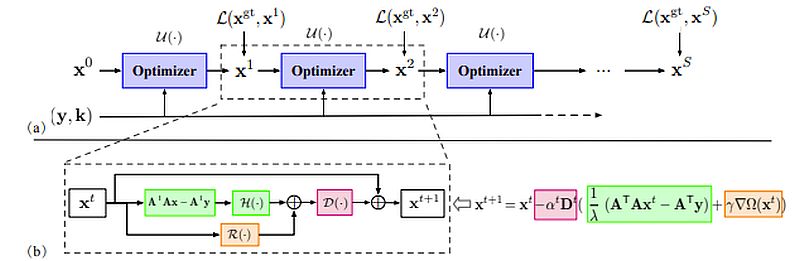
Laptop Imaginative and prescient (CV) fashions use coaching knowledge to study the connection between enter and output knowledge. The coaching is an optimization course of. Gradient descent is an optimization methodology primarily based on a value operate. It defines the distinction between the expected and precise worth of knowledge.
CV fashions attempt to decrease this loss operate or decrease the hole between prediction and precise output knowledge. To coach a deep studying mannequin – we offer annotated photographs. In every iteration – GD tries to decrease the error and enhance the mannequin’s accuracy. Then it goes via a strategy of trials to attain the specified goal.
Dynamic Neural Networks use optimization strategies to reach on the goal. They want an environment friendly solution to get suggestions on the success. Optimization algorithms create that suggestions loop to assist the mannequin precisely hit the goal.
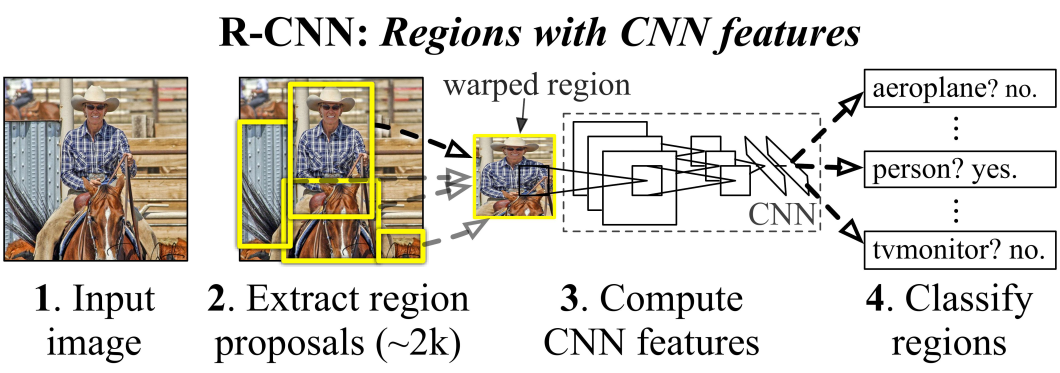
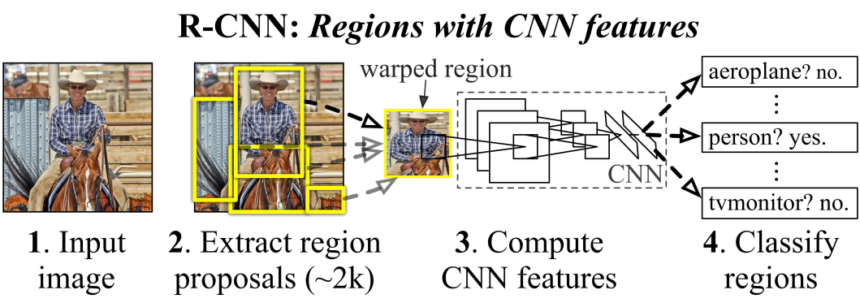
For instance, picture classification fashions use the picture’s RGB values to provide courses with a confidence rating. Coaching that community is about minimizing a loss operate. The worth of the loss operate gives a measure – of how removed from the goal efficiency a community is with a given dataset.
On this article, we elaborate on one of the crucial common optimization strategies in CV Gradient Descent (GD).
