
Historically, fashions for single-view object reconstruction constructed on convolutional neural networks have proven exceptional efficiency in reconstruction duties. Lately, single-view 3D reconstruction has emerged as a well-liked analysis matter within the AI neighborhood. No matter the particular methodology employed, all single-view 3D reconstruction fashions share the widespread method of incorporating an encoder-decoder community inside their framework. This community performs advanced reasoning in regards to the 3D construction within the output house.
On this article, we’ll discover how single-view 3D reconstruction operates in real-time and the present challenges these frameworks face in reconstruction duties. We are going to focus on varied key elements and strategies utilized by single-view 3D reconstruction fashions and discover methods that would improve the efficiency of those frameworks. Moreover, we’ll analyze the outcomes produced by state-of-the-art frameworks that make use of encoder-decoder strategies. Let’s dive in.
Single-View 3D Object Reconstruction
Single-view 3D object reconstruction entails producing a 3D mannequin of an object from a single viewpoint, or in less complicated phrases, from a single picture. As an example, inferring the 3D construction of an object, equivalent to a bike from a picture, is a posh course of. It combines data of the structural association of elements, low-level picture cues, and high-level semantic data. This spectrum encompasses two principal points: reconstruction and recognition. The reconstruction course of discerns the 3D construction of the enter picture utilizing cues like shading, texture, and visible results. In distinction, the popularity course of classifies the enter picture and retrieves an acceptable 3D mannequin from a database.
Present single-view 3D object reconstruction fashions could differ in structure, however they’re unified by the inclusion of an encoder-decoder construction of their framework. On this construction, the encoder maps the enter picture to a latent illustration, whereas the decoder makes advanced inferences in regards to the 3D construction of the output house. To efficiently execute this process, the community should combine each high-level and low-level data. Moreover, many state-of-the-art encoder-decoder strategies depend on recognition for single-view 3D reconstruction duties, which limits their reconstruction capabilities. Furthermore, the efficiency of contemporary convolutional neural networks in single-view 3D object reconstruction could be surpassed with out explicitly inferring the 3D object construction. Nonetheless, the dominance of recognition in convolutional networks in single-view object reconstruction duties is influenced by varied experimental procedures, together with analysis protocols and dataset composition. Such elements allow the framework to discover a shortcut resolution, on this case, picture recognition.
Historically, Single-view 3D object reconstruction frameworks method the reconstruction duties utilizing the form from shading method, with texture and defocus serving as unique views for the reconstruction duties. Since these strategies use a single depth cue, they’re able to offering reasoning for the seen elements of a floor. Moreover, a variety of single-view 3D reconstruction frameworks use a number of cues together with structural data for estimating depth from a single monocular picture, a mix that permits these frameworks to foretell the depth of the seen surfaces. More moderen depth estimation frameworks deploy convolutional neural community constructions to extract depth in a monocular picture.
Nonetheless, for efficient single-view 3D reconstruction, fashions not solely should motive in regards to the 3D construction of the seen objects within the picture, however additionally they have to hallucinate the invisible elements within the picture utilizing sure priors discovered from the information. To realize this, a majority of fashions at the moment deploy skilled convolutional neural community constructions to map 2D photos into 3D shapes utilizing direct 3D supervision, whereas a variety of different frameworks deployed a voxel-based representations of 3D form, and used a latent illustration to to generate 3D up-convolutions. Sure frameworks additionally partition the output house hierarchically to reinforce computational and reminiscence effectivity that permits the mannequin to foretell higher-resolution 3D shapes. Current analysis is specializing in utilizing weaker types of supervision for single-view 3D form predictions utilizing convolutional neural networks, both evaluating predicted shapes and their ground-truth predictions to coach form regressors or utilizing a number of studying indicators to coach imply shapes that helps the mannequin predict deformations. One more reason behind the restricted developments in single-view 3D reconstruction is the restricted quantity of coaching knowledge accessible for the duty.
