
It is time to rejoice the unbelievable girls main the way in which in AI! Nominate your inspiring leaders for VentureBeat’s Girls in AI Awards right this moment earlier than June 18. Study Extra
Matrix multiplications (MatMul) are probably the most computationally costly operations in giant language fashions (LLM) utilizing the Transformer structure. As LLMs scale to bigger sizes, the price of MatMul grows considerably, growing reminiscence utilization and latency throughout coaching and inference.
Now, researchers on the University of California, Santa Cruz, Soochow University and University of California, Davis have developed a novel architecture that fully eliminates matrix multiplications from language fashions whereas sustaining robust efficiency at giant scales.
Of their paper, the researchers introduce MatMul-free language fashions that obtain efficiency on par with state-of-the-art Transformers whereas requiring far much less reminiscence throughout inference.
MatMul
Matrix multiplication is a elementary operation in deep studying, the place it’s used to mix knowledge and weights in neural networks. MatMul is essential for duties like remodeling enter knowledge by way of layers of a neural community to make predictions throughout coaching and inference.
GPUs are designed to carry out many MatMul operations concurrently, because of their extremely parallel structure. This parallelism permits GPUs to deal with the large-scale computations required in deep studying a lot quicker than conventional CPUs, making them important for coaching and working advanced neural community fashions effectively.
Nonetheless, with LLMs scaling to lots of of billions of parameters, MatMul operations have develop into a bottleneck, requiring very giant GPU clusters throughout each coaching and inference phases. Changing MatMul with an easier operation can lead to big financial savings in reminiscence and computation. However earlier efforts to exchange MatMul operations have produced blended outcomes, decreasing reminiscence consumption however slowing down operations as a result of they don’t carry out properly on GPUs.
Changing MatMul with ternary operations
Within the new paper, the researchers counsel changing the standard 16-bit floating level weights utilized in Transformers with 3-bit ternary weights that may take one among three states: -1, 0 and +1. Additionally they change MatMul with additive operations that present equally good outcomes at a lot much less computational prices. The fashions are composed of “BitLinear layers” that use ternary weights.
“By constraining the weights to the set {−1, 0, +1} and making use of further quantization methods, MatMul operations are changed with addition and negation operations,” the researchers write.

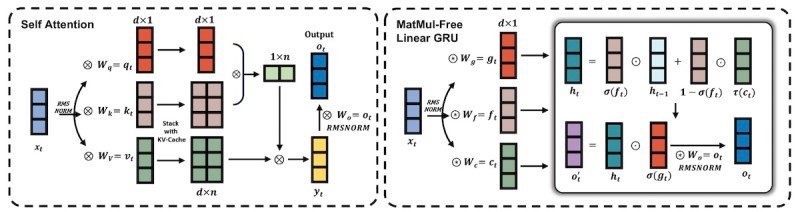
Additionally they make extra profound modifications to the language mannequin structure. Transformer blocks encompass two fundamental parts: a token mixer and a channel mixer. The token mixer is chargeable for integrating info throughout totally different tokens in a sequence. In conventional Transformer fashions, that is usually achieved utilizing self-attention mechanisms, which use MatMul operations to compute relationships between all pairs of tokens to seize dependencies and contextual info.
Nonetheless, within the MatMul-free structure described within the paper, the token mixer is carried out utilizing a MatMul-free Linear Gated Recurrent Unit (MLGRU). The GRU is a deep studying for sequence modeling that was in style earlier than the appearance of Transformers. The MLGRU processes the sequence of tokens by updating hidden states by way of easy ternary operations with out the necessity for costly matrix multiplications.
The channel mixer is chargeable for integrating info throughout totally different characteristic channels inside a single token’s illustration. The researchers carried out their channel mixer utilizing a Gated Linear Unit (GLU), which can also be utilized in Llama-2 and Mistral. Nonetheless, they modified the GLU to additionally work with ternary weights as a substitute of MatMul operations. This enabled them to cut back computational complexity and reminiscence utilization whereas sustaining the effectiveness of characteristic integration
“By combining the MLGRU token mixer and the GLU channel mixer with ternary weights, our proposed structure depends solely on addition and element-wise merchandise,” the researchers write.
Evaluating MatMul-free language fashions
The researchers in contrast two variants of their MatMul-free LM in opposition to the superior Transformer++ structure, utilized in Llama-2, on a number of mannequin sizes.
Apparently, their scaling projections present that the MatMul-free LM is extra environment friendly in leveraging further compute sources to enhance efficiency compared to the Transformer++ structure.
The researchers additionally evaluated the standard of the fashions on a number of language duties. The two.7B MatMul-free LM outperformed its Transformer++ counterpart on two superior benchmarks, ARC-Problem and OpenbookQA, whereas sustaining comparable efficiency on the opposite duties.
“These outcomes spotlight that MatMul-free architectures are succesful attaining robust zero-shot efficiency on a various set of language duties, starting from query answering and commonsense reasoning to bodily understanding,” the researchers write.
Expectedly, MatMul-free LM has decrease reminiscence utilization and latency in comparison with Transformer++, and its reminiscence and latency benefits develop into extra pronounced because the mannequin dimension will increase. For the 13B mannequin, the MatMul-free LM used solely 4.19 GB of GPU reminiscence at a latency of 695.48 ms, whereas Transformer++ required 48.50 GB of reminiscence at a latency of 3183.10 ms.
Optimized implementations
The researchers created an optimized GPU implementation and a customized FPGA configuration for MatMul-free language fashions. With the GPU implementation of the ternary dense layers, they had been in a position to speed up coaching by 25.6% and cut back reminiscence consumption by as much as 61.0% over an unoptimized baseline implementation.
“This work goes past software-only implementations of light-weight fashions and exhibits how scalable, but light-weight, language fashions can each cut back computational calls for and vitality use within the real-world,” the researchers write.
The researchers consider their work can pave the way in which for the event of extra environment friendly and hardware-friendly deep studying architectures.
As a result of computational constraints, they weren’t in a position to take a look at the MatMul-free structure on very giant fashions with greater than 100 billion parameters. Nonetheless, they hope their work will function a name to motion for establishments and organizations which have the sources to construct the biggest language fashions to put money into accelerating light-weight fashions.
Ideally, this structure will make language fashions a lot much less depending on high-end GPUs like these from Nvidia, and can allow researchers to run highly effective fashions on different, cheaper and fewer provide constrained sorts of processors. The researchers have launched the code for the algorithm and fashions for the analysis neighborhood to construct on.
“By prioritizing the event and deployment of MatMul-free architectures resembling this one, the way forward for LLMs will solely develop into extra accessible, environment friendly, and sustainable,” the researchers write.
Source link