Within the quickly advancing discipline of huge language fashions (LLMs), a brand new highly effective mannequin has emerged – DBRX, an open source model created by Databricks. This LLM is making waves with its state-of-the-art efficiency throughout a variety of benchmarks, even rivaling the capabilities of business giants like OpenAI’s GPT-4.
DBRX represents a big milestone within the democratization of synthetic intelligence, offering researchers, builders, and enterprises with open entry to a top-tier language mannequin. However what precisely is DBRX, and what makes it so particular? On this technical deep dive, we’ll discover the revolutionary structure, coaching course of, and key capabilities which have propelled DBRX to the forefront of the open LLM panorama.
The Delivery of DBRX The creation of DBRX was pushed by Databricks’ mission to make knowledge intelligence accessible to all enterprises. As a pacesetter in knowledge analytics platforms, Databricks acknowledged the immense potential of LLMs and got down to develop a mannequin that would match and even surpass the efficiency of proprietary choices.
After months of intensive analysis, growth, and a multi-million greenback funding, the Databricks crew achieved a breakthrough with DBRX. The mannequin’s spectacular efficiency on a variety of benchmarks, together with language understanding, programming, and arithmetic, firmly established it as a brand new state-of-the-art in open LLMs.
Modern Structure
The Energy of Combination-of-Specialists On the core of DBRX’s distinctive efficiency lies its revolutionary mixture-of-experts (MoE) structure. This cutting-edge design represents a departure from conventional dense fashions, adopting a sparse strategy that enhances each pretraining effectivity and inference pace.
Within the MoE framework, solely a choose group of elements, referred to as “specialists,” are activated for every enter. This specialization permits the mannequin to sort out a broader array of duties with larger adeptness, whereas additionally optimizing computational assets.
DBRX takes this idea even additional with its fine-grained MoE structure. Not like another MoE fashions that use a smaller variety of bigger specialists, DBRX employs 16 specialists, with 4 specialists lively for any given enter. This design gives a staggering 65 occasions extra doable skilled combos, straight contributing to DBRX’s superior efficiency.
DBRX differentiates itself with a number of revolutionary options:
- Rotary Place Encodings (RoPE): Enhances understanding of token positions, essential for producing contextually correct textual content.
- Gated Linear Models (GLU): Introduces a gating mechanism that enhances the mannequin’s capacity to be taught advanced patterns extra effectively.
- Grouped Question Consideration (GQA): Improves the mannequin’s effectivity by optimizing the eye mechanism.
- Superior Tokenization: Makes use of GPT-4’s tokenizer to course of inputs extra successfully.
The MoE structure is especially well-suited for large-scale language fashions, because it permits for extra environment friendly scaling and higher utilization of computational assets. By distributing the educational course of throughout a number of specialised subnetworks, DBRX can successfully allocate knowledge and computational energy for every process, guaranteeing each high-quality output and optimum effectivity.
Intensive Coaching Knowledge and Environment friendly Optimization Whereas DBRX’s structure is undoubtedly spectacular, its true energy lies within the meticulous coaching course of and the huge quantity of knowledge it was uncovered to. DBRX was pretrained on an astounding 12 trillion tokens of textual content and code knowledge, rigorously curated to make sure top quality and variety.
The coaching knowledge was processed utilizing Databricks’ suite of instruments, together with Apache Spark for knowledge processing, Unity Catalog for knowledge administration and governance, and MLflow for experiment monitoring. This complete toolset allowed the Databricks crew to successfully handle, discover, and refine the huge dataset, laying the inspiration for DBRX’s distinctive efficiency.
To additional improve the mannequin’s capabilities, Databricks employed a dynamic pretraining curriculum, innovatively various the info combine throughout coaching. This technique allowed every token to be successfully processed utilizing the lively 36 billion parameters, leading to a extra well-rounded and adaptable mannequin.
Furthermore, DBRX’s coaching course of was optimized for effectivity, leveraging Databricks’ suite of proprietary instruments and libraries, together with Composer, LLM Foundry, MegaBlocks, and Streaming. By using strategies like curriculum studying and optimized optimization methods, the crew achieved almost a four-fold enchancment in compute effectivity in comparison with their earlier fashions.
Coaching and Structure
DBRX was skilled utilizing a next-token prediction mannequin on a colossal dataset of 12 trillion tokens, emphasizing each textual content and code. This coaching set is believed to be considerably more practical than these utilized in prior fashions, guaranteeing a wealthy understanding and response functionality throughout different prompts.
DBRX’s structure just isn’t solely a testomony to Databricks’ technical prowess but in addition highlights its software throughout a number of sectors. From enhancing chatbot interactions to powering advanced knowledge evaluation duties, DBRX could be built-in into numerous fields requiring nuanced language understanding.
Remarkably, DBRX Instruct even rivals a few of the most superior closed fashions available on the market. In keeping with Databricks’ measurements, it surpasses GPT-3.5 and is aggressive with Gemini 1.0 Professional and Mistral Medium throughout numerous benchmarks, together with common information, commonsense reasoning, programming, and mathematical reasoning.