Shifting alongside, single view 3D reconstruction is a posh process because it not solely interprets visible knowledge geometrically, but additionally semantically. Though they don’t seem to be utterly completely different, they do span completely different spectrums from geometric reconstruction to semantic recognition. Reconstruction duties per-pixel reasoning of the 3D construction of the thing within the picture. Reconstruction duties don’t require semantic understanding of the content material of the picture, and it may be achieved utilizing low-level picture cues together with texture, coloration, shading, shadows, perspective, and focus. Recognition then again is an excessive case of utilizing picture semantics as a result of recognition duties use entire objects and quantities to categorise the thing within the enter, and retrieve the corresponding form from the database. Though recognition duties can present strong reasoning in regards to the elements of the thing not seen within the photos, the semantic resolution is possible provided that it may be defined by an object current within the database.
Though recognition and reconstruction duties may differ from each other considerably, they each are inclined to ignore useful data contained within the enter picture. It’s advisable to make use of each these duties in unison with each other to acquire the absolute best outcomes, and correct 3D shapes for object reconstruction i.e. for optimum single-view 3D reconstruction duties, the mannequin ought to make use of structural data, low-level picture cues, and high-level understanding of the thing.
Single-View 3D Reconstruction : Standard Setup
To elucidate the traditional setup and analyze the setup of a single-view 3D reconstruction framework, we’ll deploy a typical setup for estimating the 3D form utilizing a single view or picture of the thing. The dataset used for coaching functions is the ShapeNet dataset, and evaluates the efficiency throughout 13 courses that permits the mannequin to know how the variety of courses in a dataset determines the form estimation efficiency of the mannequin.
A majority of contemporary convolutional neural networks use a single picture to foretell high-resolution 3D fashions, and these frameworks could be categorized on the idea of the illustration of their output: depth maps, level clouds, and voxel grids. The mannequin makes use of OGN or Octree Producing Networks as its consultant methodology that traditionally has outperformed the voxel grid method, and/or can cowl the dominant output representations. In distinction with present strategies that make the most of output representations, the OGN method permits the mannequin to foretell high-resolution shapes, and makes use of octrees to effectively symbolize the occupied house.
Baselines
To judge the outcomes, the mannequin deploys two baselines that take into account the issue purely as a recognition process. The primary baseline is predicated on clustering whereas the second baseline performs database retrieval.
Clustering
The the clustering baseline, the mannequin makes use of the Ok-Means algorithm to cluster or bunch the coaching shapes in Ok sub-categories, and runs the algorithm on 32*32*32 voxelizations flattened right into a vector. After figuring out the cluster assignments, the mannequin switches again to working with fashions with larger decision. The mannequin then calculates the imply form inside every cluster, and thresholds the imply shapes the place the optimum worth is calculated by maximizing the common IoU or Intersection over Union over the fashions. For the reason that mannequin is aware of the relation between the 3D shapes and the photographs throughout the coaching knowledge, the mannequin can readily match the picture with its corresponding cluster.
Retrieval
The retrieval baseline learns to embed shapes and pictures in a joint house. The mannequin considers the pairwise similarity of 3D matrix shapes within the coaching set to assemble the embedding house. The mannequin achieves this through the use of the Multi-Dimensional Scaling with Sammon mapping method to compress every row within the matrix to a low-dimensional descriptor. Moreover, to calculate the similarity between two arbitrary shapes, the mannequin employs the sunshine subject descriptor. Moreover, the mannequin trains a convolutional neural community to map photos to a descriptor to embed the photographs within the house.
Evaluation
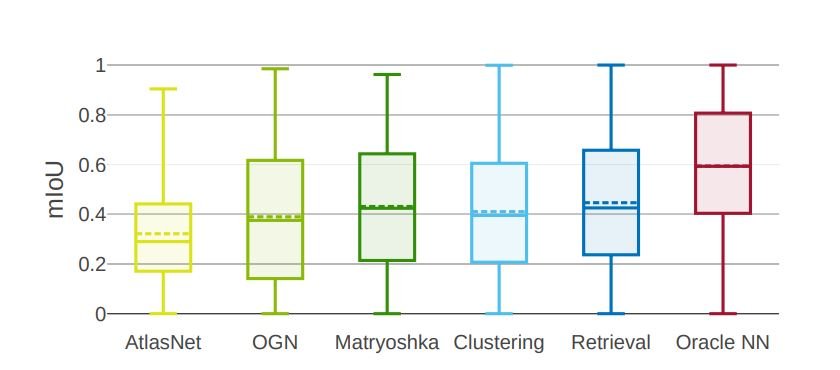
Single-view 3D reconstruction fashions comply with completely different methods because of which they outperform different fashions in some areas whereas they fall brief in others. To match completely different frameworks, and consider their efficiency, now we have completely different metrics, certainly one of them being the imply IoU rating.