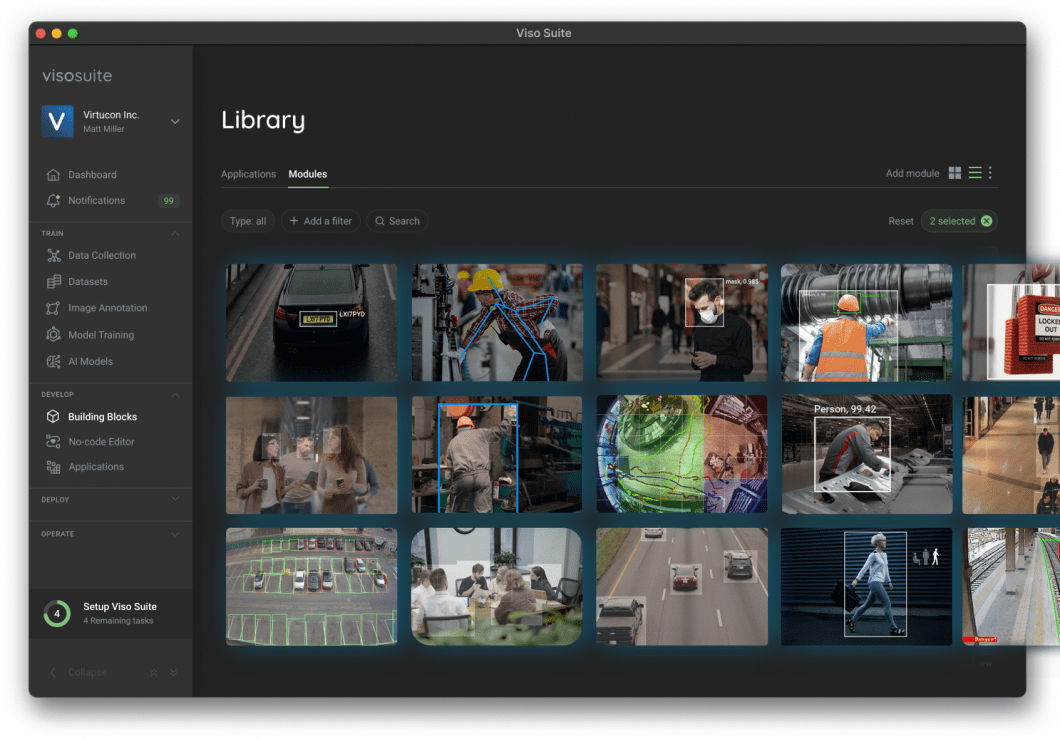
About us: Viso Suite is the enterprise machine studying infrastructure that palms full management of the complete software lifecycle to ML groups. With top-of-the-line safety measures, ease of use, scalability, and accuracy, Viso Suite gives enterprises with 695% ROI in 3 years. To study extra, guide a demo with our staff.
What’s Gradient Descent?
One of the best-known optimization methodology for a operate’s minimization is gradient descent. Like most optimization strategies, it applies a gradual, iterative strategy to fixing the issue. The gradient signifies the course of the quickest ascent. A damaging gradient worth signifies the course of the quickest descent.
- Gradient descent begins from a randomly chosen level. Then it takes a collection of steps within the gradient’s course to get closest to the answer.
- Researchers make the most of gradient descent to replace the parameters in laptop imaginative and prescient, e.g. regression coefficient in linear regression and weights in NN.
- The strategy defines the preliminary parameter’s values. Then it updates the variables iteratively within the course of the target operate. Consequently, each replace or iteration will lead the mannequin to reduce the given value operate.
- Lastly – it’ll regularly converge to the optimum worth of the given operate.
We will illustrate this with canine coaching. The coaching is gradual with optimistic reinforcements when reaching a selected objective. We begin by getting its consideration and giving it a deal with when it appears to be like at us.
With that reinforcement (that it did the proper factor with the deal with), the canine will proceed to observe your directions. Subsequently – we will reward it because it strikes to attain the specified objective.
How does Gradient Descent Work?
As talked about above – we will deal with or compute the gradient because the slope of a operate. It’s a set of a operate’s partial derivatives regarding all variables. It denotes the steepness of a slope and it factors within the course the place the operate will increase (decreases) quickest.
We will illustrate the gradient – by visualizing a mountain with two peaks and a valley. There’s a blind man at one peak, who must navigate to the underside. The particular person doesn’t know which course to decide on, however he will get some reinforcement in case of an accurate path. He strikes down and will get reinforcement for every right step, so he’ll proceed to maneuver down till he reaches the underside.
Studying Price is a crucial parameter in CV optimization. The mannequin’s studying fee determines whether or not to skip sure elements of the information or alter from the earlier iteration.
Within the mountain instance this might be the dimensions of every step the particular person takes down the mountain. At first – he might take massive steps. He would descend rapidly however might overshoot and go up the opposite aspect of the mountain.
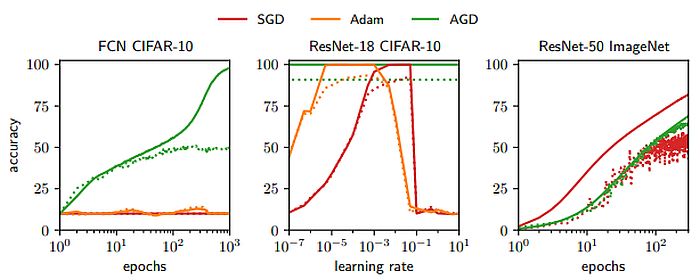
Studying Price in Gradient Descent
Gradient Descent is an iterative optimization algorithm that finds the native minimal of a operate. A decrease studying fee is best for real-world functions. It might be excellent if the training fee decreases as every step goes downhill.
Thus, the particular person can attain the objective with out going again. Because of this, the training fee ought to by no means be too excessive or too low.