As an illustration, on the MMLU benchmark, which measures language understanding, DBRX Instruct achieved a rating of 73.7%, outperforming GPT-3.5’s reported rating of 70.0%. On the HellaSwag commonsense reasoning benchmark, DBRX Instruct scored a powerful 89.0%, surpassing GPT-3.5’s 85.5%.
DBRX Instruct really shines, reaching a exceptional 70.1% accuracy on the HumanEval benchmark, outperforming not solely GPT-3.5 (48.1%) but in addition the specialised CodeLLaMA-70B Instruct mannequin (67.8%).
These distinctive outcomes spotlight DBRX’s versatility and its capacity to excel throughout a various vary of duties, from pure language understanding to advanced programming and mathematical problem-solving.
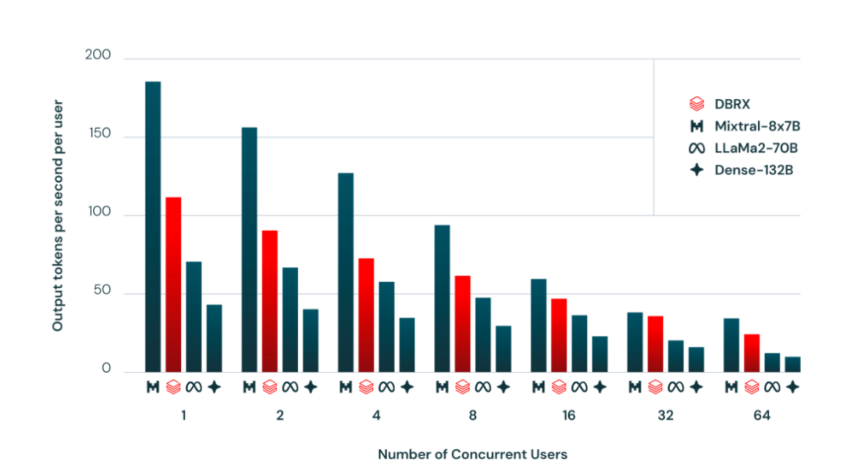
Environment friendly Inference and Scalability One of many key benefits of DBRX’s MoE structure is its effectivity throughout inference. Due to the sparse activation of parameters, DBRX can obtain inference throughput that’s as much as two to a few occasions quicker than dense fashions with the identical complete parameter depend.
In comparison with LLaMA2-70B, a well-liked open supply LLM, DBRX not solely demonstrates greater high quality but in addition boasts almost double the inference pace, regardless of having about half as many lively parameters. This effectivity makes DBRX a lovely selection for deployment in a variety of purposes, from content material creation to knowledge evaluation and past.
Furthermore, Databricks has developed a sturdy coaching stack that enables enterprises to coach their very own DBRX-class fashions from scratch or proceed coaching on prime of the offered checkpoints. This functionality empowers companies to leverage the complete potential of DBRX and tailor it to their particular wants, additional democratizing entry to cutting-edge LLM expertise.
Databricks’ growth of the DBRX mannequin marks a big development within the discipline of machine studying, notably by means of its utilization of revolutionary instruments from the open-source neighborhood. This growth journey is considerably influenced by two pivotal applied sciences: the MegaBlocks library and PyTorch’s Absolutely Sharded Knowledge Parallel (FSDP) system.
MegaBlocks: Enhancing MoE Effectivity
The MegaBlocks library addresses the challenges related to the dynamic routing in Combination-of-Specialists (MoEs) layers, a typical hurdle in scaling neural networks. Conventional frameworks usually impose limitations that both scale back mannequin effectivity or compromise on mannequin high quality. MegaBlocks, nonetheless, redefines MoE computation by means of block-sparse operations that adeptly handle the intrinsic dynamism inside MoEs, thus avoiding these compromises.
This strategy not solely preserves token integrity but in addition aligns nicely with fashionable GPU capabilities, facilitating as much as 40% quicker coaching occasions in comparison with conventional strategies. Such effectivity is essential for the coaching of fashions like DBRX, which rely closely on superior MoE architectures to handle their intensive parameter units effectively.
PyTorch FSDP: Scaling Massive Fashions
PyTorch’s Fully Sharded Data Parallel (FSDP) presents a sturdy resolution for coaching exceptionally massive fashions by optimizing parameter sharding and distribution throughout a number of computing units. Co-designed with key PyTorch elements, FSDP integrates seamlessly, providing an intuitive person expertise akin to native coaching setups however on a a lot bigger scale.
FSDP’s design cleverly addresses a number of vital points:
- Person Expertise: It simplifies the person interface, regardless of the advanced backend processes, making it extra accessible for broader utilization.
- {Hardware} Heterogeneity: It adapts to different {hardware} environments to optimize useful resource utilization effectively.
- Useful resource Utilization and Reminiscence Planning: FSDP enhances the utilization of computational assets whereas minimizing reminiscence overheads, which is crucial for coaching fashions that function on the scale of DBRX.