As it may be seen within the above picture, regardless of having completely different architectures, present cutting-edge 3D reconstruction fashions ship virtually related efficiency. Nonetheless, it’s attention-grabbing to notice that regardless of being a pure recognition methodology, the retrieval framework outperforms different fashions when it comes to imply and median IoU scores. The Clustering framework delivers stable outcomes outperforming the AtlasNet, the OGN and the Matryoshka frameworks. Nonetheless, probably the most sudden final result of this evaluation stays Oracle NN outperforming all different strategies regardless of using an ideal retrieval structure. Though calculating the imply IoU rating does assist in the comparability, it doesn’t present a full image because the variance in outcomes is excessive regardless of the mannequin.
Widespread Analysis Metrics
Single-View 3D Reconstruction fashions usually make use of completely different analysis metrics to investigate their efficiency on a variety of duties. Following are a few of the generally used analysis metrics.
Intersection Over Union
The Imply of Intersection Over Union is a metric generally used as a quantitative measure to function a benchmark for single-view 3D reconstruction fashions. Though IoU does present some perception into the mannequin’s efficiency, it isn’t thought of as the only real metric to guage a way because it signifies the standard of the form predicted by the mannequin provided that the values are sufficiently excessive with a big discrepancy being noticed between the low and mid-range scores for 2 given shapes.
Chamfer Distance
Chamfer Distance is outlined on level clouds, and it has been designed in a manner that it may be utilized to completely different 3D representations satisfactorily. Nonetheless, the Chamfer Distance analysis metric is very delicate to outliers that makes it a problematic measure to guage the mannequin’s efficiency, with the gap of the outlier from the reference form considerably figuring out the technology high quality.
F-Rating
The F-Rating is a standard analysis metric actively utilized by a majority of multi-view 3D reconstruction fashions. The F-Rating metric is outlined because the harmonic imply between recall & precision, and it evaluates the gap between the surfaces of the objects explicitly. Precision counts the share of reconstructed factors mendacity inside a predefined distance to the bottom fact, to measure the accuracy of the reconstruction. Recall then again counts the share of factors on the bottom fact mendacity inside a predefined distance to the reconstruction to measure the completeness of the reconstruction. Moreover, by various the gap threshold, builders can management the strictness of the F-Rating metric.
Per-Class Evaluation
The similarity in efficiency delivered by the above frameworks can’t be a results of strategies operating on completely different subset of courses, and the next determine demonstrates the constant relative efficiency throughout completely different courses with the Oracle NN retrieval baseline reaching one of the best end result of all of them, and all strategies observing excessive variance for all courses.

Moreover, the variety of coaching samples accessible for a category may lead one to imagine it influences the per-class efficiency. Nonetheless, as demonstrated within the following determine, the variety of coaching samples accessible for a category doesn’t affect the per-class efficiency, and the variety of samples in a category and its imply IoU rating should not correlated.

Qualitative Evaluation
The quantitative outcomes mentioned within the part above are backed by qualitative outcomes as proven within the following picture.

For a majority of courses, there isn’t any important distinction between the clustering baseline and the predictions made by decoder-based strategies. The Clustering method fails to ship outcomes when the gap between the pattern and the imply cluster form is excessive, or in conditions when the imply form itself can not describe the cluster properly sufficient. Alternatively, frameworks using decoder-based strategies and retrieval structure ship probably the most correct and interesting outcomes since they’re able to embrace wonderful particulars within the generated 3D mannequin.
Single View 3D Reconstruction : Remaining Ideas
On this article, now we have talked about Single View 3D Object Reconstruction, and talked about the way it works, and talked about two baselines: Retrieval and Classification, with the retrieval baseline method outperforming present cutting-edge fashions. Lastly, though Single View 3D Object Reconstruction is likely one of the hottest subjects and most researched subjects within the AI neighborhood, and regardless of making important advances prior to now few years, Single View 3D Object Reconstruction is much from being excellent with important roadblocks to beat within the upcoming years.