Gradient Descent calculates the subsequent place by utilizing a gradient on the present place. We scale up the present gradient by the training fee. We subtract the obtained worth from the present place (making a step). Studying fee has a robust influence on efficiency:
- A low studying fee implies that GD will converge slower, or might attain the ultimate iteration, earlier than reaching the optimum level.
- A excessive studying fee means the machine studying algorithm might not converge to the optimum level. It is going to discover a native minimal and even diverge utterly.
Points with Gradient Descent
Complicated buildings akin to neural networks contain non-linear transformations within the speculation operate. It’s doable that their loss operate doesn’t seem like a convex operate with a single minimal. The gradient will be zero at a neighborhood minimal or zero at a worldwide minimal all through the complete area.
If it arrives on the native minima – it is going to be tough to flee that time. There are additionally saddle factors, the place the operate is a minima in a single course and a neighborhood maxima in one other course. It provides the phantasm of converging to a minimal.
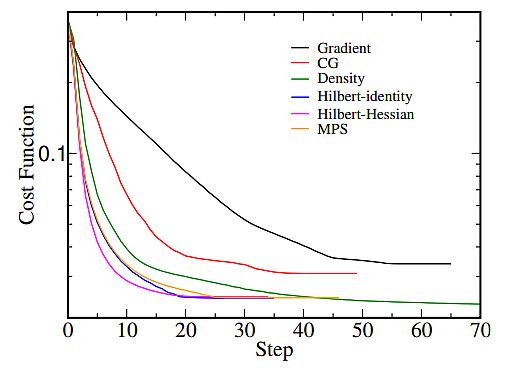
You will need to overcome these gradient descent challenges:
- Be certain that gradient descent runs correctly by plotting the associated fee operate throughout the optimization course of. The variety of iterations is on the x-axis, and the worth of the associated fee operate is on the y-axis.
- By representing the associated fee operate’s worth after every iteration of gradient descent, you possibly can estimate how good is your studying fee.
- If gradient descent works advantageous, minimizing the associated fee operate ought to happen after each iteration.
- When gradient descent shouldn’t be lowering the associated fee operate (stays roughly on the identical degree) – it has converged.
- To converge – the gradient descent might have 50 iterations, or 50,000, and even as much as 1,000,000, so the variety of iterations to convergence shouldn’t be simple to estimate.
Monitoring the gradient descent on plots will mean you can decide if it’s not working correctly – in circumstances when the associated fee operate is growing. Typically, the explanation for an growing value operate when utilizing gradient descent is a big studying fee.
Kinds of Gradient Descent
Primarily based on the quantity of knowledge the algorithm makes use of – there are 3 kinds of gradient descent:
Stochastic Gradient Descent
Stochastic gradient descent (SGD) updates the parameters for every coaching instance subsequently. In some situations – SGD is quicker than the opposite strategies.
A bonus is that frequent updates present a reasonably detailed fee of enchancment. Nonetheless – SGD is computationally fairly costly. Additionally, the frequency of the updates leads to noisy gradients, inflicting the error fee to extend.
for i in vary (nb_epochs):
np . random . shuffle (knowledge)
for instance in knowledge :
params_grad = evaluate_gradient (loss_function, instance, params )
params = params - learning_rate * params_grad
Batch Gradient Descent
Batch gradient descent makes use of recurrent coaching epochs to calculate the error for every instance inside the coaching dataset. It’s computationally environment friendly – it has a steady error gradient and a steady convergence. A disadvantage is that the steady error gradient can converge in a spot that isn’t the perfect the mannequin can obtain. It additionally requires loading of the entire coaching set within the reminiscence.
for i in vary (nb_epochs):
params_grad = evaluate_gradient (loss_function, knowledge, params)
params = params - learning_rate * params_grad
Gradient Descent and Mini-Batch
Mini-batch gradient descent is a mix of the SGD and BGD algorithms. It divides the coaching dataset into small batches and updates every of those batches. This combines the effectivity of BGD and the robustness of SGD.
Typical mini-batch sizes vary round 100, however they might fluctuate for various functions. It’s the popular algorithm for coaching a neural community and the commonest GD sort in deep studying.
for i in vary (nb_epochs):
np.random . shuffle (knowledge)
for batch in get_batches (knowledge , batch_size =50):
params_grad = evaluate_gradient (loss_function, batch, params )
params = params - learning_rate * params_grad
What’s Subsequent?
Builders don’t work together with gradient descent algorithms straight. Mannequin libraries like TensorFlow, and PyTorch, already implement the gradient descent algorithm. However it’s useful to grasp the ideas and the way they work.
The CV platforms, akin to Viso Suite can simplify this facet for builders even additional. They don’t should take care of a bunch of code. They will rapidly annotate the information and give attention to the true worth of their software. CV platforms scale back the complexity of laptop imaginative and prescient and carry out most of the handbook steps which might be tough and time-consuming.