FSDP not solely helps bigger fashions than beforehand doable underneath the Distributed Knowledge Parallel framework but in addition maintains near-linear scalability when it comes to throughput and effectivity. This functionality has confirmed important for Databricks’ DBRX, permitting it to scale throughout a number of GPUs whereas managing its huge variety of parameters successfully.
Accessibility and Integrations
In keeping with its mission to advertise open entry to AI, Databricks has made DBRX obtainable by means of a number of channels. The weights of each the bottom mannequin (DBRX Base) and the finetuned mannequin (DBRX Instruct) are hosted on the favored Hugging Face platform, permitting researchers and builders to simply obtain and work with the mannequin.
Moreover, the DBRX model repository is on the market on GitHub, offering transparency and enabling additional exploration and customization of the mannequin’s code.

For Databricks prospects, DBRX Base and DBRX Instruct are conveniently accessible by way of the Databricks Basis Mannequin APIs, enabling seamless integration into current workflows and purposes. This not solely simplifies the deployment course of but in addition ensures knowledge governance and safety for delicate use circumstances.
Moreover, DBRX has already been built-in into a number of third-party platforms and providers, corresponding to You.com and Perplexity Labs, increasing its attain and potential purposes. These integrations show the rising curiosity in DBRX and its capabilities, in addition to the growing adoption of open LLMs throughout numerous industries and use circumstances.
Lengthy-Context Capabilities and Retrieval Augmented Technology One of many standout options of DBRX is its capacity to deal with long-context inputs, with a most context size of 32,768 tokens. This functionality permits the mannequin to course of and generate textual content primarily based on intensive contextual info, making it well-suited for duties corresponding to doc summarization, query answering, and data retrieval.
In benchmarks evaluating long-context efficiency, corresponding to KV-Pairs and HotpotQAXL, DBRX Instruct outperformed GPT-3.5 Turbo throughout numerous sequence lengths and context positions.

DBRX outperforms established open supply fashions on language understanding (MMLU), Programming (HumanEval), and Math (GSM8K).
Limitations and Future Work
Whereas DBRX represents a big achievement within the discipline of open LLMs, it’s important to acknowledge its limitations and areas for future enchancment. Like several AI mannequin, DBRX could produce inaccurate or biased responses, relying on the standard and variety of its coaching knowledge.
Moreover, whereas DBRX excels at general-purpose duties, sure domain-specific purposes could require additional fine-tuning or specialised coaching to realize optimum efficiency. As an illustration, in situations the place accuracy and constancy are of utmost significance, Databricks recommends utilizing retrieval augmented era (RAG) strategies to reinforce the mannequin’s output.
Moreover, DBRX’s present coaching dataset primarily consists of English language content material, probably limiting its efficiency on non-English duties. Future iterations of the mannequin could contain increasing the coaching knowledge to incorporate a extra numerous vary of languages and cultural contexts.
Databricks is dedicated to constantly enhancing DBRX’s capabilities and addressing its limitations. Future work will concentrate on bettering the mannequin’s efficiency, scalability, and value throughout numerous purposes and use circumstances, in addition to exploring strategies to mitigate potential biases and promote moral AI use.
Moreover, the corporate plans to additional refine the coaching course of, leveraging superior strategies corresponding to federated studying and privacy-preserving strategies to make sure knowledge privateness and safety.
The Highway Forward
DBRX represents a big step ahead within the democratization of AI growth. It envisions a future the place each enterprise has the flexibility to manage its knowledge and its future within the rising world of generative AI.
By open-sourcing DBRX and offering entry to the identical instruments and infrastructure used to construct it, Databricks is empowering companies and researchers to develop their very own cutting-edge Databricks tailor-made to their particular wants.
By the Databricks platform, prospects can leverage the corporate’s suite of knowledge processing instruments, together with Apache Spark, Unity Catalog, and MLflow, to curate and handle their coaching knowledge. They’ll then make the most of Databricks’ optimized coaching libraries, corresponding to Composer, LLM Foundry, MegaBlocks, and Streaming, to coach their very own DBRX-class fashions effectively and at scale.
This democratization of AI growth has the potential to unlock a brand new wave of innovation, as enterprises acquire the flexibility to harness the facility of huge language fashions for a variety of purposes, from content material creation and knowledge evaluation to determination help and past.
Furthermore, by fostering an open and collaborative ecosystem round DBRX, Databricks goals to speed up the tempo of analysis and growth within the discipline of huge language fashions. As extra organizations and people contribute their experience and insights, the collective information and understanding of those highly effective AI methods will proceed to develop, paving the best way for much more superior and succesful fashions sooner or later.
Conclusion
DBRX is a game-changer on the earth of open supply massive language fashions. With its revolutionary mixture-of-experts structure, intensive coaching knowledge, and state-of-the-art efficiency, it has set a brand new benchmark for what is feasible with open LLMs.
By democratizing entry to cutting-edge AI expertise, DBRX empowers researchers, builders, and enterprises to discover new frontiers in pure language processing, content material creation, knowledge evaluation, and past. As Databricks continues to refine and improve DBRX, the potential purposes and impression of this highly effective mannequin are really limitless.