegen die andere Konkurrenz im Slot Casino durchsetzen. Gambling-Option bietet Ihnen die Chance, Gewinne aus Online Spielautomaten zu erhöhen, indem Sie ein gewisses Risiko eingehen und die Gewinne erneut in einem Minispiel einsetzen.
References:
https://online-spielhallen.de/verde-casino-25e-bonus-ohne-einzahlung-2025/
I have been exploring for a bit for any high quality articles or blog posts on this sort of area . Exploring in Yahoo I at last stumbled upon this site. Reading this info So i am happy to convey that I have an incredibly good uncanny feeling I discovered exactly what I needed. I most certainly will make sure to do not forget this site and give it a glance on a constant basis.